Hi everyone! Following up here again to announce some additional table features. We've added:
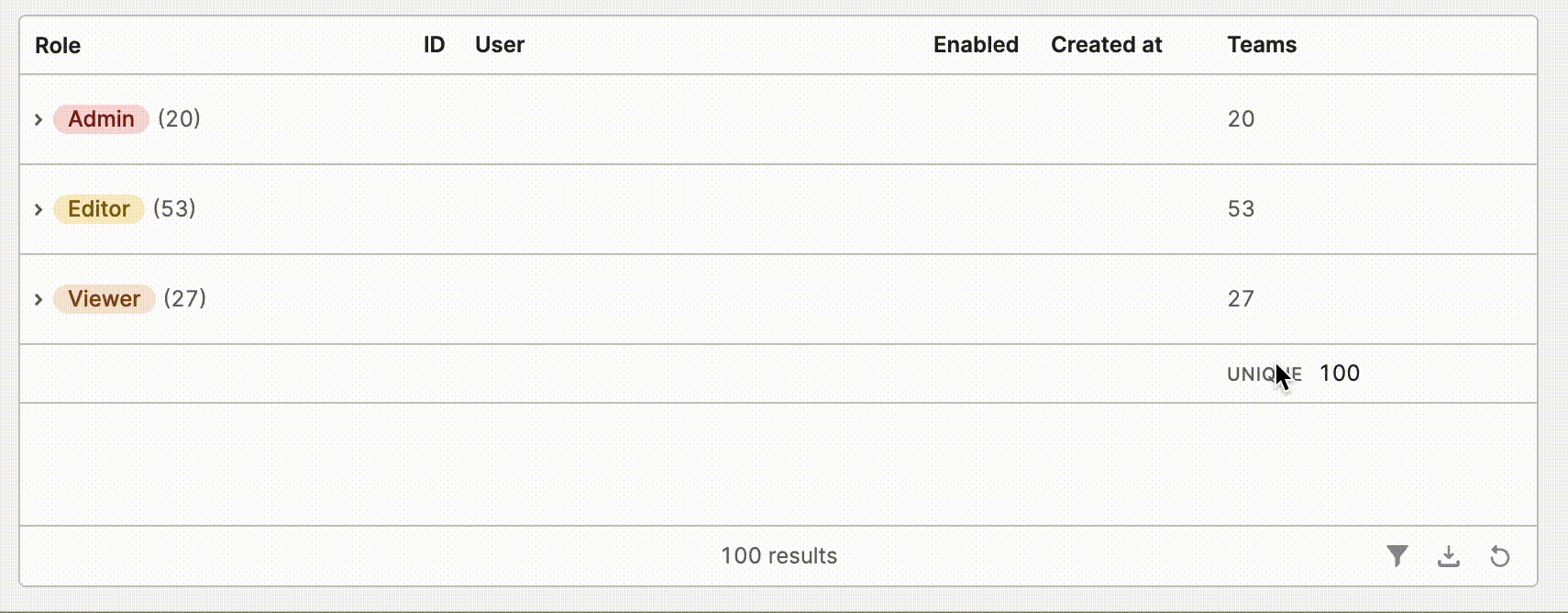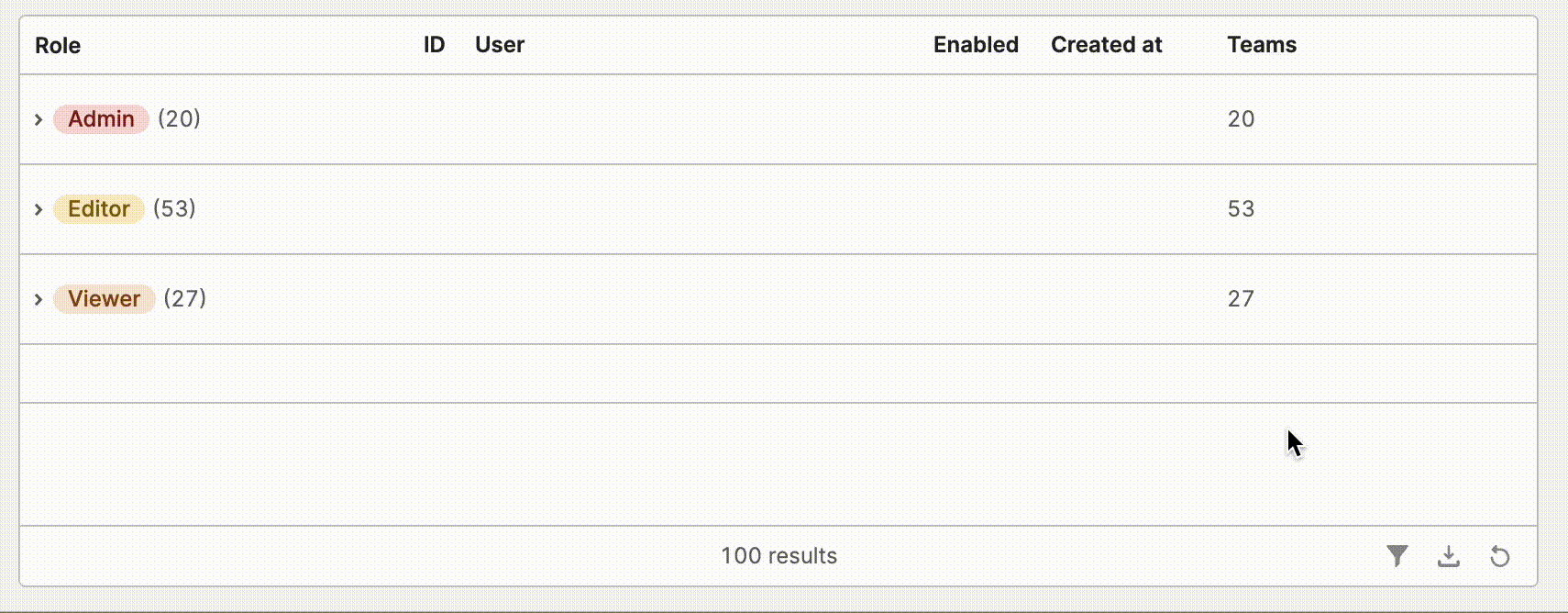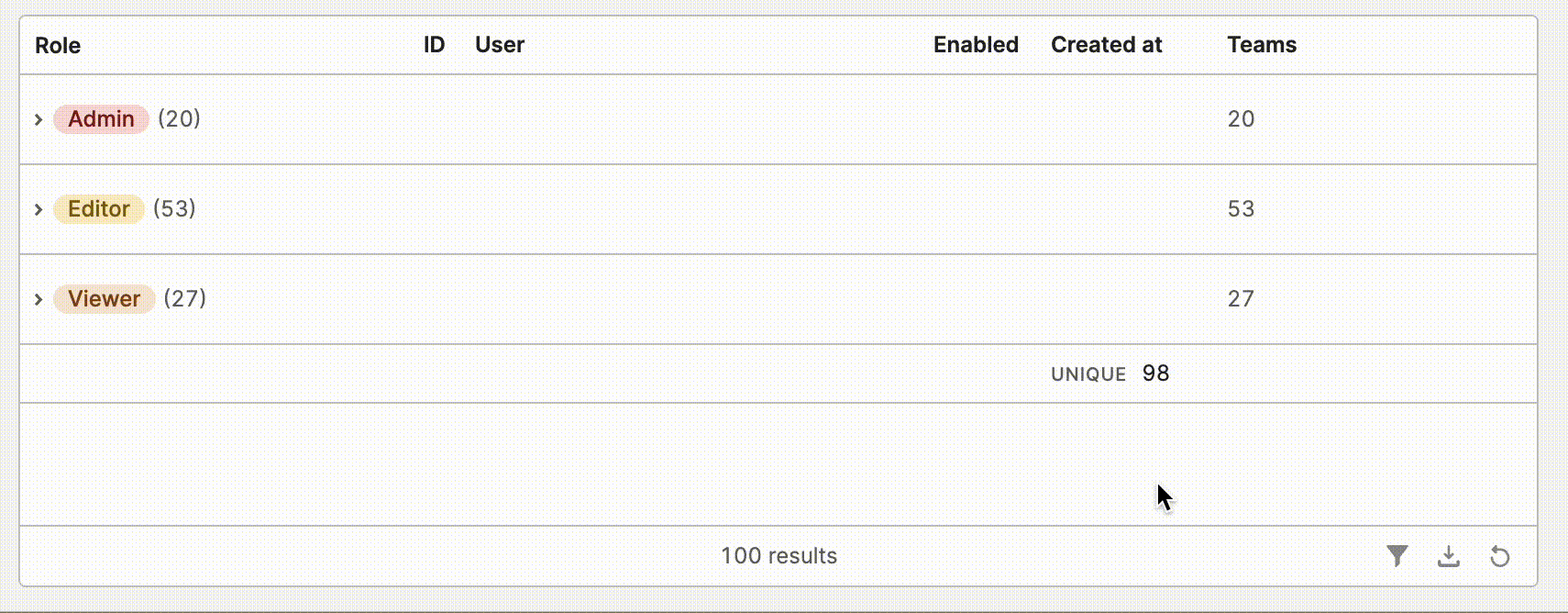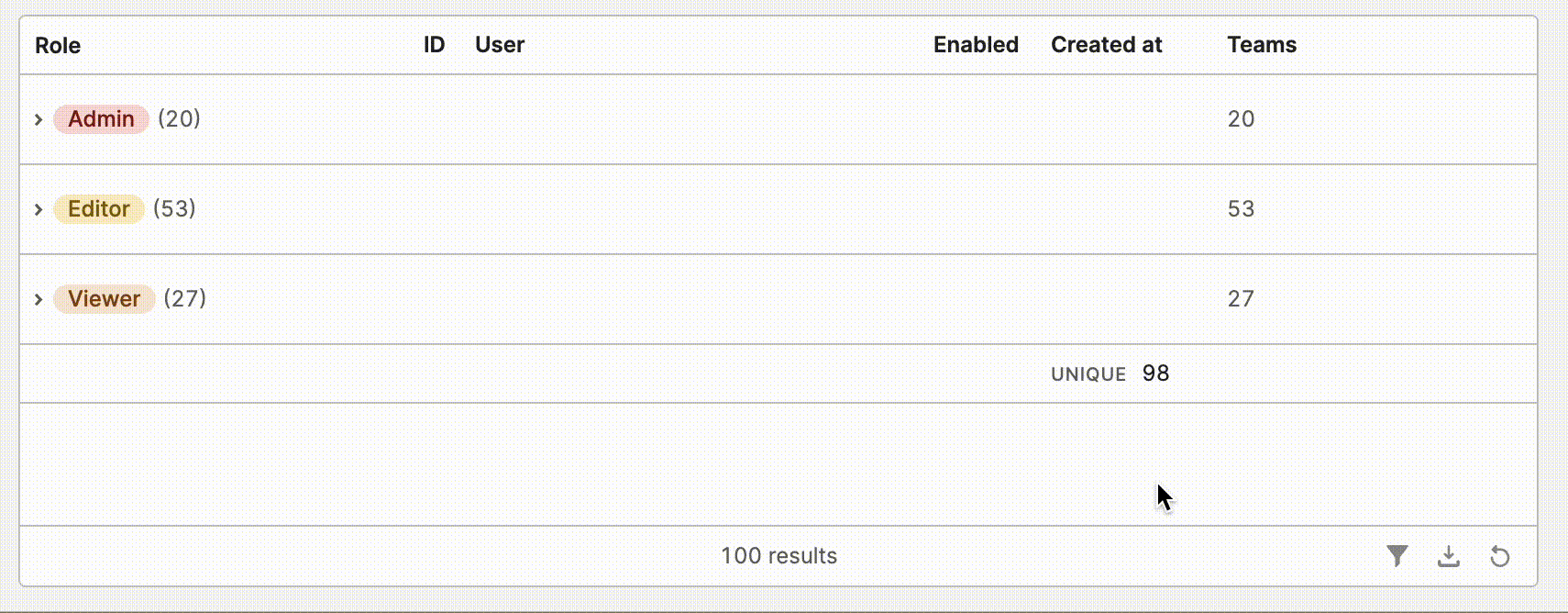
- Aggregation cells can now be rendered in grouped rows! While editing a column, you can select your desired column using the
Aggregationoption.
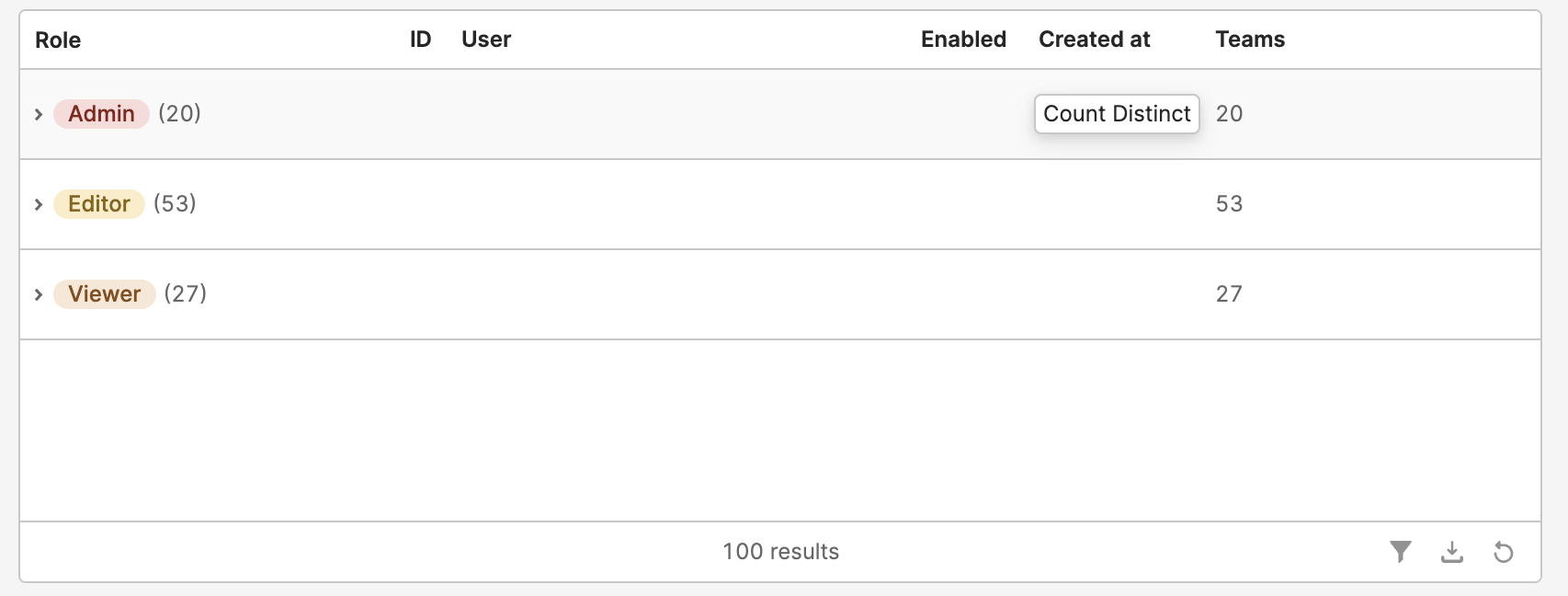
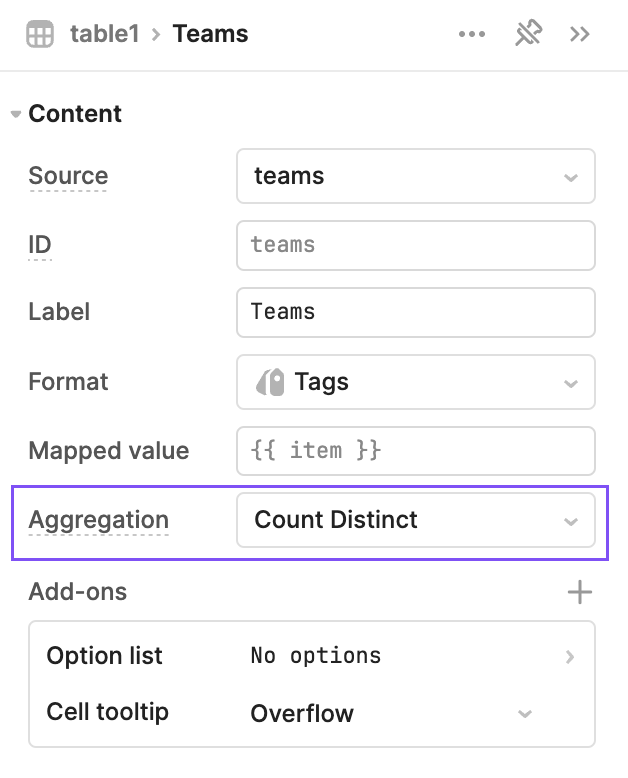
- You can also enable a summary row in via Table add ons and configure default options for each column by clicking the add on editor. End users will be able to toggle desired aggregations from the summary row component itself.