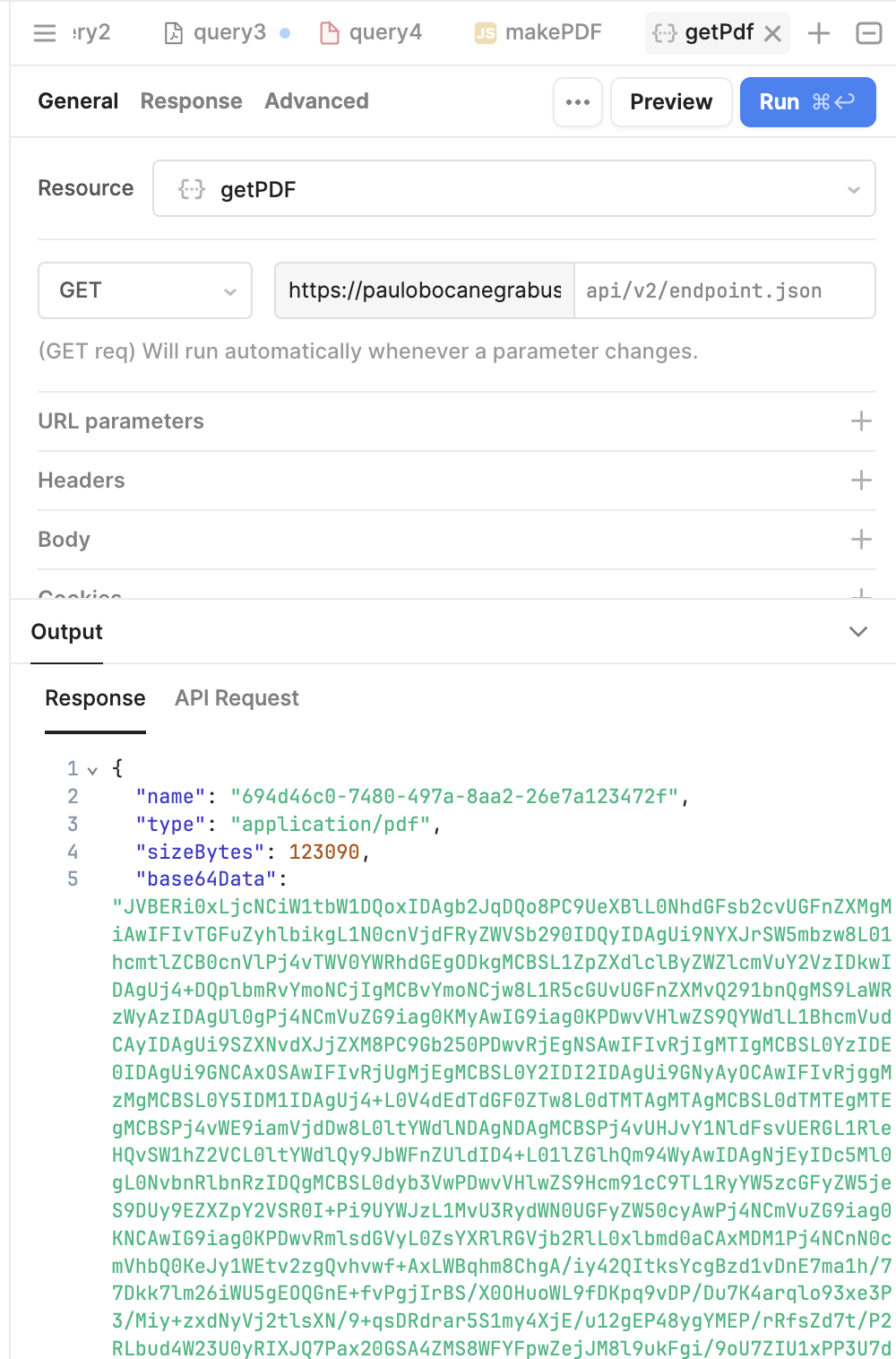
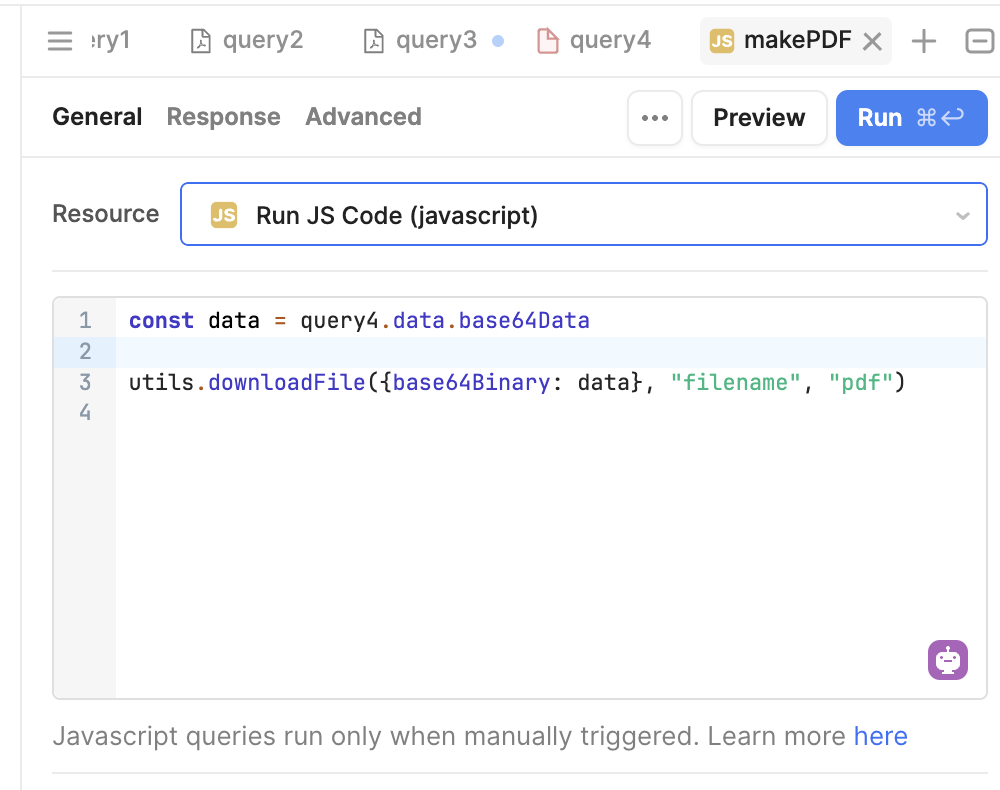
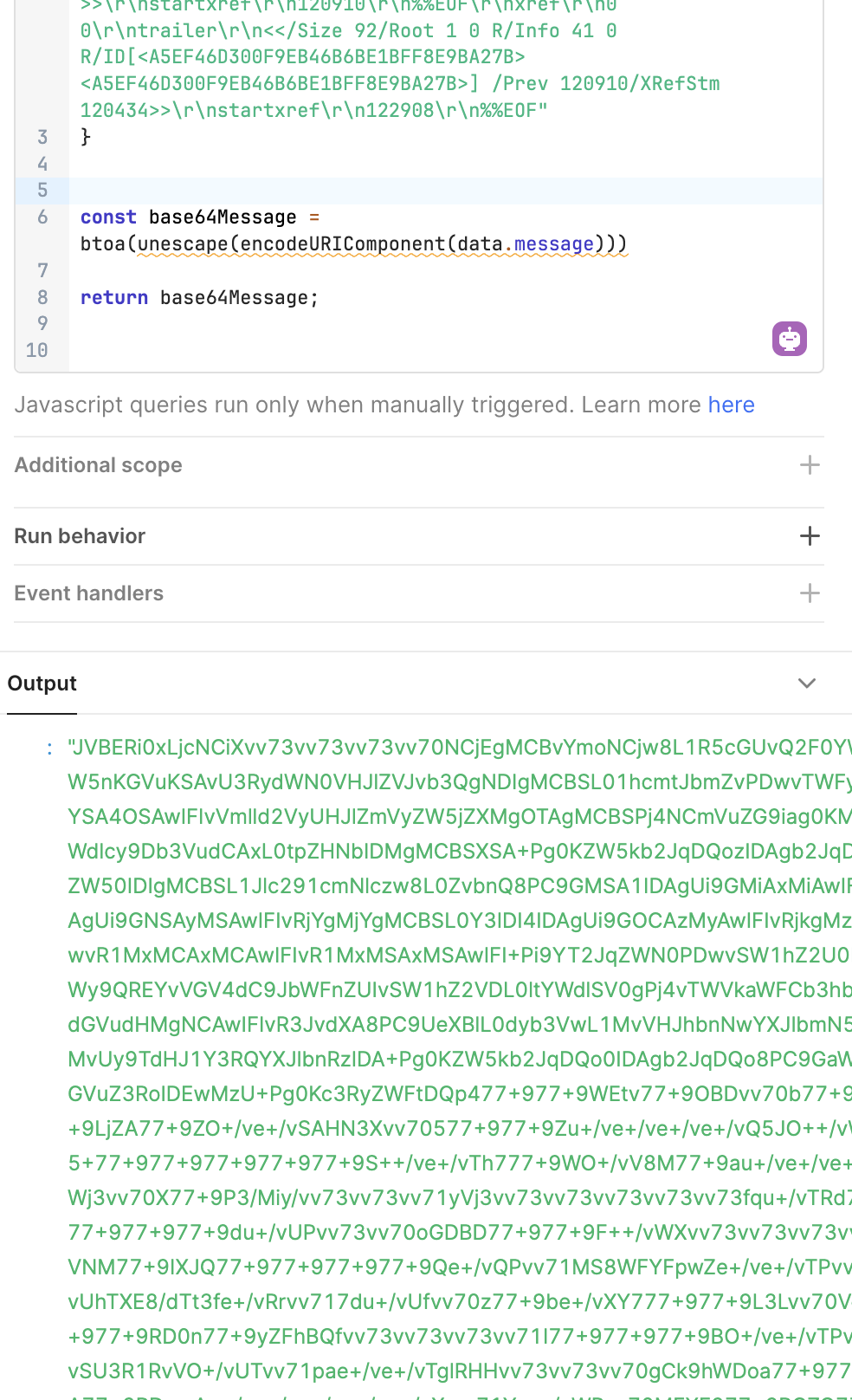
That seems to get good base64, but the download stays in that format (when opened in notepad++) and doesn't work. We did notice that the working PDF we have is ANSI encoded and the downloads are in UTF-8 The working PDF also does not look like base64 anymore when opened in notepad++
Ultimately, this will have more than just PDF files coming through, but we have some of it hard-coded as a short cut while we get the downloading part sorted.
I just confirmed there is no way to get the data in a different format. Is there some other code that could be used to be more explicit about what it is receiving so that it can better convert it?
Hi @Nic, after more testing I can't help but to think that the API is not giving us ASCII back. Maybe it is, but it seems to be adding characters that shouldn't be there.
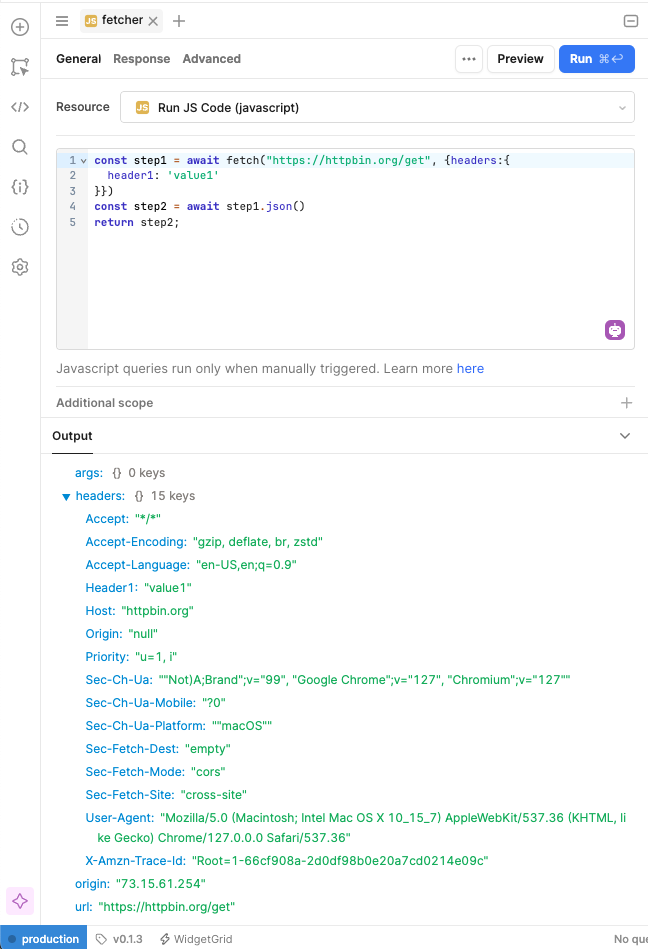
Hi Paulo, we were actually able to get it working in an entirely script, using fetch, but when we switched to the production environment we started getting CORS errors and it sounds like fetch isn't fully supported - I've been trying to merge this with a normal query, but I'm having trouble returning all the data in a way that it makes it back to the script. Any suggestions?
Here is the script that worked in staging and works in prod if I use a CORS proxy, but that's not a workable long term solution.
const MAX_CHUNK_SIZE = 1024 * 1024 * 5; // Define tu tamaño de chunk aquíconst
const internalFileIdentifier = FileID
class MyAppState {
constructor() {
this.AccessToken = (obfuscated, this is elsewhere);
}
}
const _appState = new MyAppState();
function setMessageDefaultHeaders() {
return {
"Authorization": `Bearer ${_appState.AccessToken}`,
"Content-Type": "application/vnd.api+json",
"Accept": "application/vnd.api+json",
"User-Agent": "MyPythonApp",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
"mode": "no-cors"
};
}
async function downloadFileAsync(internalFileIdentifier, fileSize) {
let totalChunks = Math.floor(fileSize / MAX_CHUNK_SIZE);
if (fileSize % MAX_CHUNK_SIZE !== 0) {
totalChunks += 1;
}
const data = [];
const headers = setMessageDefaultHeaders();
for (let i = 0; i < totalChunks; i++) {
const url = `(shortenedforclarity/files/${internalFileIdentifier}?part_number=${i + 1}`;
console.log(`Requesting part ${i + 1}. URL: ${url}`); // Debugging statement
const response = await fetch(url, { headers });
if (response.ok) {
const chunk = await response.arrayBuffer();
console.log(`Downloaded chunk ${i + 1} of size ${chunk.byteLength} bytes`); // Debugging statement
data.push(new Uint8Array(chunk));
} else {
console.error(`Failed to download part ${i + 1}, Status: ${response.status}`); // Debugging statement
return new Uint8Array(data.reduce((acc, val) => acc.concat(Array.from(val)), []));
}
}
console.log(`Total downloaded data size: ${data.reduce((acc, val) => acc + val.length, 0)} bytes`); // Debugging statement
return new Uint8Array(data.reduce((acc, val) => acc.concat(Array.from(val)), []));
}
function saveFile(fileName, data) {
const blob = new Blob([data], { type: "application/octet-stream" });
const url = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = url;
a.download = fileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
}
async function main() {
const internalFileIdentifier = currentSourceRow.file;
const fileSize = currentSourceRow.fileSize; // Reemplazar con el tamaño real del archivo
const data = await downloadFileAsync(internalFileIdentifier, fileSize);
saveFile(currentSourceRow.name+".pdf", data);
}
// Ejecutar la función principal
main().catch(console.error);
Any idea on how to make sure we get the right data back? I used this, and it seems to run ok, using the additional scope to structure the query, but doesn't seem to pass enough data back to the query for the rest to work. Advice for how to make what gets back to the query look more like it would as a fetch?
const response = await DownloadFile.trigger({additionalScope:{field1:url,field2:partnum}})
results.push(response);
results.push(result);
When we tried no-cors it corrupted the response somehow so that it didn't work in a different way. Using a query to run the same command manually works just fine (but then we get back to the conversion error), and running it in a fetch gets the CORS error. If there is a way to get that to work, great, or if we can pass the query back in the same style that a fetch would have gotten it, then I think that would actually be even better than the fetch.
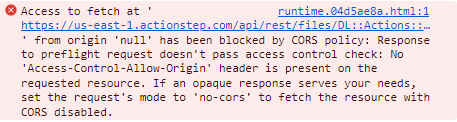
We've tried a couple of other iterations, so here's another error log with one of the other settings we tried.
The software we are working with, Actionstep, has a staging and a production version of the server - it worked with their staging environment but not with their production environment.
Yes, I have keys, I've used them for lots of other things and they do work in this case when using a query instead I can still get a proper response, but since I could only get a working download file using the script, I'm struggling to pass the response from a query version back to the script without it being corrupted or otherwise not working anymore. The fetch mechanism seems to be treated differently from a CORS perspective and from a processing the response perspective - one for the better, one for the worse.
Let's try something. Set up a REST API to handle one chunk at a time so it can replace the fetch, which seems to be the limitation. Use the same headers and set up Additional Scope variables for the part_number and other dynamic values we need. Then on the script you shared, just replace the await fetch(url, { headers }) with:
Doesn't look like it worked in staging even - I think it doesn't pass enough data or it gets corrupted even just doing that - the query works on its own, and the full version looks like it is running ok, but the downloaded file is empty, so it's still definitely getting corrupted somehow on the way out.