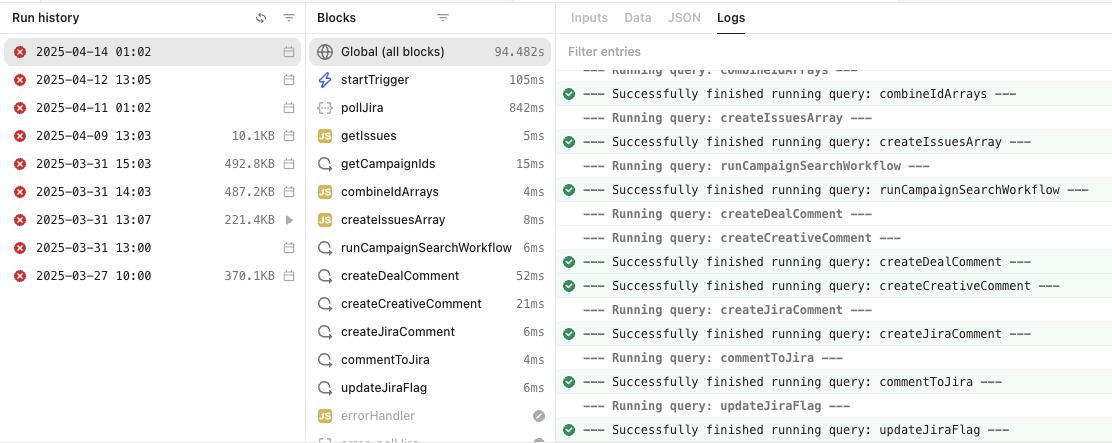
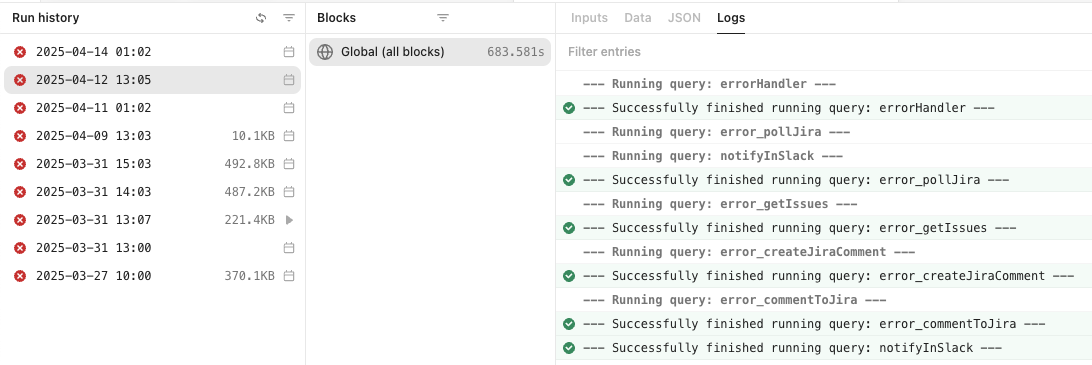
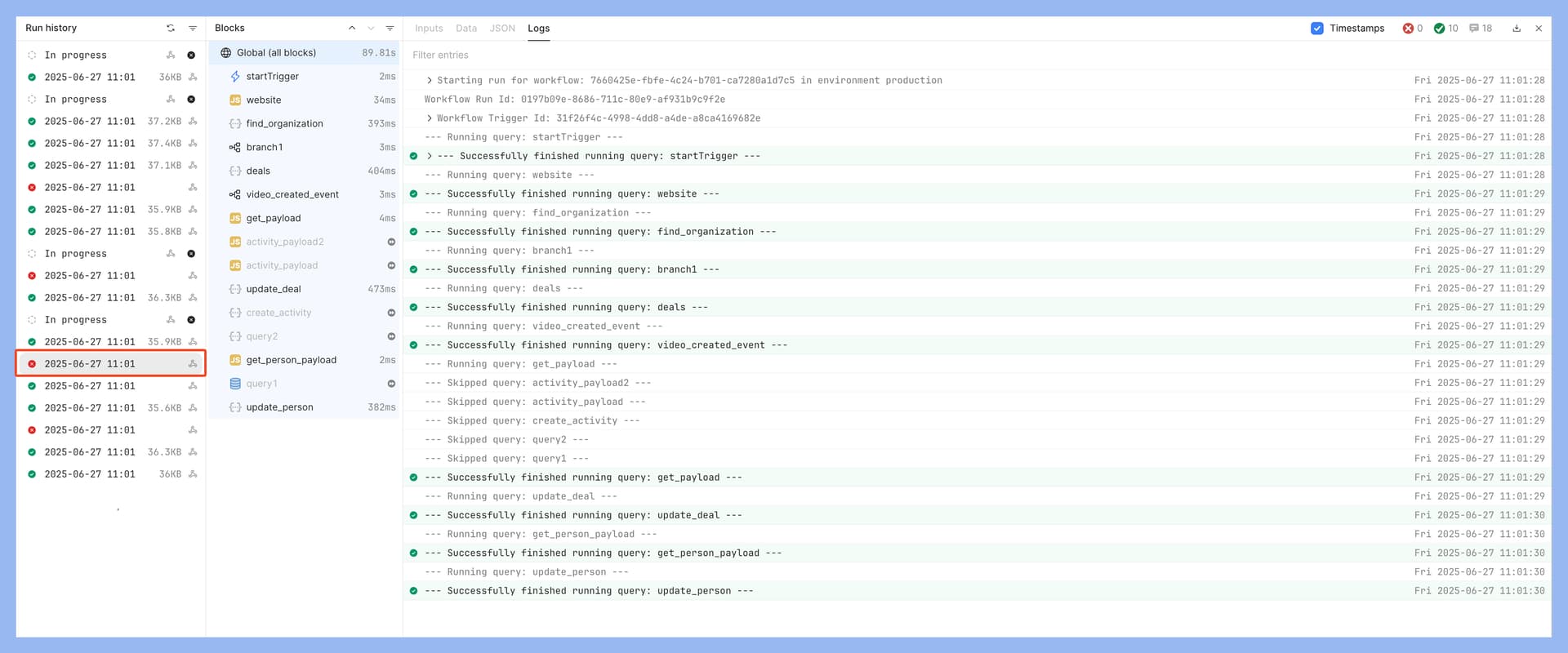
Issue: 2 separate failures occurred
- one failed but there is no sign of failure (looks like the workflow completed successfully. Error handler was not run)
For users on the cloud, if you can share workflow ids and workflow run ids we can check our logs to see if there are more details we can find to clear things up.
For self hosted users, can you share how your deployment is set up? The answer to that will determine which steps from the set up docs here I would recommend for you to double check that you have set up correctly.
If you can share a dump of your workflows container logs that I can share with our team we can better help to troubleshoot!
Hi @helio.costa thank you for sending me those. It looks like the workflows ran successfully from the server logs, which leads me to believe this is a frontend issue where the workflow logs in the app are incorrectly displaying a failed run when they work properly.
We also just pushed an patch to cloud that should have fixed this issue with workflows. If this is still happening for anyone let me know!
When you say it still happens, you are saying that randomly some workflows will show up as failing to run in the run logs but on inspection, all the blocks have completed successfully?
Are you able to add a response block to catch any errors?
The logs should appear once the workflow finishes, and once they are visible you should be able to see how much time each block too up. Is it taking longer for the logs to loan than the total time of all the steps in the flow?
That is very odd can you share with me the workflow ID and run ID for when the logs are empty?
One possible cause is memory limits, any chance this workflow is highly memory intensive?
Another possible reason is Webhook Return Blocks since Workflows with webhook return blocks don't upload logs until completion (for lower latency). If the workflow crashes before completing, logs won't be uploaded and will never be accessible.
Just got word back from our workflow engineers, they believe the issue is related to a pr that was a recently merged.
"We now skip loading logs from s3 blocks where the total size is > 20MB because it’s slow and uses resources on our side + it’ll likely crash on their side"
From the engineer looking at your logs, "And because it looks like all their logic is in 1 subflow (which I believe is stored in 1 s3 block) nothing ends up showing up".
The engineers are now working on adding in a warning message to let users know when this is occurring, so that the app will tell you when logs are being truncated.