I am having an issue with only one of several MongoDB queries I have in my app. The query used to fail only occasionally, but succeed after an additional attempt or two. Now it looks to be failing more frequently.
It is not an issue with the resource itself, credentials, or IP address ranges. Multiple other queries to the same DB but other collections, work fine. It is only this specific collection. I have been unable to find a reason for this.
Super weird bug, good job trouble shooting that the issue isn't coming from the resource itself, credentials, or IP address ranges.
Not sure why all the other queries work fine but not this query to this one specific collection is there anything unique about the collection that makes it different from the others?
A 502 error is 'bad gateway' so I wonder why the Retool server would be getting that error message back as a response from the server hosting your MongoDB instance.
Are you able to check/share the mongo logs to see what the request looks like coming in and if it is being received or if it might be getting blocked by some kind of proxy?
Not really sure how I can reproduce this bug without mirroring your Mongo instance and creating a collection the same/similar to see if I can also get this bug.
Maybe some other users have encountered this/fixed this with their Mongo queries only other option I can think of would be deleting and recreating the query(maybe the same for the collection or migrating the data to another collection)
Thanks for getting back to me! I don't think deleting the query and recreating it would help as I experience the same issue when I create a brand-new app and recreate the query.
Does Retool not have any backend logs you can check? Can you tell me exactly what I should be looking for in the MongoDB logs and where? I wasn't able to find anything useful.
Super tricky bug. Very odd that only one collection is not cooperating and has been failing. Any other details on what makes this collection different from the others might be helpful for seeing if other users have had similar issues.
If you could share the request ID from a failed run, I believe I can check out data dog logs for your cloud account to see if there are more details on where the 502 is coming from and why it is happening.
Can you share a screenshot of the query run in your browser network tab when it fails? Maybe there is more information there but my hunch is that this error is coming from the MongoDB server based on something related to the collection in question.
I would also suggest checking with MongoDB's support to see if they might be able to provide more information from you cluster logs or give more context on the collection that would effect how it is being access by requests from Retool
Apologies for the delayed reply, I have been out of office
Every Tuesday and Thursday the Retool team has office hours where you can share your screen and me and several other support engineers from Retool and try and help troubleshoot the issue!
I would highly recommend it for this odd 502 Mongo error.
@Jack_T I am disappointed that Retool ended the office hours without giving me a chance to discuss this issue after I was considerate and patient to let others bring their issues up before I had a second issue addressed. I was expecting that someone would at least stay on after the hour was up to look at that since I was respectful of everyone else's time and waited.
The office hours is the WORST support model I could possibly imagine! Forcing users to sit through others having their issues addressed, which are frequently irrelevant to the reason the users are waiting is ridiculous. Having just an hour twice a week is equally ineffective. I heard one person say that they have been to multiple office hours, which means they sat through multiple hours of other people getting helped. That is crazy.
The lack of effective support, has me looking for replacements to Retool. We should not have to chase support, support should be available more than twice a week, and if you show up to office hours, you should be guaranteed that you will get your issue addressed. It is incredibly upsetting that developers can show up, and possibly be ignored or have to come days or a week later. You know some of us bill hourly and will have trouble explaining that time, right? Many of us have deadlines or people waiting on our work, we're supposed to tell our bosses "Sorry, the product I recommended only has support twice a week?" My company is on the startup plan, meaning that Retool is currently free for us, and I am STILL looking for alternatives, and it is due exclusively to the support, and not the product. I hope that tells you how broken this model is.
Hey @Sam_S, I hear you. Our team also read and talked about your feedback in our team meeting today. We completely understand it's super frustrating to expect to get a resolution, and then not have everything addressed by the end of Office Hours, especially after waiting for others to discuss their building questions.
We’ve offered Office Hours for several years now, with the aim of learning about and discussing Retool in a group. It began as an organic way to hop on and chat to get to know other people who are building and learning on Retool. It remains a space where sometimes users offer solutions to each other and work collaboratively to learn, in addition to Retool team members providing guidance and tips and tricks. More recently, as our user base and Office Hours attendees have grown, it's become even tougher to ensure everyone has a chance to get to all of their questions. Which leads us to:
Your feedback is really timely, because this week we've been discussing our plan to start sharing a survey with Office Hours participants to take in feedback as we plan improvements to our Office Hours in future months and 2025. We may break up office hours into different focuses, or separate out times for new users specifically, or something else based on users' perspectives.
Most similar companies don't offer live support unless a customer has an Enterprise plan. Office Hours has been a way for us to provide some availability for any and all plan levels, and we'd like to keep finding a way for this channel to work for folks and serve a useful purpose. That said, you've surfaced really valid points around why this can be tough to scale up to more and more users.
One other initiative that should improve the experience of getting to a resolution in the community is to more regularly re-surface unresolved topics in our product categories to the front page of community.retool.com, so that others in the community can see the thread is still open and chime in. We tested this in August and plan to implement it system-wide this quarter, which should boost visibility and engagement on open topics.
For your specific questions, I know we were able to get past one of the blockers but not the other…
I also invite others who may be MongoDB experts here in the community to chime in in parallel if you have suggestions.
Could you share the Query ID for the most recent run where you got a 502 error?
I can go into our cloud server's Datadog logs and check to see if we have more information on why this 502 Error is popping up
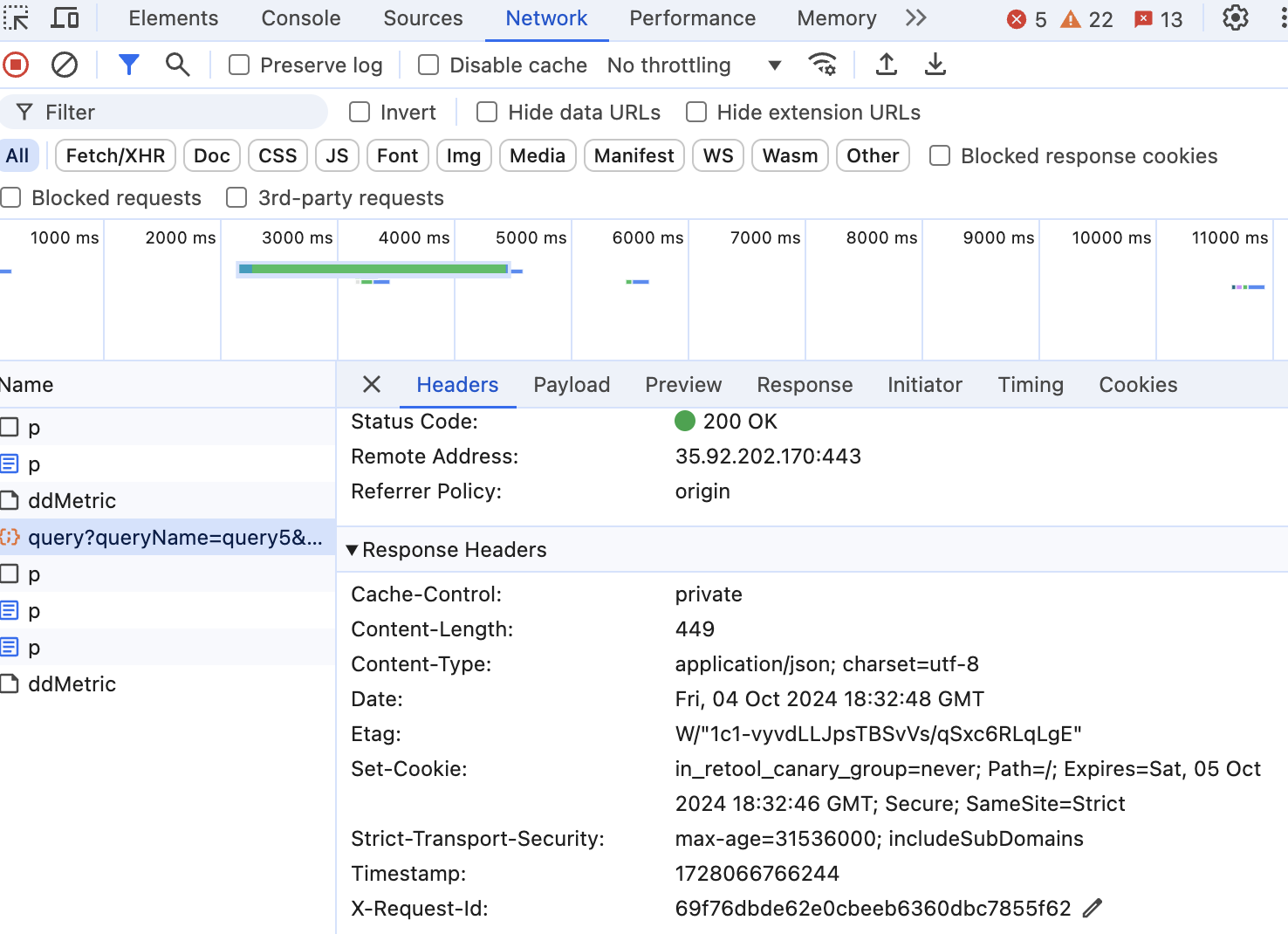
You can find the request ID from your bwosers inspect tool inside of networking. You will likely need to run the query from the app with the inspector open.
It will be under "X-Request-Id" as shown at the bottom of my screen shot below
Sorry it took me a while to get to this, I have been working on other things.
I will say that I am encouraged to hear that my feedback was taken seriously and discussed at a high-level. I hope that improvements will be swiftly implemented and that all users who show up to office hours are heard, even if it means that office hours have to be extended. My suggestion here is that you implement a cut-off time. All users who show up by 11:30 PT, should have an opportunity to discuss their issue, again, even if Retool team members have to stay past the official end. I believe that would be a fair interim support upgrade until more comprehensive changes are made. At least that is my perspective, for what it's worth.
Getting back to my issue. The query with the 502 error that I ran on 2024-10-12 at 22:18:17 GMT has a X-Request-Id of 6285bf2cffe90ad04b977ea55ed0b3b1. Let me know if there is any other info you need.
We are always looking for ways to improve so we appreciate any and all feedback.
Office hours has definitely been a bit of 'free flowing' process, but we are planning on standardizing our processes for handing high volume of live debugging as best we can.
Getting back to the issue of the 502 errors, thank you for providing the ID, we were able to look it up in our Datadog logs and pass a report over to our core data team.
What they told me was that the 502 is from dbconnection worker container that died during the request's response time.
They believe the worker died from an Out Of Memory issue. They suspect that you might be pulling in large amounts of data that we are unable to garbage collect. Wanted to double check with you on if the query you are running is something like a 'getAll' on large collection they confirmed that issue is specific to that collection as you had guessed before.
We are going to be doing further testing on what a max data limit would look like for Mongo queries to properly recommend batching/server side pagination when needed to keep the data load manageable.
Sorry for the delayed reply, I had a draft that I forgot to submit.
That collection in MongoDB is not even that large, only 5,933 records. Additionally, I added a projection to that query that only retrieves about 5 fields, so it's not the whole collection. I would not say that qualifies as a large dataset. I don't think I am out of memory...
Just told the engineering team this info so I am waiting to hear back on what we can do to either figure out how to keep the container pod from crashing.
Not sure what they are going to recommend and it doesn't seem like that number of records/fields would be enough to hit the memory limit but I would recommend testing with batching/smaller queries and see if you are able to find a threshold where the query succeeds/fails.
This would either confirm its a memory issue or if it never succeeds then we would likely need more details on what would could be causing the server to crash when you try to query this one collection