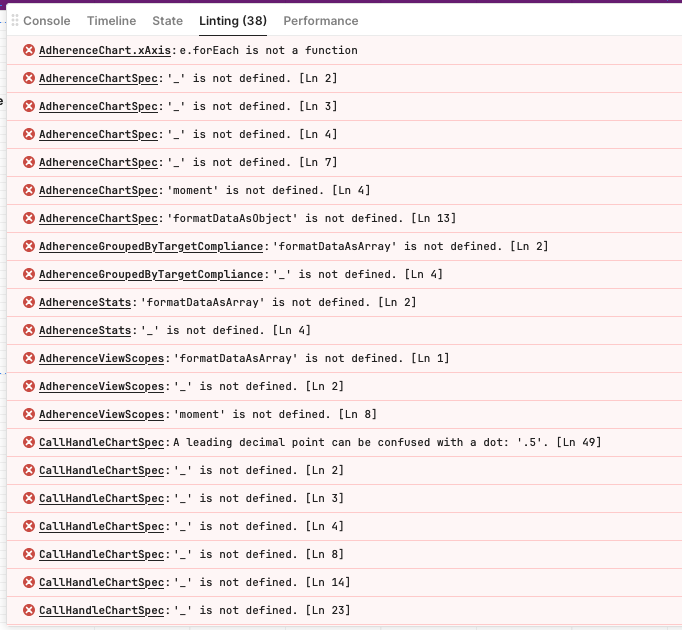
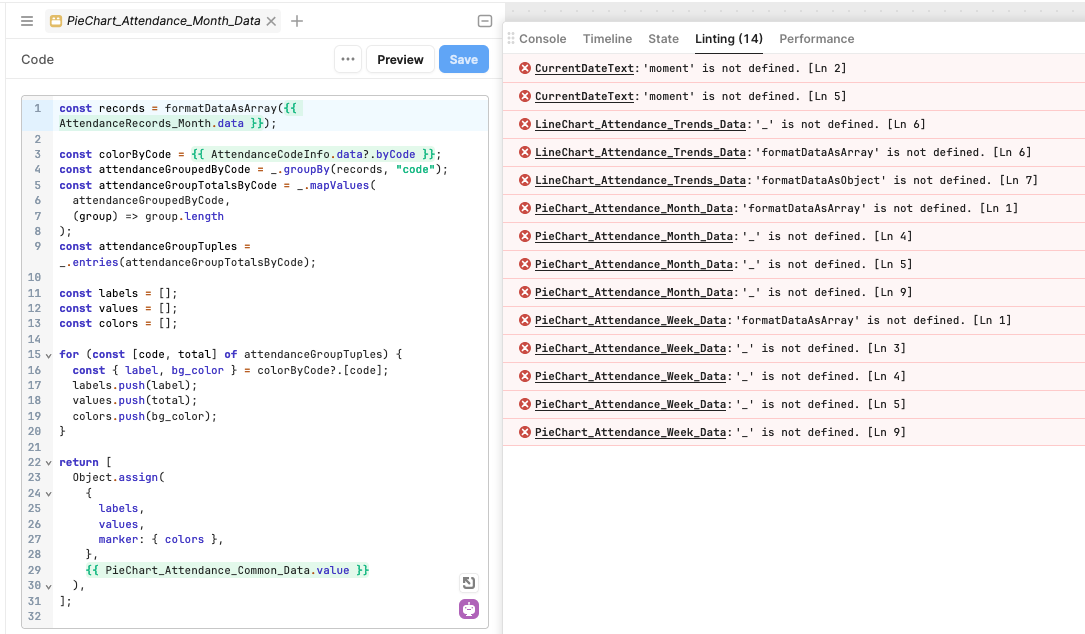
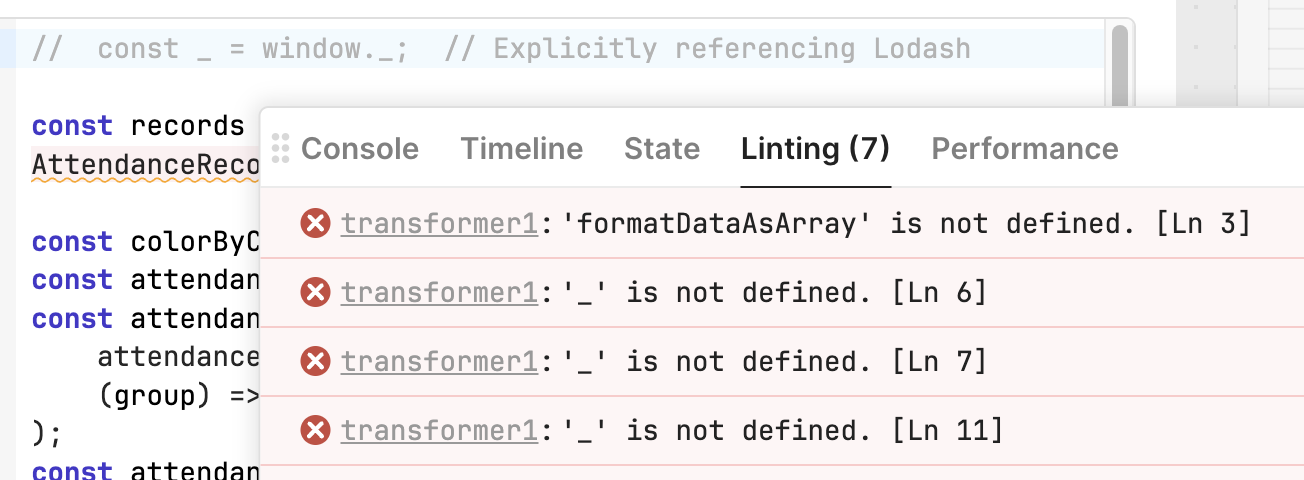
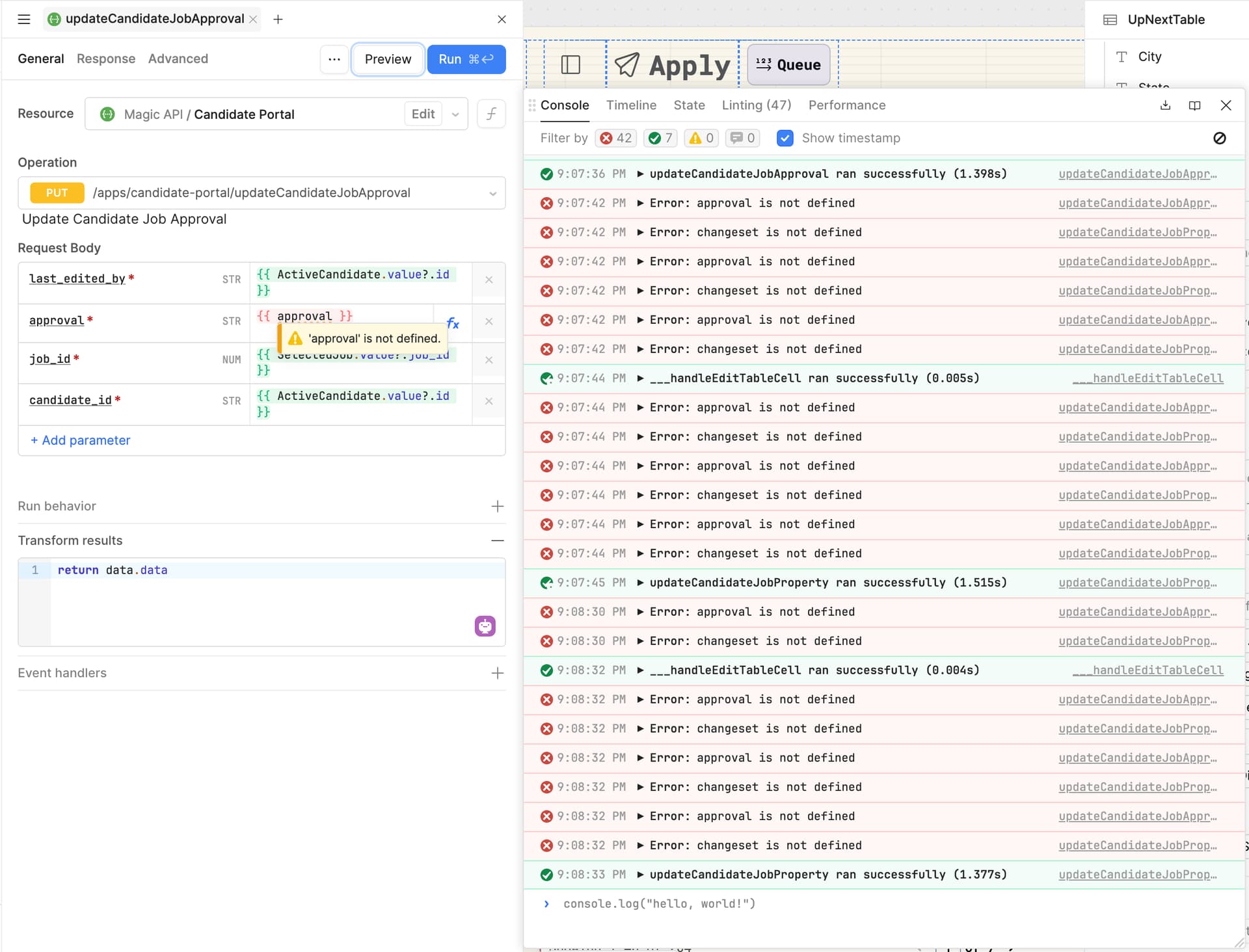
The new linting rules can be helpful (open your Debug window and click on the linter tab). But there is one rule that I would like to see tweaked to reduce the number of false positives.
Background
The linter suggests that the number of columns is potentially a performance issue, but there are several of issues with this metric:
Postgres will easily handle large numbers of columns
Most applications will have large numbers of columns
The Retool way of building a table and form requires you have all the columns in the table or the form won't be fully editable.
The metric isn't accounting for the field types and sizes
The metric doesn't account for how many rows are pulled or if caching is on.
I see that Retool is trying to be helpful with their linter optimisations. But they have based this one on an overly simplistic metric: measuring column count.
IMHO
I'd like to propose that the linting metric should be based on the sum (in bytes) of all the columns (and yes, you could average the content in string fields).
For example, my nine column query consists of INT, INT, INT, INT, DATE, DATE, DATE, DATE, CHAR(50) which is a tiny 114 bytes per row. Hardly something that needs optimisation.
I'd love for the dev team to consider this so I can keep reducing my linter messages to zero.
It's still in our queue to be fixed It does seem to be scoped to transformers (vs js queries). In addition to solving the bug, we also have a request to add filters to the linting tab.
For the table columns, I think the idea was to nudge folks that are passively selecting all columns (select * ) to still be mindful of performance if they don't actually need all of the columns, but I agree with your feedback that it could be quite a bit more nuanced! We'll update this thread if our team is able to prioritize a better solution
Do you have any more asks for performance lints (the ones with a stopwatch icon like "table has too many cols")? Or the performance tab in debug tools?
We're planning to do a pass on these in Q4. Will definitely fix this lint.
@PeteTheHeat if I could drop in one more request on linting...
This one has been here for a very long time, I think. Seems like it has been fixed for other resource types (since you can more easily specify additional parameters), but not for the OpenAPI resource.
Unfortunately, this doesn't even show up in the linting tab (feature request: let me specify something as a linting error, or rather ignore it entirely in the IDE with a right click).
Code works fine, never had an issue. Using the conditional ? operator doesn't work in this case, since the parameter itself is not recognized (undefined).
So I get this very large wall of red, not-real-errors that make it hard to debug the rest of the application.
Thanks for flagging this, @matei. As you noted, there has been some improvements here, but there are still some edge cases where these linting errors come up. Will post here with any updates
As of today, these errors and that performance lint should be fixed!
We really value your feedback in helping us catch these edge cases and we've been working hard to improve the debug tools to be more powerful, accurate, and helpful than ever.
Please continue to let me know any thoughts and feedback for the Debug Tools, thank you for your patience, and happy building!