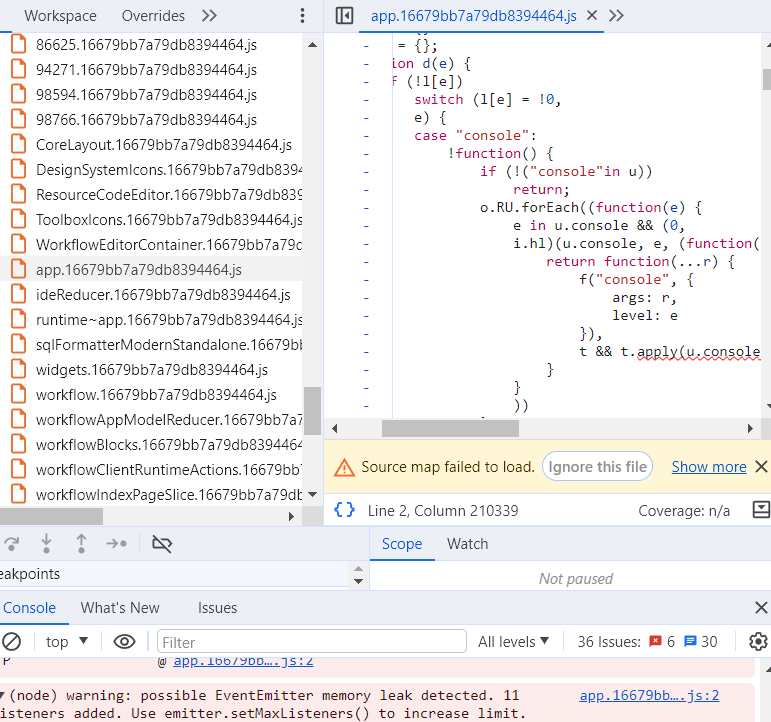
it gets weirder imo lol.
click and drag the Resource Query and drop it in, but don't connect it to anything. do this 3 more times so you have 4 total (where it starts dropping that error). notice this time it didn't show up. refresh the page.... now the error shows. hit the back button to navigate back to the workflow page, then click to edit the same workflow. no error. refresh again though, there's the error.
I went back and made a new workflow then followed your video. if you don't refresh at any point, the error never shows up. the second you hit refresh though, you'll see that error. to make it go away, I've found the only thing to do is hit the back button then forward (or just cick the workflow again).
So What's Going On?
since addEventListener is used, not reacts onEventName prop stuff, a wild guess would be that somewhere there is a componentDidMount(), that adds event listeners, who's matching componentWillUnmount() is missing a removeEventListener. if the element/object isn't actually destroyed from a page refresh after not using removeEventListener, then when componentDidMount() gets called again this problem could occur. a page navigation would def destroy the element and the JS Environment..... with React though, a page Refresh isn't necessarily the same as a page Reload. the page reload will always destroy the JS env and components, but with a refresh it's possible to persist the state even after the refresh. this is the only thing i can think of that's going on and it's the only thing I can think of as to why the listeners are destroyed on naviagation but not on refresh (especially since w just plain JS a page refresh would always destroy the env and components, so the only difference has to be w how react works)
Edit:
it's rather difficult to figure out what the code is for, but i can make another guess based off of the other switch cases: console, dom, xhr, fetch, history, error, unhandledrejection. It's the 'console' and 'history' that give hints. the normal console, and the whole browser dev window doesn't have anything named history, logs sure, but not history.... so it's not the dev window console being referred to for redirecting output. there is somewhere else with both a console and somewhere w a history label.... and even an area for xhr/fetch results. its the run history window. it would need all of those switch cases. also, convienetly, it would be nice if that window persisted state between refreshes.... oh what do you know, it does lol.
hopefully this helps you @ehe or whoever ends up trying to fix this