The Retool-managed Vectors DB dose indeed chunks the text. Though this happens automatically, it is still limited to the document's formatting (it is better to use a plain text document, and/or clear articles with headings and paragraphs).
This means that Retool AI models use embeddings to determine the meaning and connection between objects, such as blocks (chunks) of text.
In simple words, the AI model will decide which parts of the text can be grouped together into e.g: paragraphs, so that each chunk will be embedded into the DB separately, and therefore you can use them later to improve your prompt.
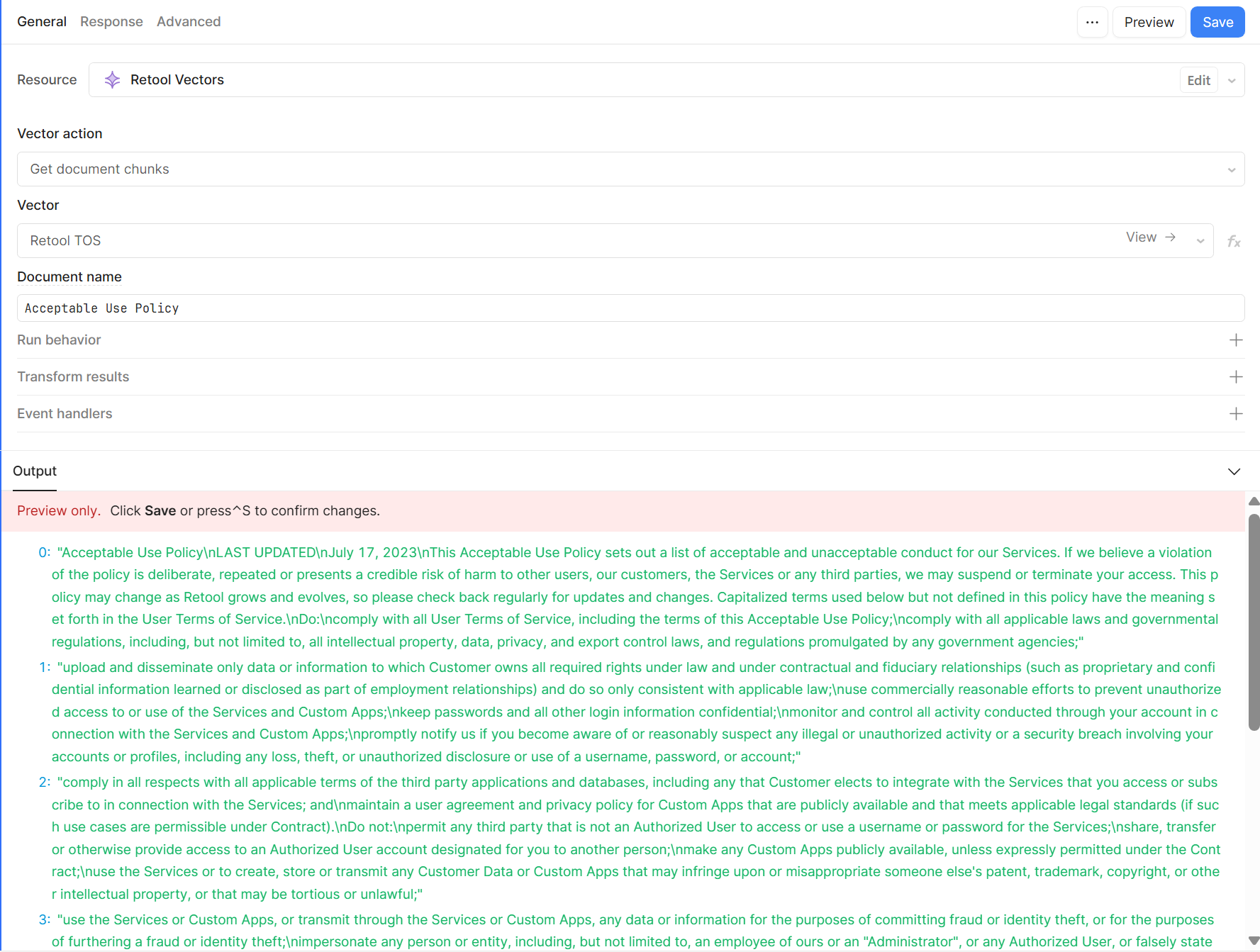
As in this screenshot, I've updated a simple text document, BUT it was inserted in multiple chunks (I've used the query "Get Document Chunks" to return the chunks of the document).
Hi Infinitybht and thank you for your response.
I uploaded documents in numerous different formats (including plain txt) and was also using Get document chunks to identify whether it was actually chunking the data. Unfortunately, it always returned 1 chunk.
My documents contained either:
Blocks of SQL with a short explanation above each query with line breaks between each section.
Blocks of SQL tables including name and fields.
I eventually pivoted and used the UpsertDoc function to create a new doc for each block, which was a painful endeavor, but my LLM is now working well with the granular chunks.
Any idea why this data would not chunk automatically? Here is a small example of the content:
Welcome to the community, @Steve7771! Thanks for reaching out. And thanks for providing some additional context, @Infinitybht.
This stumped me for a bit, as the behavior you're describing certainly wasn't aligning with the chunking algorithm as I last saw it. After talking to the team, though, I have some additional context. We updated the chunking algorithm relatively recently to take advantage of changes to the specific embedding models that we use. Previously, chunks were limited to 1-2k total characters but they are now capped at around ~30kb, which is in line with the maximum allowed by our models. A 2-3mb file, for example, will be chunked into ~80 pieces.
It's important to note that these changes shouldn't have any effect on the efficacy of your semantic searches! We did, however, find and fix an unrelated issue last week that specifically impacted documents with a small number of chunks. If you noticed any degradation in your RAG queries, it's possible that it was the actual culprit.
If you can, I'd recommend re-vectorizing your schema documents to verify that everything is working as expected.
Hi Darren, Thanks for the update. The workaround I originally used has been effective and I haven't had a chance to retry without it. Interested to see if it helps.
However, currently I'm kind of limited by this separate metadata issue.