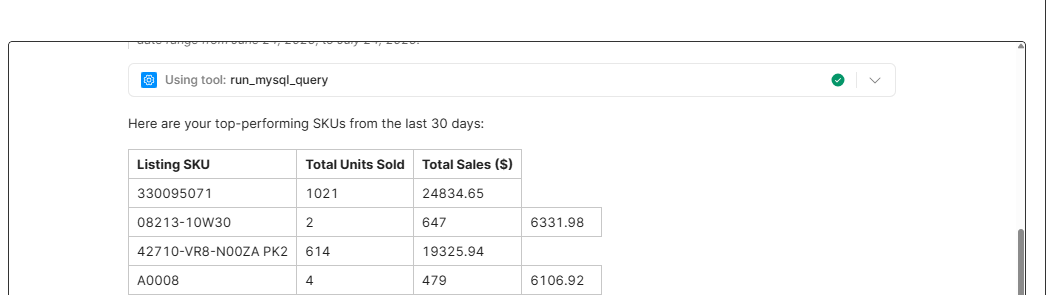
ahhh I see, the HTML entity might not work correctly in this context, or it might be sort of iffy. technically it should work? but what the Agent does is sorta up to it..... a more targeted solution might be better here since we can guarantee we won't modify any of the actual data, just its formatting. occassionally complex prompts with lots of small details some of the small things can get skipped, you might also have to deal with hallucinations from when it thinks a rule must be applied somewhere but it can't figure out how so it forces it (like cutting and gluing random puzzles pieces from different puzzles together and using it as a replacement for a lost piece.... you technically finished the puzzle... but did you?)
since this is a rendering issue, not a model response issue (technically it's outputting correct Markdown, the | is just being read as a column separator instead part of a column value. Instead of trying to stick a formatting/escaping instruction in the prompt it might be more reliable to give the agent a tool named 'process_response' or something and pass along the full response.
The Simple Solution (not flexible)
.... ok so I was gonna just leave it at that, but then I realized I could actually make use of something like this. There's actually a really interesting problem here since we don't know what column(s) can have a | in their value. I eventually noticed your first column is for SKUs and the other 2 are numerical.... so the solution is simpler if we know for a fact only the left column can contain spare |'s.
markdown_table_processor_simple.csv (13.3 KB)
"""
processes markdown text that may contain tables with problematic pipe
characters within cell content. It intelligently distinguishes between structural
pipes (table separators) and content pipes (data within cells) to preserve table
structure while escaping problematic pipes as HTML entities.
Args:
text (str): Input markdown text that may contain one or more tables with
pipe characters in cell content
Returns:
str: Processed markdown text with:
- Pipe characters in cell content escaped as HTML entities (|)
- Cell values wrapped in HTML <code> tags for safe rendering
- Table structure preserved and properly formatted
- Non-table content left unchanged
Example:
>>> markdown_text = '''
... # My Document
...
... | Product | SKU | Price |
... |---------|-----|-------|
... | Widget | ABC|123 | $29.99 |
...
... Some other content.
... '''
>>> result = process_markdown_with_pipe_escaping(markdown_text)
>>> print(result)
# My Document
|<code>Product</code>|<code>SKU</code>|<code>Price</code>|
|<code>---------</code>|<code>-----</code>|<code>-------</code>|
|<code>Widget</code>|<code>ABC|123</code>|<code>$29.99</code>|
Some other content.
"""
yay this is neat. However, it merges "columns" from left to right assuming the 1st column will most likely be the issue....
Hmmmmmm
so why am I still typing? lol
well, I thought about this solution and I decided that since you used the wording
In this example
that perhaps this was just the simplest example to show the problem with. You could have much more columns that all could possibly contain extra |s and it might be a column in the middle of the table and the | might occur near the beginning or end of a columns value. so i explored a few options 
comprehensive_comparison.csv (8.7 KB)
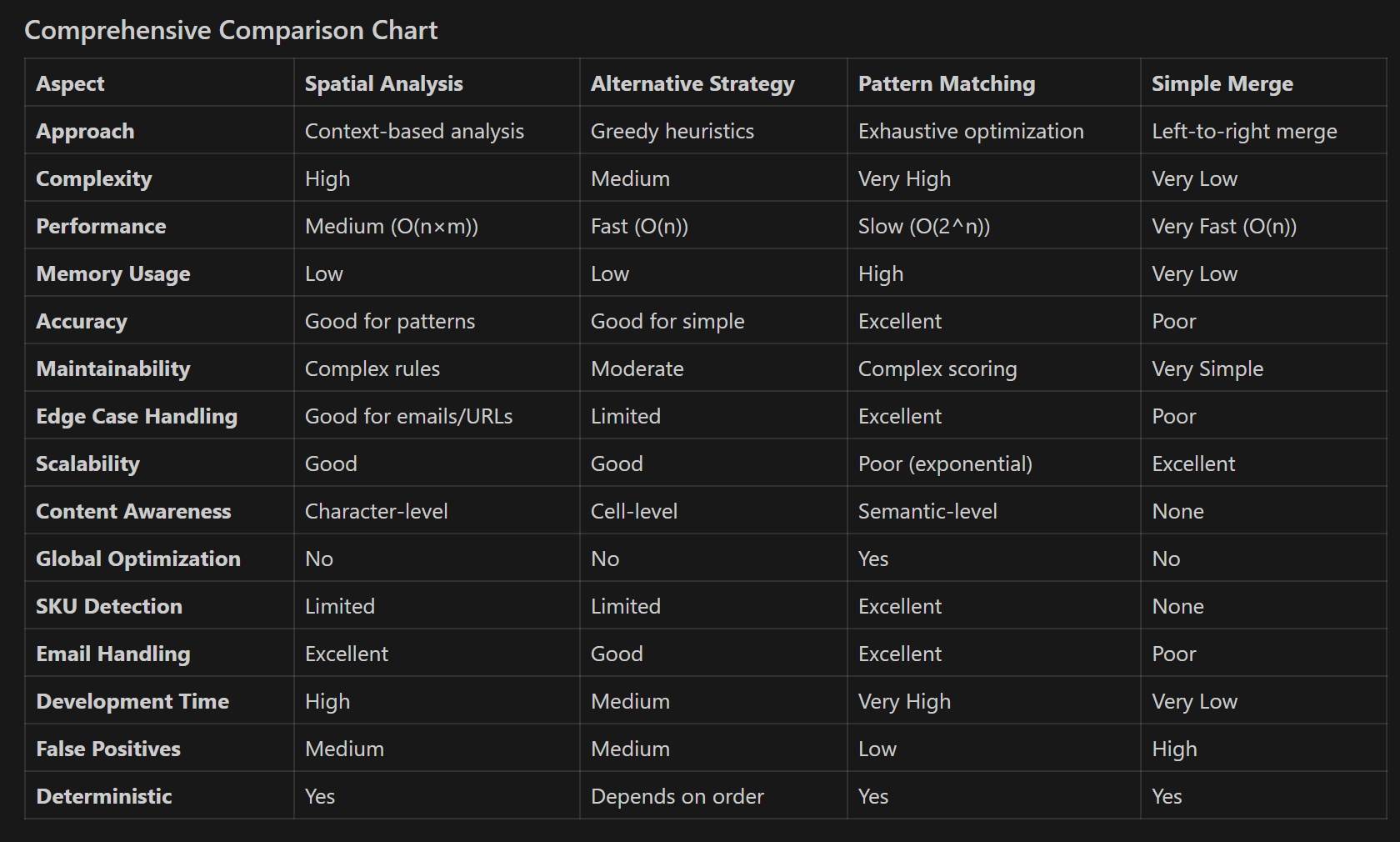
Spacial Analysis
Greedy Fragment Merging
Pattern Matching
Simple Merge
- Basic left to right merge
- Implementation:
- Identified tables and expected column counts through structure analysis
- When excess cells detected, merged all extra cells into the leftmost column
- Preserved rightmost cells assuming they're more likely to be correct
- Applied simple pipe escaping without complex decision logic
Best Solution (IMO): Pattern Matching
I didn't wanna type this next one out, so yay Claude!
Note:
sorry for the .csv file type but it doesn't allow me to upload .txt for some reason (I fully understand not allowing code files, but txt files??). Anyway, just rename them with either .py or .txt if you want to use them directly or u can just open the csv in notepad and copy/paste to wherever