In recent weeks, multiple agents that had previously worked routinely (many invoked by scheduled workflows) have begun to fail with a variety of errors.
I’m conscious of the need to separate deterministic/non-deterministic functions, and the LLM call limits - but these are workflows which previously worked, and now do not.
I had specific, separate problems a few weeks ago with some Retool workflows invoked from agents - I think that the naming rules may have changed, and workflows with spaces in the names began to error - but this isn’t the cause of this issue.
Hey @leoncalverley thanks very much for calling this out. Is there any other information you can share? Do they fail 100% of the time, or inconsistently? Which models are you using? Have the inputs changed drastically (or at all?)?
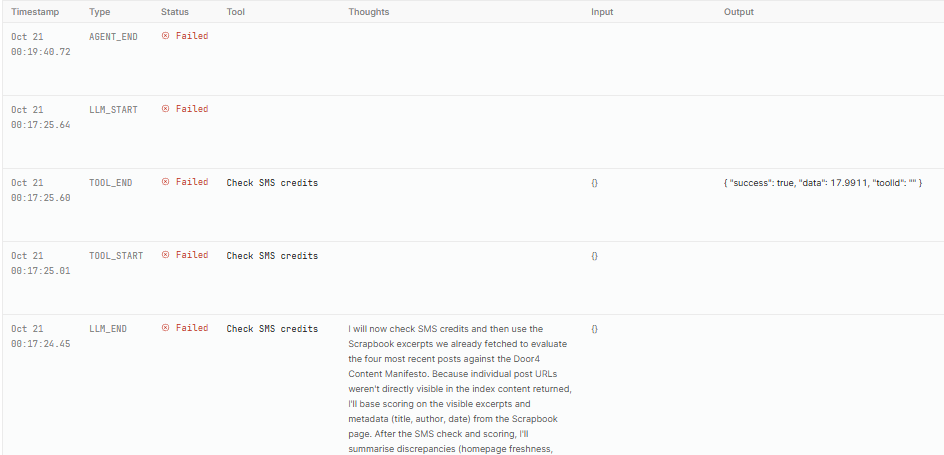
I’ve spotted that one weekly agent had failed on 10 Oct, and the 17 Oct.
I ran it from chat - and it failed.
I switched the model to Deepseek, and upped the max iterations from 10 to 40 (it had been working previously fine on 10 - I hadn’t changed this.)
It has now failed entirely again. It is triggered from a workflow. Each run leaves significant log activity - but zero indication of a cause for the failure.
I submitted a Retool support message to ask if there was a broader issue I needed to know about - and was directed to the Report a Breakage link - but that’s seemingly not for Agents, so my query was unanswered.
Added my Vertex API key - so switched to Google APIs for the first time - and it has failed again.
(Note: this agent was previously running smoothly, every week. No changes have been made)
Oh my goodness - yes, with 90% failure something is wrong. For what it’s worth, our overall error rate has decreased in the last month (and is, of course, much much lower than 90%) so this isn’t a platform-wide issue.
I switched the model to Deepseek
Which models were they before?
Would you be able to email me an export of your agent so we can take a look? Also, would you be willing to test a trivial agent (like one with an execute code tool and ask it to add two numbers) and let me know if that fails at all?