Thanks for the suggestion! I will check it out, but in the end its not my temporal containers, but the workflow worker. And as I wrote, for some weird reason, after 3 days it suddenly worked for one environment, but not the other.
But, these environments, are they added to the temporal env or the retool backend env?
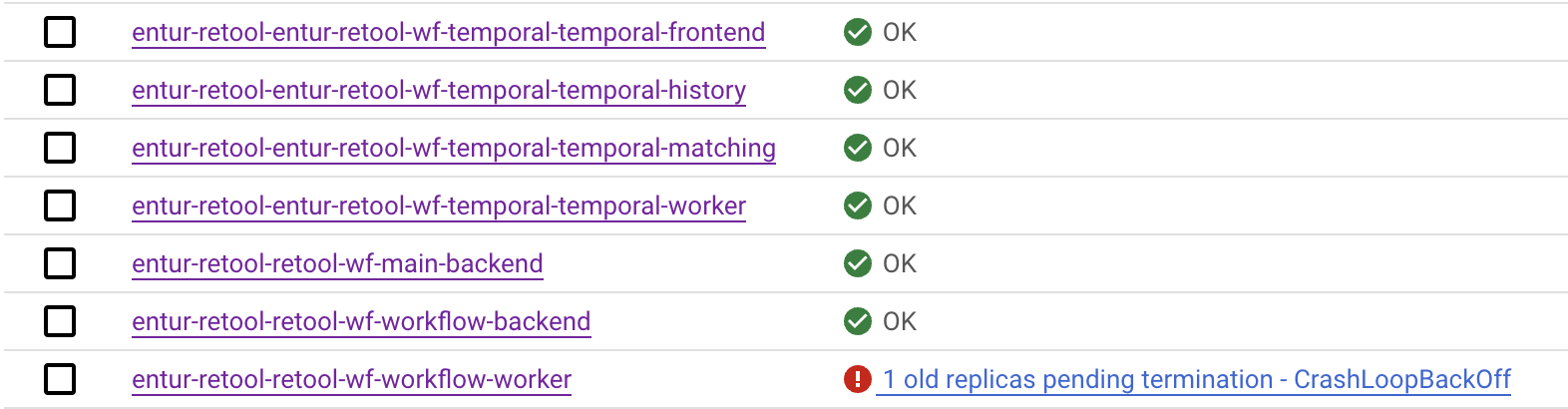
As you can see here there are two sets of deployments, the once about temporal, and the once about retool servers
Update
I currently have TLS disabled since I use a SQL proxy from google, so I dont know if this verificaiton item will do any affect for me. My story on using SQL proxy Using cloud_sql_proxy from google activly both on self host and on resources - #2 by juan, so it allows me to run my code, or retools code, towards localhost and the SQL proxy takes care of security