This does manage to place all the test from the response body into the file, but I am unable to import the file in blender. When I run a "GCS download file" query on the glb files, those import into blender just fine. I noticed that the renamed download was also approximately twice the size of the working file: 4.5mb instead of 2.7mb.
When I open up both the 4.5mb file and 2.7mb file side by side, the binaries are different but the text appears the same. The best guess I have is that at some point newlines are formatted into the content, but I don't know when in the process that would occur.
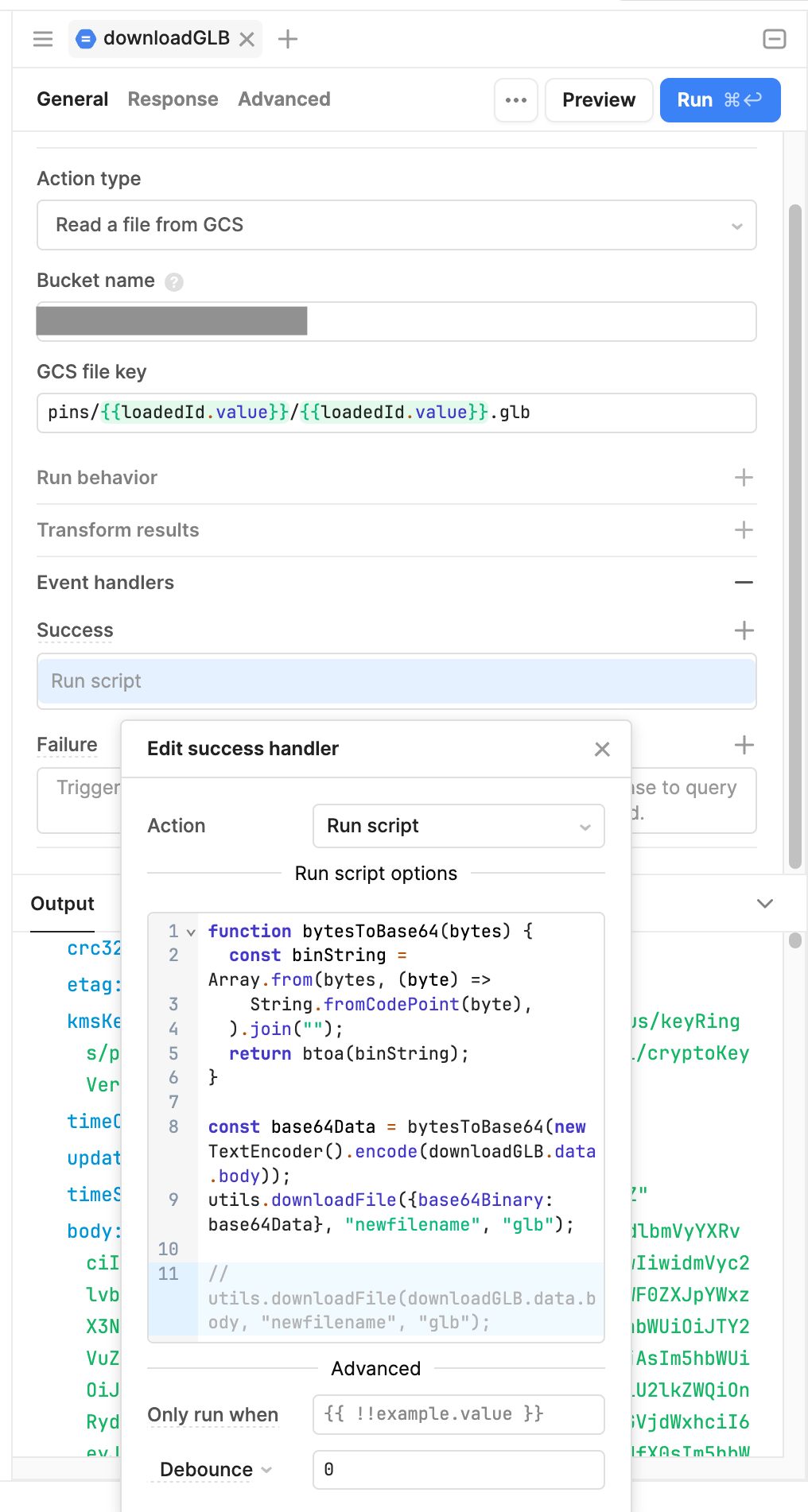
I've tried other scripts to run upon a successful read, such as:
My deepest apologies for the inconvenience of this issue.
Thank you for providing such detail, I am going to try to reproduce this and file a report for our core data team to take a look at this to figure out what is going on and what we can do about the file size
Just for quick clarification, the bytesToBase64 function is able to get the response body into a file, but that file isn't importable in blender. How are you fetching the response body that you are passing to that script?
And then because that method does not work you are forced to try using a "GCS download file" query which is at some point bloating the file size, I can definitely talk to some engineers to learn more about this process and see if I can confirm that the issue is related to new lines being formatted into the content
The GCS download file doesn't bloat the file size. The file download size is expected (2.7mb) and imports properly into Blender.
The bytesToBase64 is getting the response body into the file, but the result is the same as putting the response body directly into utils.downloadFile().
I'm fetching the response body by running the above function upon a successful GCS bucket file read query.
Gosh, I need to proofread my posts better. Some more clarification. The bytesToBase64 function returns the same data as the body data in a successful GCS bucket file read query. When both results are downloaded, they result in the 4.5mb unreadable file.
I did some testing and couldn't get the file size to bloat using utils.downloadFile() My file started at 5.2 MB and didn't change, but maybe the file was different from yours in a way I will have to try to emulate.
I was using a random file I found, which should have new line symbols within it (although it is from an audio of a podcast with the data as gibberish that likely represents sound data).
Do these look like the same steps as you have set up? Also if you could send me your 2.7 MB file if it's not private data I could test this out with that file as well to see if I can reproduce it.
I have a glb file you can test against, although I'm not sure how I'd be able to send it to you. I would assume the the issue persists regardless of the glb file.
Thank you for sharing that test file. I was able to get it into my GCS account and was able to test it and another GLB file I made.
I can confirm that running your script caused the files to increase in size
Going from 659.7 KB to 901 KB for your file.
And 979.3 KB to 1.3 MB for the file I made to double check against.
Doing some research it seems that converting binary to base64 with bytesToBase64 is likely the culprit. As each set of 3 bytes (24 bits) of binary data is converted into 4 Base64 characters (each 6 bits).
This adds ~33% overhead because:
4/3 = 1.3333 (33% more data).
Additional padding characters (=) may slightly increase the size.
I then tried changing the script as it seemed that the query.data.body returns a string that is already base64 encoded and if we could remove this step it should prevent the file bloat.
I found that the file size did not change for me and these files worked when importing them into Blender!
Let me know if this works for you, it looks like you tried a similar script with utils.downloadFile(Base64Binary: downloadGLB.data.Base64Data) but I am hoping if you save the query.data.body to a const variable and then pass that in to the util file that it will work as it did for me!
All the files I had run the script to convert the string to binary to base64 all gave me an error when trying to import them into blender so can confirm that behavior is in some way corrupting the files. Except for the ones I downloaded with the script I shared at the top.
Sorry for the delay. I went ahead and tried what you suggested with the following code. For some reason, now nothing downloads at all. If I add a random string into the base64Data variable, it will download. But something about the query body isn't sending a download to me. I don't see any log failures for the download function either.
Oh no that's is not ideal that utils method should trigger a download to your computer as soon as the query response comes in.
That is curious that if you 'add a random string to the variable' that it will then download. That sounds like it could be the query either doing some kinds of caching we don't want or that it might have gone into a corrupted state since it isn't failing and somehow isn't doing what the code should execute.
You may need to try either cloning the query or duplicating the logic to another query and deleting this one. I am not able to reproduce utils.downloadFile() not working, so starting fresh from a new query might get things working as intended
I came back from break and reviewed the issue with Eugene at ReTool. Somehow, me going on break fixed the issue. The download button works now downloads the correct glb file. Your previous post was correct. Something else must've prevented the code from running, although I couldn't tell you what. I might have ran into some form of caching error like you said.
Thank you so much for all your help!