I am pulling reports from the Amazon API and it provides reports as flat file on a url. If i open that url in a browser it looks like a tab delimited file. Is it possible to have something in Retool to parse this URL without having to download it first. In this case i am building a workflow to upload the reports as on a schedule to a DB.
Hey @nickport!
It looks like the one-liner mentioned here should work well in a JavaScript query for parsing the data you need. Have you tried using a separate REST query to make your request to the URL provided by your API and then passing that result through a parser like the one linked? Curious to know what the results look like and if you've run into any trouble.
Hi @Kabirdas
Thanks thats good information and i feel like that the 2nd step. I am stuck at step 1 though where i get the URL as a string in an API response. It is stored in some s3 bucket that amazon provides but all i have is text of the URL. The question i have is how do i get retool to go inside that URL and fetch the data so i can parse it?
It's possible to pass the returned URL directly to a REST API query:

I'm not sure what exactly that will return as it depends on your API but it might be a good place to start. If you have trouble parsing it from there can you share what the result looks like or how it's formatted so that we can take a look?
@Kabirdas ahh doing a REST API query worked like a charm. The data it returns is hard to parse though. The 1 liner splits up the flat file but its not an array i can work with and i cant formatAsArray() either. How do you format this data to be like a regular JSON array? It looks like [0] gets all the headers and the rest is the actual data.
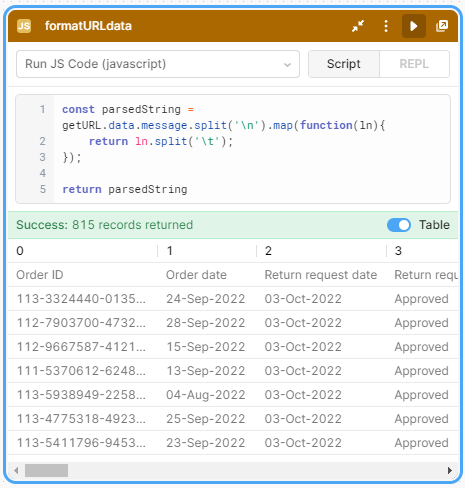
Hm... this is a funky array, I'm not sure what the cleanest way to do it is but this might work, it makes handy use of destructuring assignment and the lodash library:
const [headers, ...rows] = parsedString;
return rows.map(values => _.zipObject(headers, values);
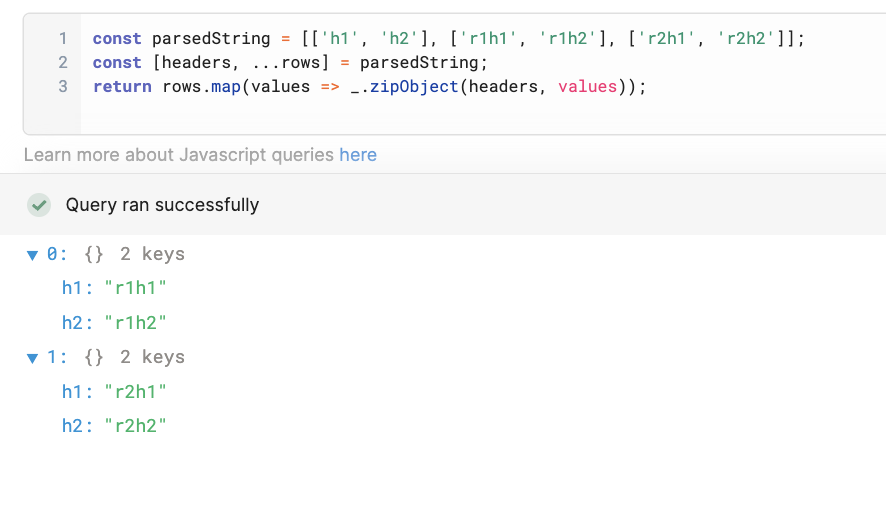
Thanks a lot this worked just to correct your code its missing a closing parenthesis,
const [headers, ...rows] = parsedString;
return rows.map(values => _.zipObject(headers, values));
1 Like
Ah! ![]() Thank you!
Thank you!