Hello, our team has noticed that on our self hosted instance, our primary RDS instance that contains the hammerhead_production db has filled up with 440GB of data, all in the public.workflow_block_results table. Is there a setting I can make or change in our configuration to reduce the amount of data output there?
I also would like to know if we can safely remove these records without breaking anything related to history.
My goal: Reduce the storage that our RDS instance is consuming
Issue: The public.workflow_block_results table on our self hosted instance has exceeded 440GB.
Retool version & hosting setup (Docker, K8s, cloud provider, etc.): AWS; docker ECS, RDS, retool version 3.30.2
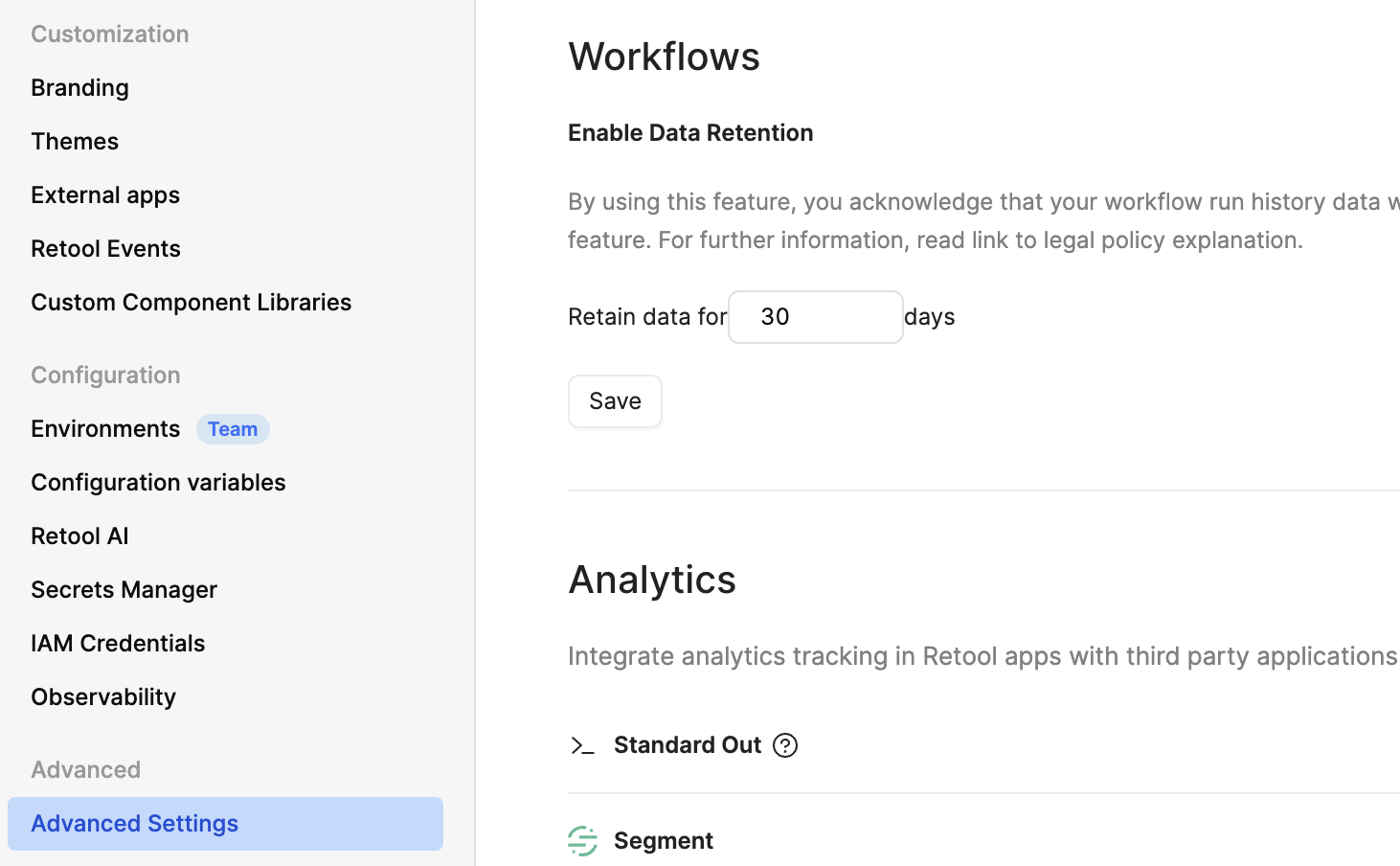
Hey @buzzy - thanks for reaching out! Do you know whether you're utilizing the Retool Temporal Cloud or a local Temporal deployment? And have you set a specific window for data retention via your org's Advanced Settings?
If you have this setting configured but are still seeing stale data, it's possible that the cleanup service is failing. You should be able to find relevant logs - and the underlying cause of failure - by searching for schedule-blob-store-cleanup or deleteBlobStoreDataIfRetentionExpired! If all else fails, you can safely delete elements manually.
Hey @Darren ! We have retention for 30 days enabled but it has always been set to that but we are just now seeing this storage issue. We do have the local temporal deployment via docker and I found that the schedule-blob-store-cleanup job was not running for about a month. There are no logs related to schedule-blob-store-cleanup during the time where the RDS storage was rapidly decreasing and the logs show that job running without errors and successfully, when it did ran.
Can you please describe the process of deleting these records manually? Can I just dump the workflow_block_results table entirely or what can I do here?
Hmm good to know. I can do some additional digging and may reach out for more info about your logs, if you're willing! In the meantime, you can connect to the DB and run the following:
DELETE FROM workflow_block_results
WHERE "dataExpiresAt" < NOW() - INTERVAL '1 month';
Yeah feel free to reach out for anything additional and I can try to provide. Something that is odd is that we have records with createdAt with dates from mid 2024. Is there more data in here than just the results from the workflows?
Not that I'm aware of! It should just be workflow data. And I just realized that the query I shared above doesn't need the INTERVAL clause, as it already references dataExpiresAt.
@Darren Yes, after manually pruning the workflow_block_results table, the bloat did decrease. I also want to mention that this bloat stopped increasing once the schedule-blob-store-cleanup job continued to run again. I don't know why it stopped running and the logs do not indicate any clear underlying reason.