I had a workflow time out on me and then shortly after it appeared my self-hosted retool went down (accessing the URL was giving me "site can't be reached."
So I restarted the EC2 instance and started up retool from the console.
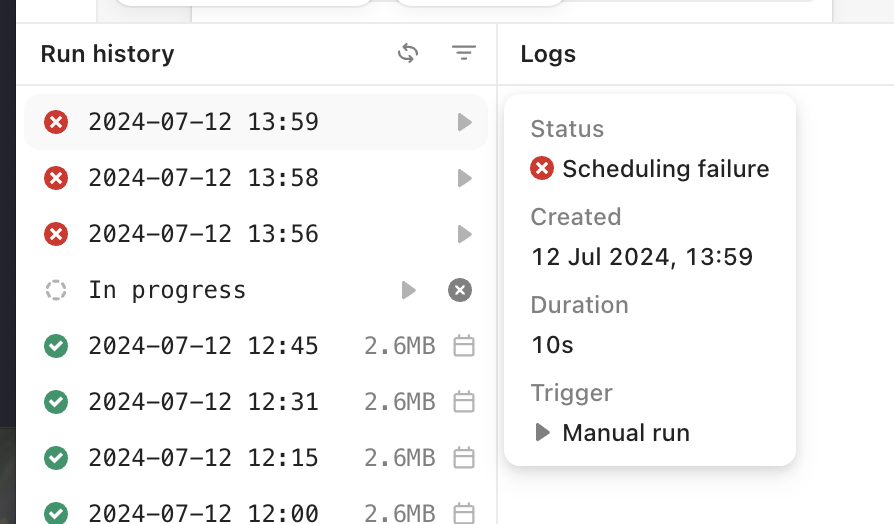
None of my workflows will run now. They all fail with status "Scheduling failure"
The original trouble workflow run history looks like this too:
Anybody ever run into this?
1 Like
Hey @Cam_Szarapka Can you confirm that all of your Retool containers are up and healthy? It seems possible that one or several the Workflows containers did not startup back up again as expected.
Separately, do you see any errors in your container logs from before the crash or any exit codes on your containers indicating why the instance crashed in the first place?
Hey Everett, thanks for getting back so quick!
I'm out of my breadth here so not 100% sure how to do what you're asking
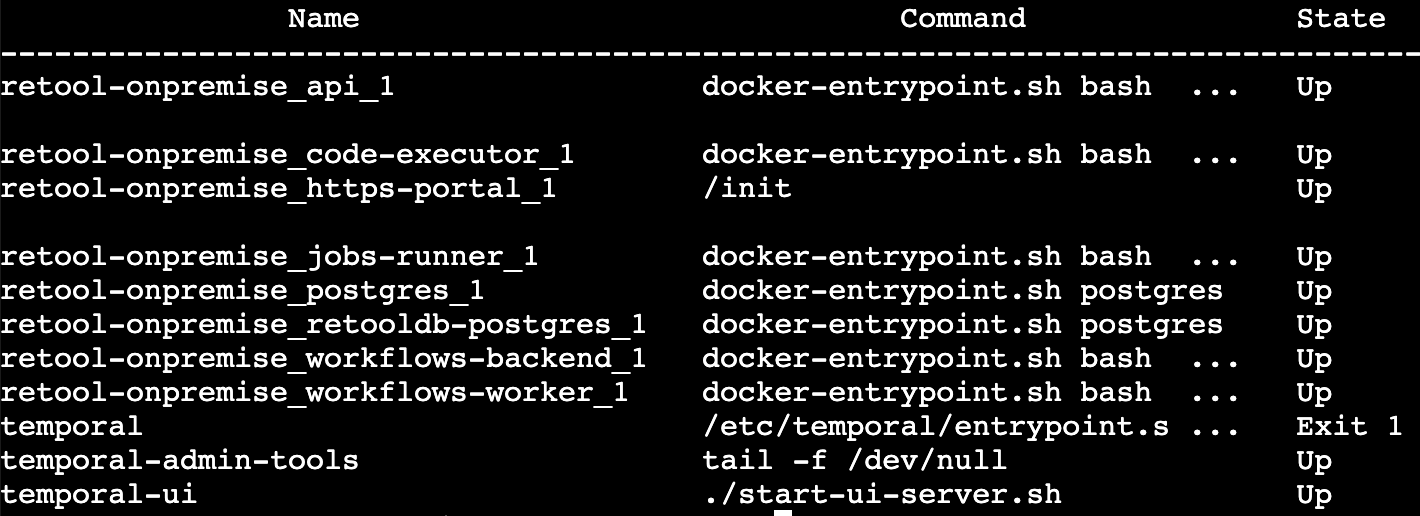
Here's what I see in the AWS connect terminal:
Ah, that's helpful to see. Your temporal container is down—it's State is Exit 1—which explains why you're seeing scheduling errors. Can you try to start up the temporal container up again with sudo docker-compose up -d temporal and monitor the container logs for any errors?
Separately, can you check the CPU and Memory metrics on the VM hosting this deployment to see if the Retool instance is resource constrained?
1 Like
That fixed it! I'm not sure how to see the memory and CPU metrics in AWS but it does say we're overprovisioned. We're on a t3.xlarge
Thanks for the help Everett!
3 Likes