Hello,
I’m having some trouble, and a quick overview of the problem:
I need to create a printable packing slip from an app I’ve created.
Using the utils.downloadPage() doesn’t work, because it turns the entire page into a single-page PDF, and for any packing slip with more than 20 items (in this case, the items are very small, so one box may fit hundreds of unique items) cannot be split into multiple pages - it can only be shrunk to fit a page, making the text unreadable.
I attempted to use the markdown pdf exporter as a native query type, but, even with markdown tables, it’s pretty useless as there is little to no control over the formatting and the users have said they’d rather create packing lists by hand.
So, in an effort to create a multi-page PDF that can be appropriately printed and have formatting necessary for a packing slip, I added jsPDF, along with html2canvas and dompurify as required for HTML conversion in the libraries section. So far so good, and a basic plain-text PDF succeeds using this.
However, trying to use the HTML to PDF conversion function generates a chain of javascript errors in the console, specifically all related to:
Uncaught (in promise) DOMException: Blocked a frame with origin "null" from accessing a cross-origin frame.
This comes from html2canvas. I’m assuming this is from html2canvas attempting to write to a canvas in a sandbox.
Here is a minimal example this triggers this condition:
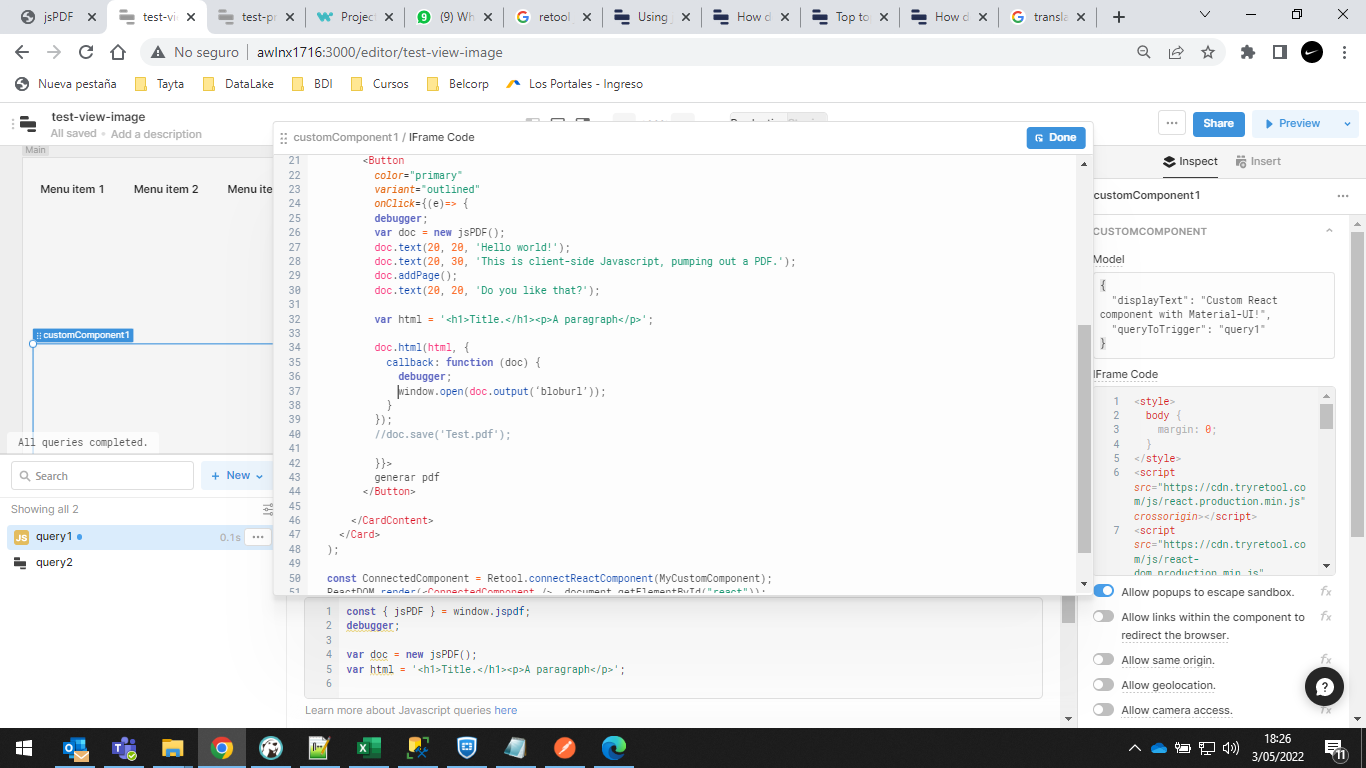
const doc = new jsPDF();
var html = '<h1>Title.</h1><p>A paragraph</p>';
doc.html(html, {
callback: function (doc) {
utils.downloadFile(doc.output(), 'testpdf', 'pdf');
}
});
Is there any way you guys know of that I could work around this, or if there is another way to resolve the printing issues discussed above?