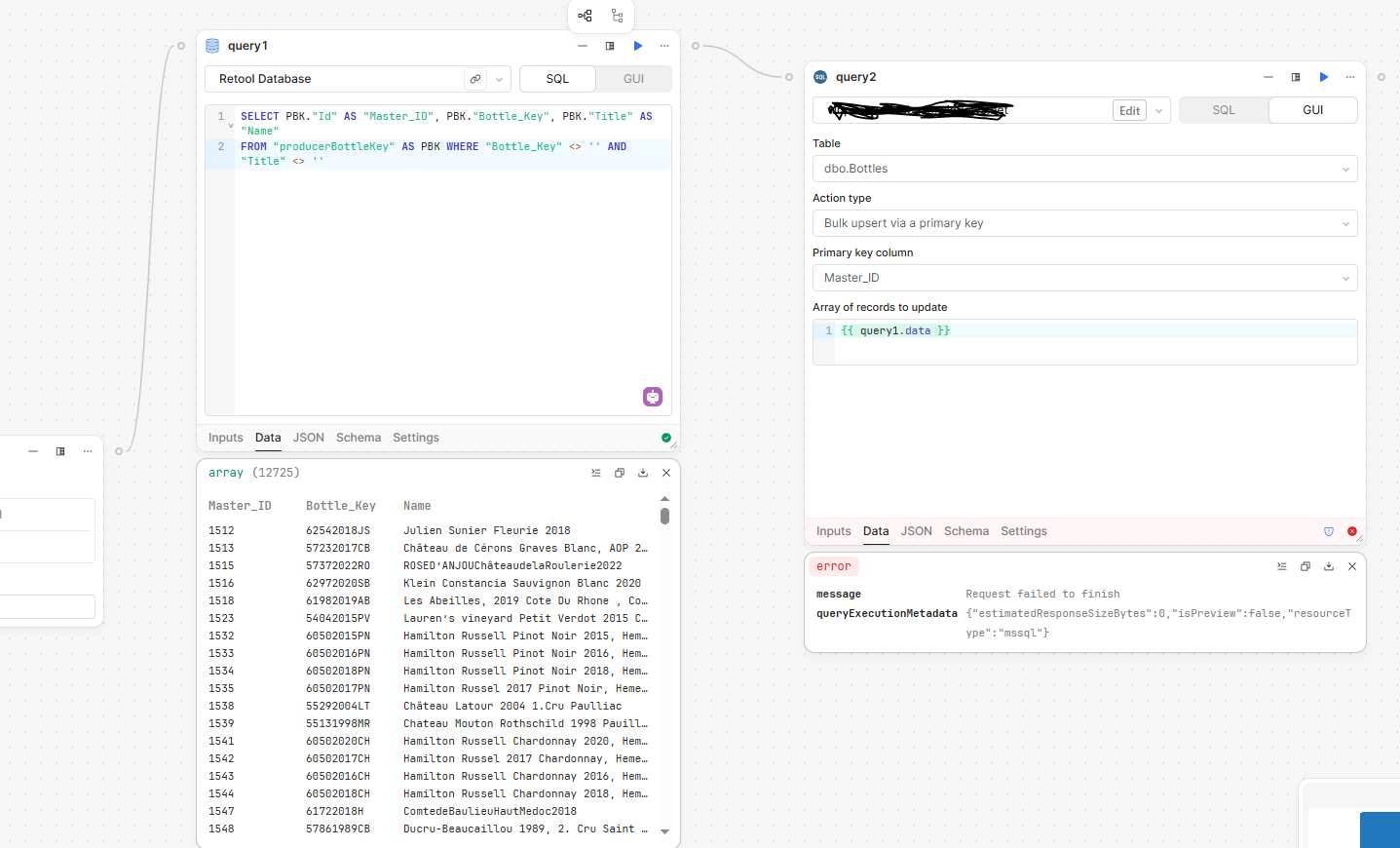
Azure SQL Server isn't my go to, but just thinking about this....from the error message, it seems like after the 2086th iteration enough of the connections from the previous loops were still open to cause an issue. So is it possible to open a single connection and run a bulk insert (and then explicitly close that connection)?
I don't have an environment to test this out, but maybe this something like (with a little help from an LLM):
// Install the mssql JS library and setup the Configuration Variables in your environment first
(async () => {
// 1) Load the mssql client
const sql = require('mssql'); // you installed the library, right?
// 2) Build config from the retoolContext.configVars you set up
const config = {
user: retoolContext.configVars.AZURE_SQL_USER,
password: retoolContext.configVars.AZURE_SQL_PASSWORD,
server: retoolContext.configVars.AZURE_SQL_SERVER, // e.g. 'myserver.database.windows.net'
database: retoolContext.configVars.AZURE_SQL_DATABASE, // e.g. 'MyDbName'
options: {
encrypt: true,
trustServerCertificate: false
},
pool: {
max: 10, //this code will only use one of these 10; they are lazily consumed, so doesn't automatically open 10
min: 0,
idleTimeoutMillis: 30000
}
};
// 3) Create a bulk‑insert function
async function bulkInsert(records) {
let pool;
try {
// Open (or reuse) the global pool
pool = await sql.connect(config);
// Define a Table matching your target table’s schema
const table = new sql.Table('YourTableName');
table.create = false; // table already exists, so you aren't actually creating one
// Add columns in the exact order/types as in your database
table.columns.add('Master_ID', sql.Int, { nullable: false });
table.columns.add('BottleKey', sql.NVarChar, { length: 200, nullable: true });
table.columns.add('Name', sql.NVarChar, { length: 200, nullable: true });
// …add additional columns here and make sure the above are right…
// Add a row for each record
for (const r of records) {
table.rows.add(
r.Master_ID,
r.BottleKey,
r.Name
// …other fields in same order…
);
}
// Fire one bulk operation
await pool.request().bulk(table);
console.log('Bulk insert succeeded for', records.length, 'rows');
} catch (err) {
console.error('Bulk insert error:', err);
throw err;
} finally {
// Close the pool when completely done
if (pool && pool.close) await pool.close();
}
}
const dataToInsert = query1.data; // your source array of {Master_ID, BottleKey, Name, …} objects
await bulkInsert(dataToInsert);
})();
Buyer beware - I'm just a guy spit balling an idea, but maybe (hopefully) this helps send you in a fruitful direction.
p.s. @lindakwoo underneath the covers, is Retool already doing something like this? Or is it more of an RBAR (for lack of better term) approach?