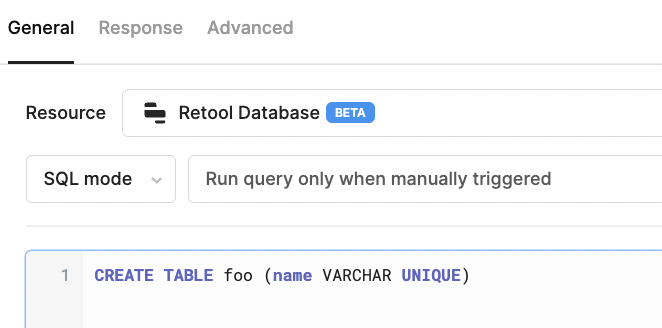
I have daily reports in CSV format that I want to upload via a file dropzone in an efficient way, and also protect myself against accidentally uploading duplicate data twice. I can get the former working, but don't have a solid strategy for the latter.
I've successfully hooked up a dropzone to a JavaScript Query that currently runs a bulk update query in GUI mode:
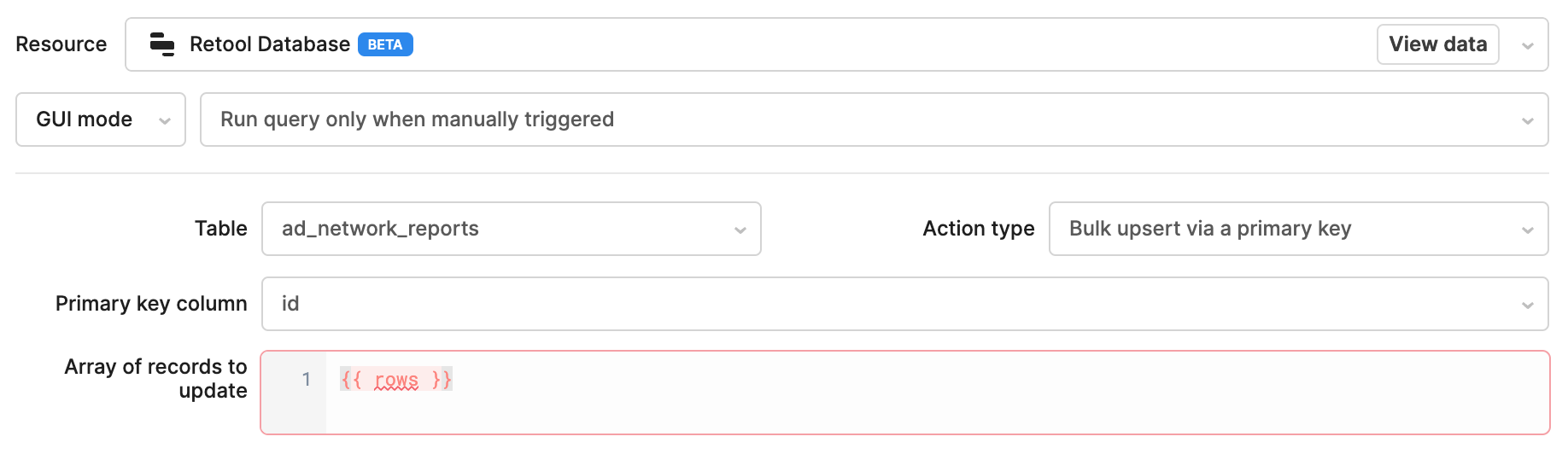
(Side Note 1: Since I'm passing data to this querty via additionalScope, the 'array of records to update' box is red, since it doesn't know rows until I trigger this query from elsehwere. Kinda annoying, but it still works).
An upload button triggers this JS query and loops through files int he dropzone to call the query above:
(async () => {
const reports = reportDropzone.parsedValue;
var totalRowCount = 0;
var reportCount = 0;
for(const report of Object.values(reports)) {
reportCount++;
const rows = transformReportFields(report);
uploadProgressText.setValue(`Uploading report #${reportCount} with ${rows.length} rows...)`);
await uploadReportRows.trigger({
additionalScope: { rows },
onSuccess: (data) => successCount++,
onFailure: (error) => console.error
});
}
uploadProgressText.value.setValue(`Done uploading. Addded ${successCount} rows from ${reportCount} reports)`);
reportDropzone.resetValue();
})();
(Side note 2: For some reason, when referenced inside a JS query, reportDropzone.parsedValue was not an arrray of arrays, but a nested object or objects, hence Object.values here. Weird)
The problem at this stage is that this will insert duplicates. It says 'upsert', but because my CSV files don't have a primary key field, if I run this on the same CSV file, it duplicates every row in the database.
I tried the 'Update a record, or create a new record if it doesn't exist' option, but this didn't work and the individual queries it created meant it only inserted a row per second (each CSV file has about 500-2000 rows). And I still got duplicates. Maybe I misunderstood the way the 'this filter by' section works, but I identified a combination of 4 fields that are basically a unqiue constraint and thought this would prevent duplicates:
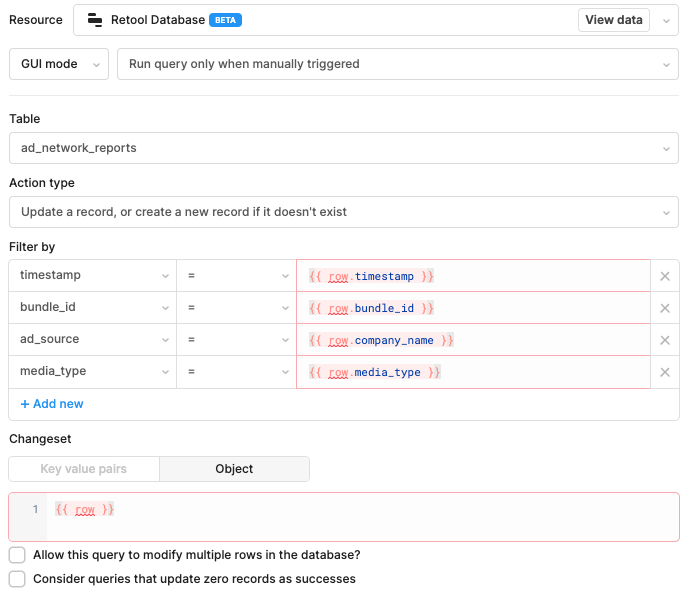
Unfortunately, since I'm using the beta Retool Database, I can't add a unque constraint on these 4 fields and then manually create SQL statements that contain ON CONFLICT e.g..
My next idea was to just generate a UUID based on these 4 fields in Retool. The same 4 strings should always generate the same UUID.
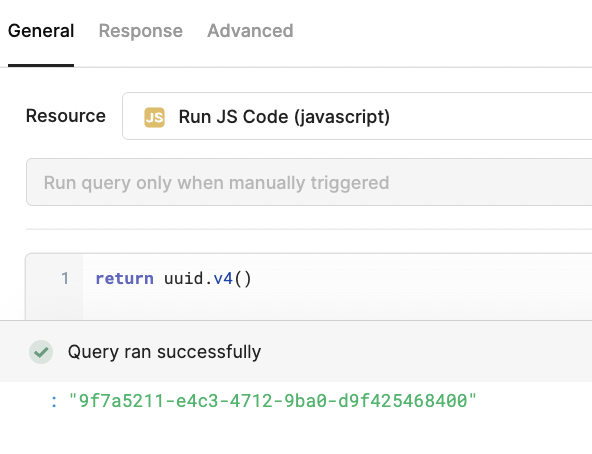
I thought I could just grab the CDN version of this npm module and run its getUuid function and pass it in a composite of those 4 fields, but I couldn't find a compatible CDN link for it (this didn't unclude a bundled version with all the dependencies).
I also couldn't call the existing uuid library on Retool, since the relevant v4 method e.g. was not working for me (even then, I'm not sure if it could take in string to produce a consistent UUID from the same string):
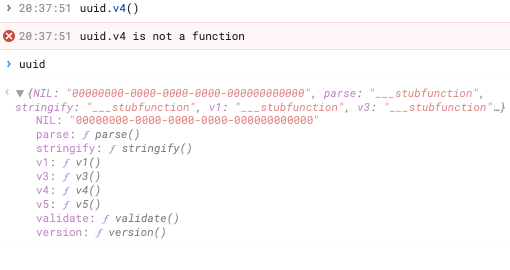
So, at this point, I'm still looking for some guidance on I could avoid duplicate rows for my use case, or generate a UUID form a string.
My fallback is to just query the database before the bulk insert, read in the current day's worth of data based on the date of the CSV data and identify existing rows this way before I even trigger uploadReportRows. That ought to work, just sounds a little clunky.
(Final side note: for some reason, that final part of my uploadReports JS query from above doesn't seem to run, since the progress text doesn't update and the dropzone doesn't reset:
uploadProgressText.value.setValue(`Done uploading. Addded ${successCount} rows from ${reportCount} reports)`);
reportDropzone.resetValue();
Not sure if this is some async await thing or what.