Summary of info in the bottom
I would expect the workflow worker to start and operate smoothly, but it keeps restarting and spitting out errors that dont make much sense to me.
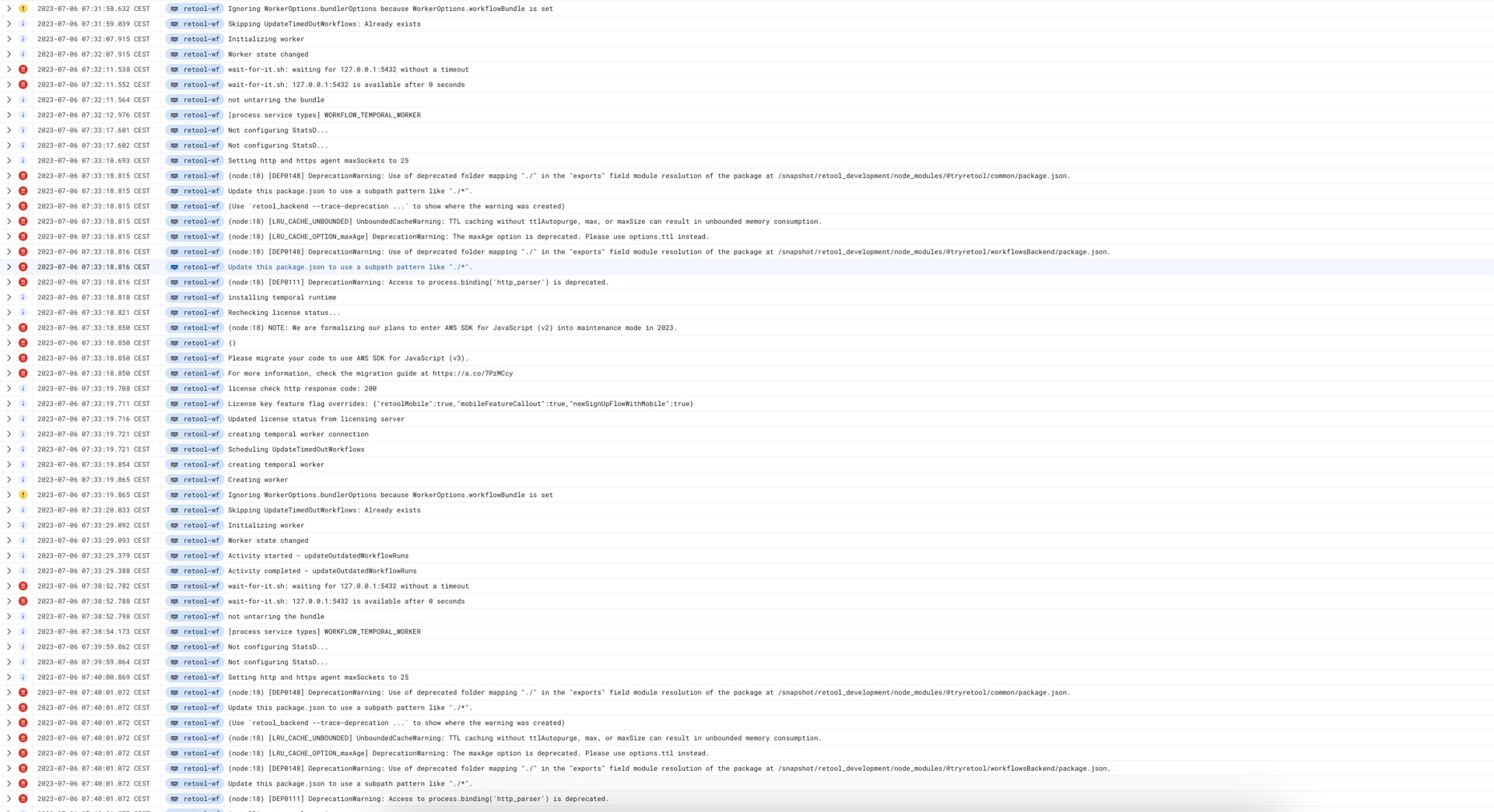
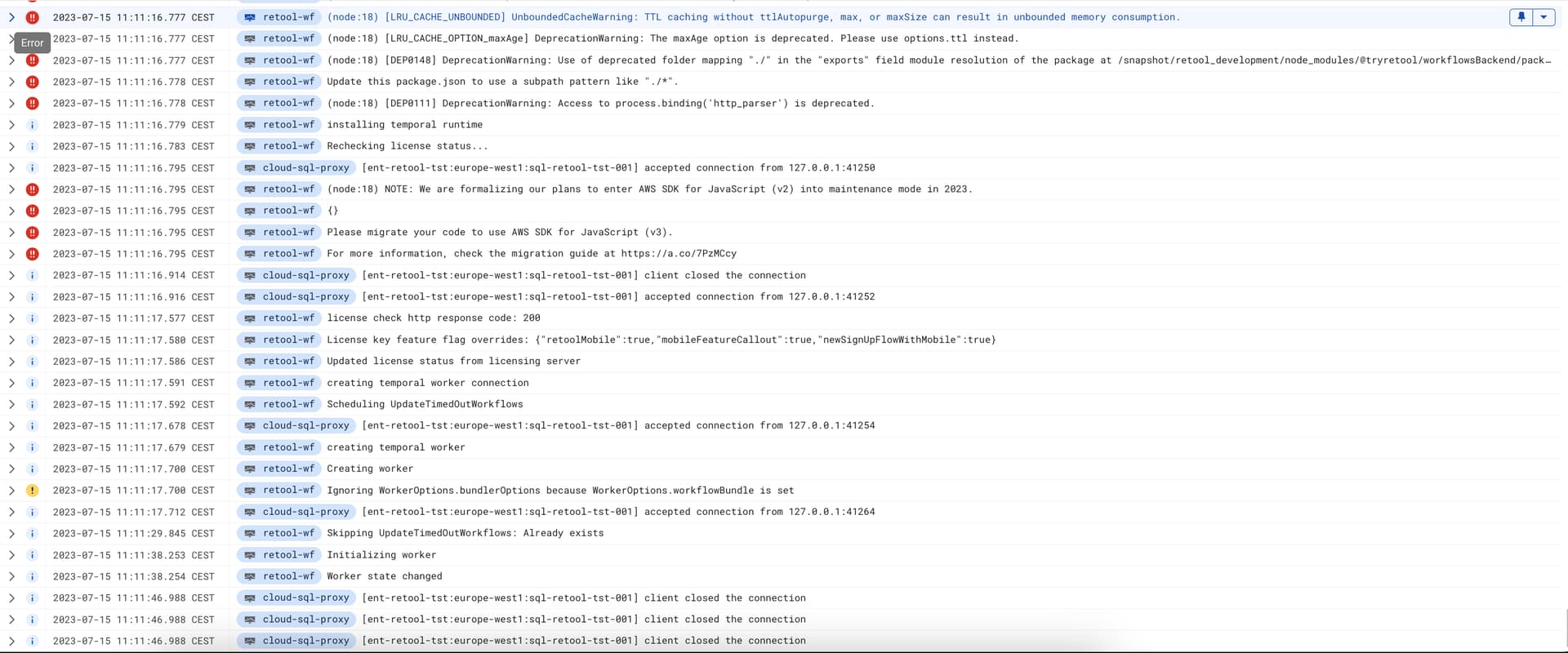
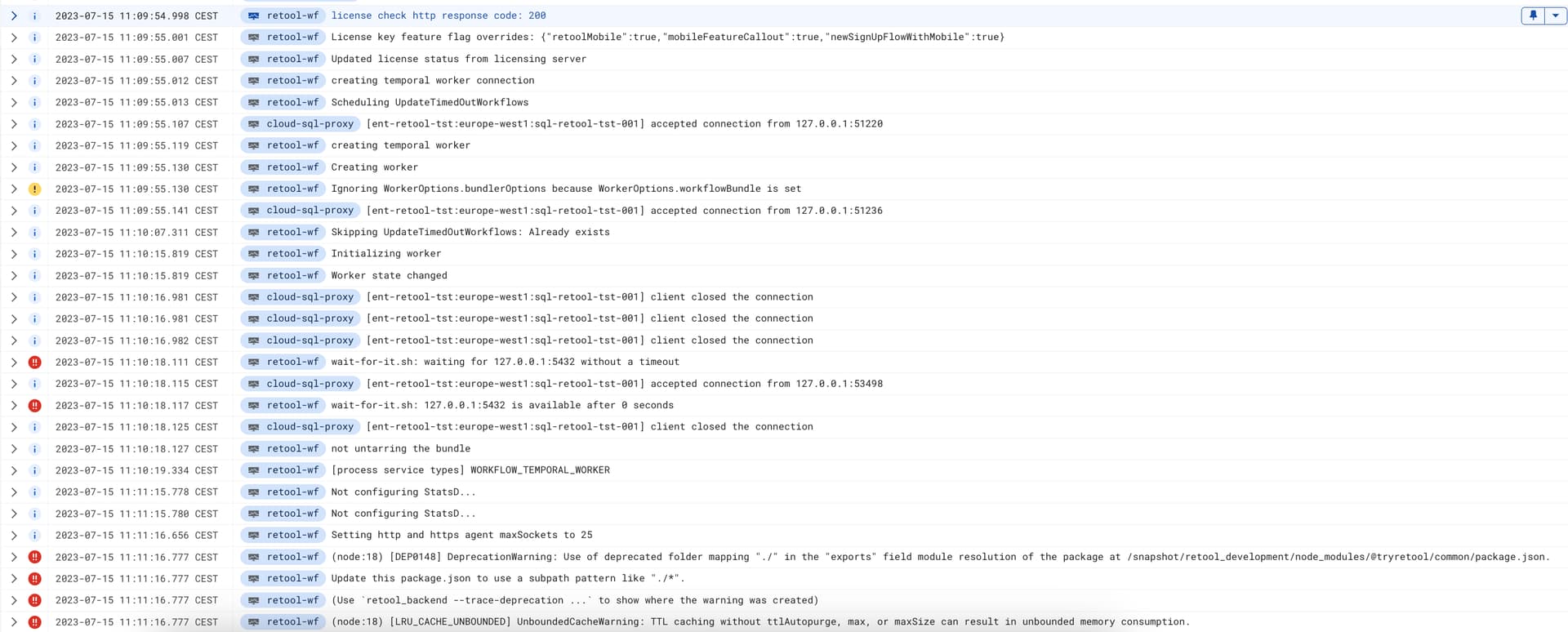
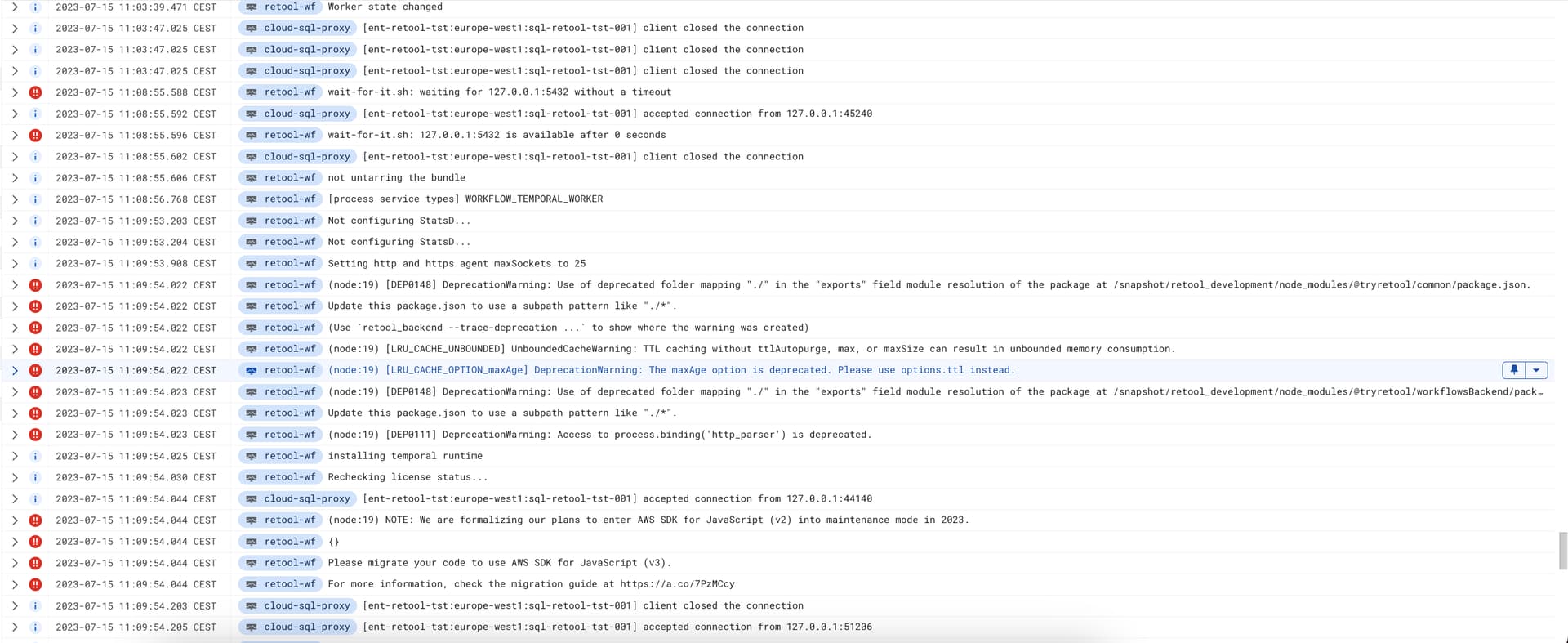
Here is an upload of the log, I hope you can open and zoom  . The reason I did so big is to showcase the loop it is going through.
. The reason I did so big is to showcase the loop it is going through.
BUT: the weird thing is that the ui is there and I can create a workflow. I have not tested and seen if it is trust worthy to let it run and it executes yet. As I have only needed to build an app for now.
INFO
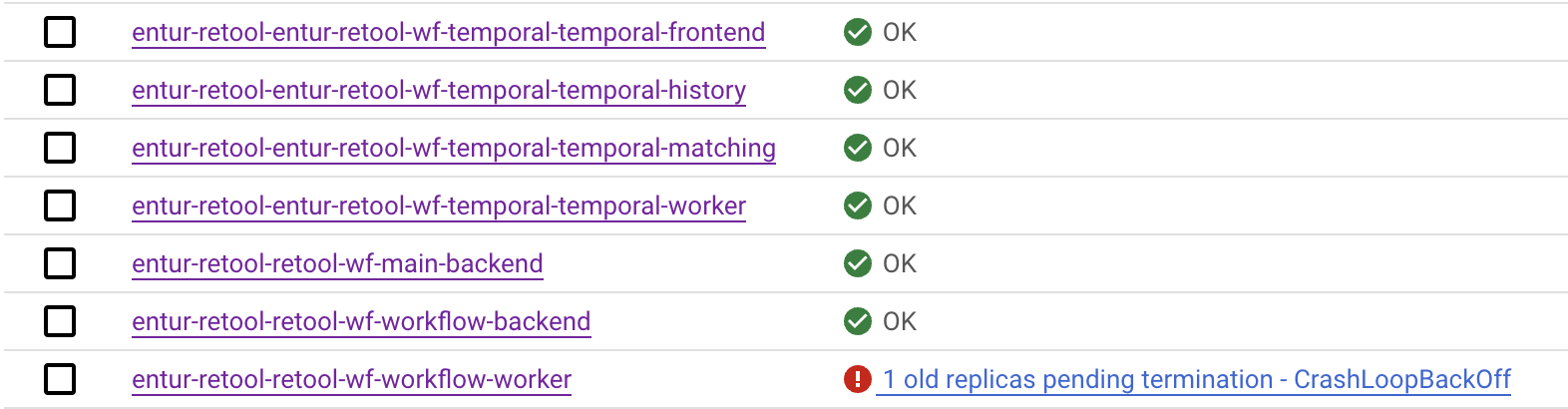
All other containers are green
The ui loads
I followed the helm recipe, GitHub - tryretool/retool-workflows-helm
I host on GCP
I use the sidecar proxy sql pattern and it works for all other containers.
Hey @snorreentur! I'm seeing a bunch of warnings here but no errors  Do you have any additional logs that might indicate what's prompting the pod restart?
Do you have any additional logs that might indicate what's prompting the pod restart?
@Kabirdas the red dots with !! are errors according to google
But the main point here is that this loops over and over again, and it never gets started status. Just alot of restarts and warning or crashback loop in kubernetes.
I just wanted to inform you guys that running this up does not automatically have this specific service running and I assume its important to have everything running? The serivce is the workflow-worker.
But a status update her now. The service turned green 3.5 days, 634 restarts, after the helm chart was run, on ONE environment, the staging environment. But in our PROD environemnt it continues to restart, up in 2300 now, and fails to start and execute workflows.
Staging outputs "normal" logs and it seems fine.
Prod loops the same issue as mentioned earlier
But I assume that the service should not take 3.5 days to properly get started? And not be different from env to env
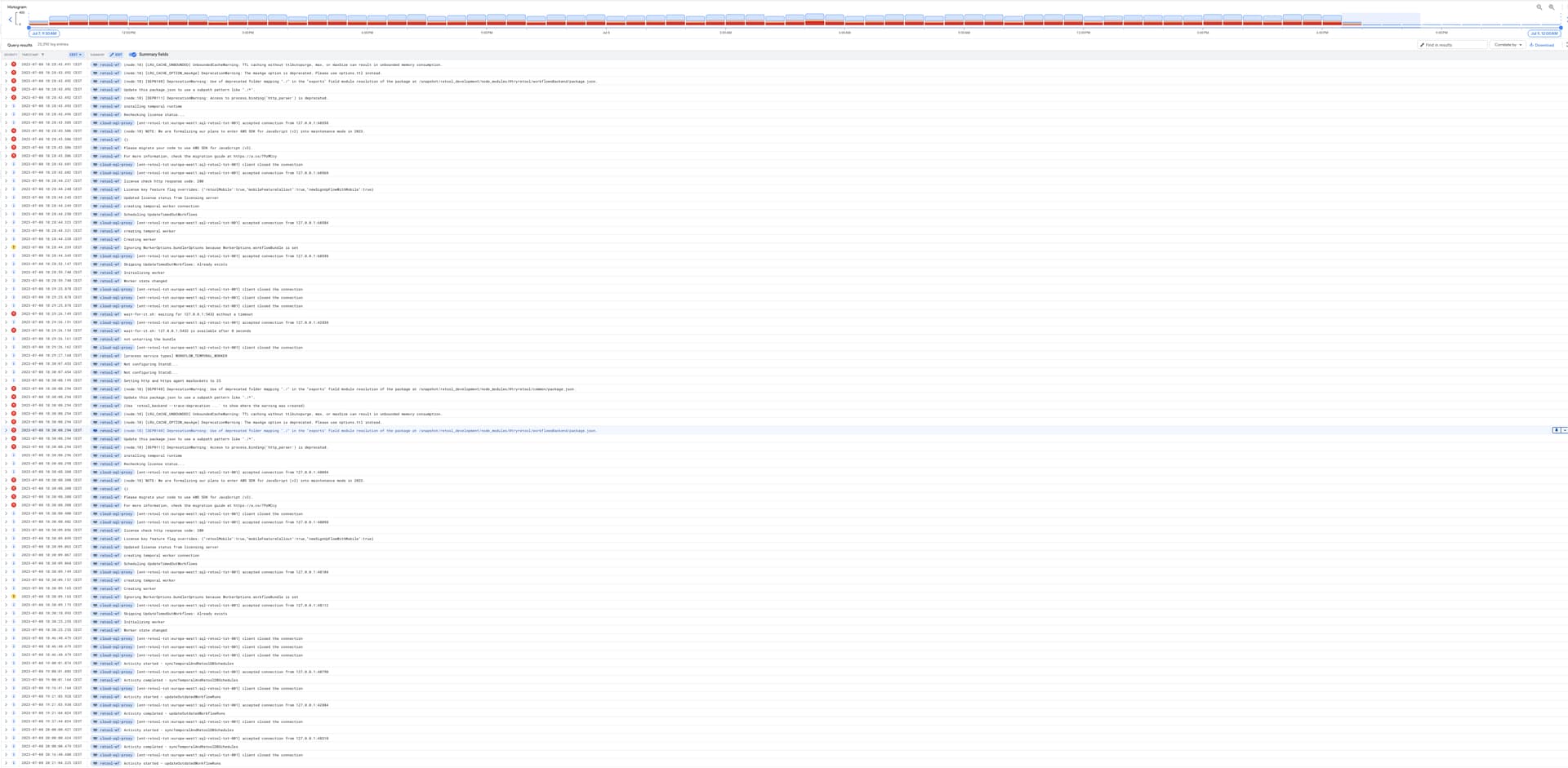
In the image here, you can see that STAGING is error for many many days, where it suddenly just starts working, and I dont know why
Hi,
I've had similar issues last week with retool on-prem, be it hosted on a VM with Docker. Thanks to @Isaac-H I was able to resolve this.
My temporal container was continuously restarting and workflows didn't run. I was able to start workflow from within the browser to test.
What solved it, was adding these environmentals to the temporal container config in docker-compose.yml.
POSTGRES_DB=
POSTGRES_USER=
POSTGRES_HOST=
POSTGRES_PORT=
POSTGRES_PASSWORD=
SQL_TLS_DISABLE_HOST_VERIFICATION=true
I don't know if this would help you in K8/Helm, but maybe it does.
2 Likes
Thanks for the suggestion! I will check it out, but in the end its not my temporal containers, but the workflow worker. And as I wrote, for some weird reason, after 3 days it suddenly worked for one environment, but not the other.
But, these environments, are they added to the temporal env or the retool backend env?
As you can see here there are two sets of deployments, the once about temporal, and the once about retool servers
Update
I currently have TLS disabled since I use a SQL proxy from google, so I dont know if this verificaiton item will do any affect for me. My story on using SQL proxy Using cloud_sql_proxy from google activly both on self host and on resources - #2 by juan, so it allows me to run my code, or retools code, towards localhost and the SQL proxy takes care of security
Just looked at my conversation with support and also for me initially, the retool workflow wasn't working. Continiously restarting. Also CPU was extemely high.
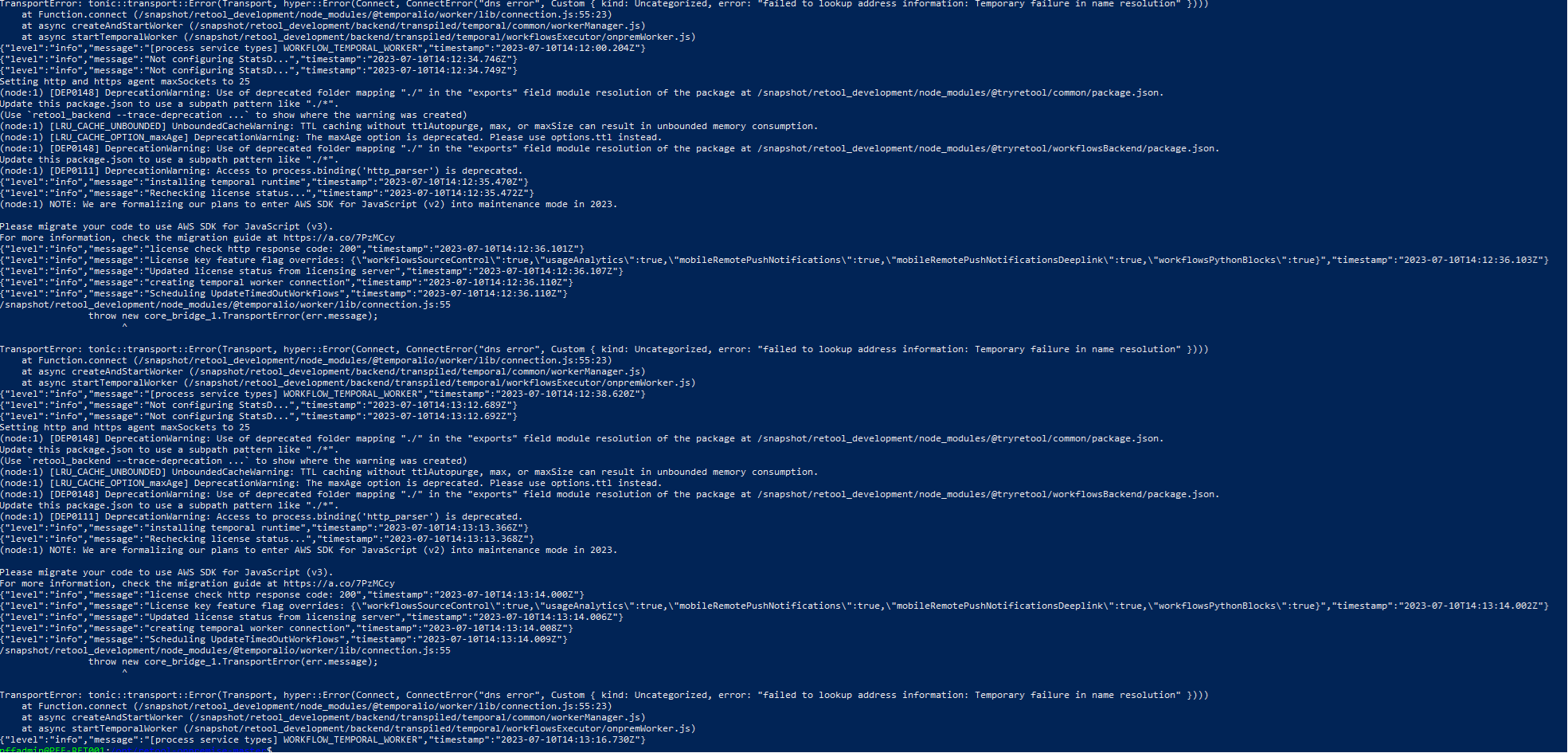
I can't read the log lines from your screenshot, but this is what I was seeing in my logs
And according to @Isaac-H :
If the DB connection isn't working, this will cause a whole host of problems in retool, and is probably also causing your workflow container to constantly error out on loop as it tries to connect to the DB, which is causing the increased CPU usage and constant crashes.
I don't know in which env file to add those variables in your setup, I'm using Docker. Maybe you can find some simalarities if you compare the docker files with the helm files?
I also had to add these to the docker.env file, without these, it was causing the DNS errors in m workflow worker logs:
SQL_TLS_ENABLED=true
SQL_TLS=true
SQL_TLS_SKIP_HOST_VERIFICATION=true
3 Likes
@mbruijnpff thanks alot for your detailed feedback! I tried it out and unfortutnately it did not work. Im using gcloud proxy server, towards hosted postgres in gcloud, and the feedback im getting is that ssl is not enabled by the server.
So maybe @Isaac-H can pop by and come with some other good suggestions I can try out  Or maybe @Kabirdas have some suggestions?
Or maybe @Kabirdas have some suggestions?
Hey @snorreentur, it doesn't look like you're actually getting any significant error logs back, before the restart. Which usually indicates an issue with resource allocation.
(I can't read the second log screenshot - too blurry)
The fact that staging just started working after failing without changing the setup also suggests a resource issue, because retool usually consumes the most resources during startup. It's likely that you're just on the border of having enough resources, and it eventually retried and happened to start up more slowly (consuming less resources) enough to not crash on startup.
Either that or perhaps your infra or some other dependant factor was changed by somebody else which fixed the issue
How much cpu/memory have you assigned? (the default from the helm chart?)
Can you try increasing this to see if that solves the issue?
If it's still not working after increasing the value, can you DM me your helm chart values? (or share them here with redacted values in the format etc.
Do you have any other error logs from any other containers?
Thanks for that magical suggestion @Isaac-H !
That sure was it! I increased resources request under workflows with 100% CPU and 50% memory, and then it started right out of the gate. Also increased the limit memory just a bit so the memory slot had a bit to go on.
I have added some logs to maybe be able to provide som better feedback if the resources are bad. Hope these are readable Sorry for not checking the other picture, I just too things for granted
Great that you sorted this out. Will keep this in mind when in case I want to move to k8.
Cool, there are a couple of other things you have to consider when moving to k8s on self hosted with workflows.
Service account error in chart
The borrowed helm chart for temporal: [Bug] ServiceAccount does not act as it should when adding external account · Issue #403 · temporalio/helm-charts · GitHub
Cloud proxy issues, good to know about
Google specific: Using cloud_sql_proxy from google activly both on self host and on resources - #4 by juan
Extra containers(sidecar pattern) issues
Helm chart specific for extra containers, reported on documentaiton in intercom:
Hi! This page, self hosted workflows, is really not working. But i think it is the retool chart itself and the line https://github.com/tryretool/retool-workflows-helm/blob/main/templates/deployment_backend.yaml#L247.
Im trying to add an sql proxy sidecar container, ref https://cloud.google.com/sql/docs/postgres/connect-kubernetes-engine#proxy. But the yaml is broken, im trying to go about and fix it but I struggle just a tad bit since im new to helm syntax. But getting there. But I want to drop this messages just incase you guys can tell me if its working or not.
Just trying to add extraContainers fail misserably
Solution: You have to use yaml multiline functionality to send in the extraContainers for the retool backend. It works without this for the temporal chart config
------------------------------------------------------------
Maybe @Isaac-H can update the self hosted workflow documentation for Google, so that people wont hit these issues