I have built an app that is intended to automate the preparation of a document. It has approximately 150 separate components that are used to generate the document. Those components are spread across approximately 12 forms with each form located within a tabbed container.
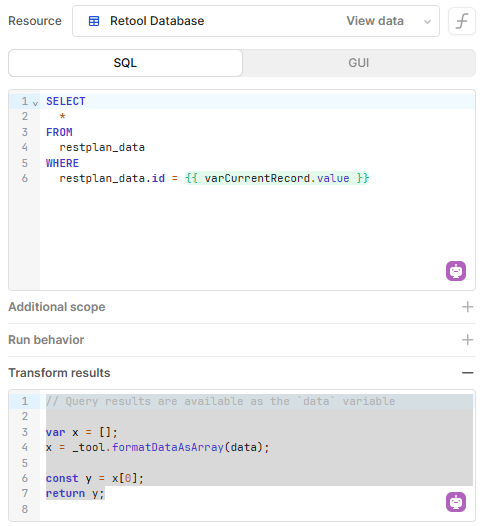
On app load and when editing an existing record, I pull all of the 150 or so columns for the single record, and format it as an array. For each form, I have a transformer that pulls just the relevant data that has changed and then posts the update. I am consistently getting slow query warnings:
I'm at a bit of a loss on how to address these errors. It seems like there is no way to avoid rewriting the whole of the database record (all 150 values) even if I'm submitting only 10 changes.
Should I write a separate query for each "form" and then write some logic to only run those queries when the associated form loads? Theoretically that would be faster, right?
These feel like pretty small datasets, am I just asking the Retool Database for too much?
I also forgot to mention that the qGetRecord gets triggered by qPostForm. It's done so that the form renders the proper values if revisited. So I end up on stacking those two queries back to back as I use my app.
Considering your query is data heavy if one record is taking 25 seconds to load some things that you can considering doing here:
addressing the architecture of the DB and how that record is stored, splitting it up, using appropriate DB column types
for auditing purposes and best practices you should be sending only the changeset as it will be more performant as well as easier to audit mishaps down the line. You can compare initial object to the object you're passing and just pass in the delta
//Example code might need some adjustments / optimizations based on your object
function getDifferences(obj1, obj2) {
// Helper function to check if a value is an object
const isObject = (val) => val && typeof val === 'object' && !Array.isArray(val);
// Recursive function to find differences
const findDifferences = (obj1, obj2) => {
const differences = {};
for (const key in obj2) {
if (isObject(obj2[key]) && isObject(obj1?.[key])) {
// Recurse for nested objects
const diff = findDifferences(obj1[key], obj2[key]);
if (Object.keys(diff).length > 0) {
differences[key] = diff;
}
} else if (Array.isArray(obj2[key]) && Array.isArray(obj1?.[key])) {
// Compare arrays
if (JSON.stringify(obj2[key]) !== JSON.stringify(obj1[key])) {
differences[key] = obj2[key];
}
} else if (obj2[key] !== obj1?.[key]) {
// Add if values are different
differences[key] = obj2[key];
}
}
return differences;
};
return findDifferences(obj1, obj2);
}
// Example usage
const original = {
name: "Alice",
age: 25,
address: { city: "New York", zip: "10001" },
hobbies: ["reading", "traveling"],
};
const modified = {
name: "Alice",
age: 26,
address: { city: "Los Angeles", zip: "90001" },
hobbies: ["reading", "sports"],
};
const differences = getDifferences(original, modified);
console.log(differences);
// Output: { age: 26, address: { city: "Los Angeles", zip: "90001" }, hobbies: ["reading", "sports"] }
Thanks for the suggestion. I'm currently using a transformer to determine what to post. Here's the code. It basically does this:
Grabs the form name and then the data associated with that form
Finds out what fields are hidden
Changes the value of any hidden fields to 0/null/etc.
The results of the transformer are then sent over to my query.
// Grab the current list of steps
const steps = {{ traSteps.value }};
// Find the active form name
const formName = steps.find(item => item.id === {{conInputs.currentViewIndex}})?.form;
const hiddenFields = {{ varHiddenFields.value }}
const fieldsToNullify = {{ traHiddenFieldList.value }};
var data = [];
// Populate the proper form data in each array
switch (formName) {
case "formProjectInfo":
data = {{ formProjectInfo.data }};
break;
case "formPermits":
data = {{ formPermits.data }};
break;
case "formImpacts":
data = {{ formImpacts.data }};
break;
case "formSpecies":
data = {{ formSpecies.data }};
break;
case "formPhotos":
data = {{ formPhotos.data }};
break;
case "formPreOEB":
data = {{ formPreOEB.data }};
break;
case "formPreRip":
data = {{ formPreRip.data }};
break;
case "formPreStream":
data = {{ formPreStream.data }};
break;
case "formPreWetland":
data = {{ formPreWetland.data }};
break;
case "formRestOEB":
data = {{ formRestOEB.data }};
break;
case "formRestRip":
data = {{ formRestRip.data }};
break;
case "formRestStream":
data = {{ formRestStream.data }};
break;
case "formRestVP":
data = {{ formRestVP.data }};
break;
case "formRestWetland":
data = {{ formRestWetland.data }};
break;
case "formMonitoring":
data = {{ formMonitoring.data }};
break;
default:
return "error";
}
Object.keys(data).forEach((key) => {
// Only modify data[key] if it's in fieldsToNullify
if (fieldsToNullify.includes(key)) {
// Look up the metadata for this key in hiddenFields
const fieldMeta = hiddenFields.find((f) => f.dbFieldName === key);
// If we don’t find a matching entry, skip
if (!fieldMeta) return;
// Now switch on the typeOf value instead of typeof val
switch (fieldMeta.typeOf) {
case "array":
data[key] = [];
break;
case "number":
data[key] = 0;
break;
case "string":
data[key] = "";
break;
case "boolean":
data[key] = false;
break;
case "object":
data[key] = {};
break;
// Include other cases if you have more types
default:
// If it's a type not listed, do nothing or handle it here
break;
}
}
});
return data;
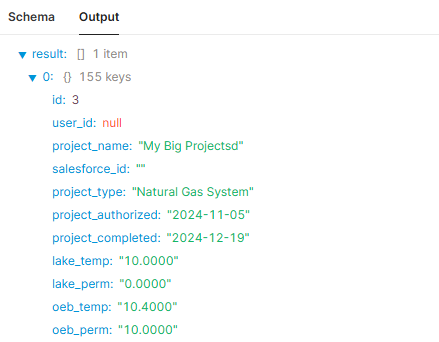
The output of my qPostForm seems to indicate that all 155 keys are being written:
Without too much context in the app I'd consider splitting the logic based on the page you're on and loading it just in time when it's needed (or most frequent ones).
Depending on your end users I would consider their workflow patterns and adjust to that as there seems to be a lot of transformation and processing going on at once which might be slowing down the app in specific places.
Really exciting project! Lots of moving pieces, let me see if I can give you some tips to help optimize your queries.
I second everything that @stefancvrkotic has said, lazy loading(or just in time loaded) will help reduce overhead and limit the queries to data that is urgently needed.
You should be able to have logic that will only update the rows that have. been changed by user interactions in the form component. This could be done by storing the initially fetched data in a temp variable, then on submit, iterating through the array of row data and only saving in the columns that do not match the initial data. Possibly using a .filter() method, chatGPT is very useful for JS like this.
Also to your point, Retool Database might not be the best option for complex and large amounts of data. Look into PostgreSQL as an alternative as there are further tooling for helping write more specific queries and better performance optimizations!
In this app, the user is only updating one record at a time. So I really have two choices:
Have a large table with all my data (e.g., 100 columns of data)
or
Have 1 parent table, then 9 additional tables linked by foreign key, all tables with 10 columns
In both scenarios, I have 100 columns of data (-ish, I realize we have added the keys in there too). If I post updates to two columns, will the operation be faster for option 1, option 2, or will they be the same?
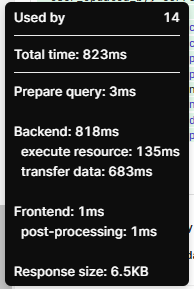
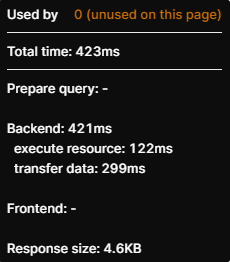
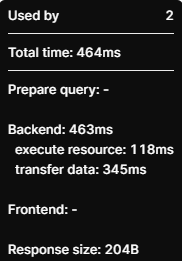
I ran a quick test
Option 1:
Option 2:
Other than the response size, these appear to be similar performing queries.
If that was the case, it would seem to make sense to do this:
Have one large table that stores all data (Option 1)
Have 10 separate "get" queries - one for each form in my app. That query acts as the data source for each form.
Have one "post" query - it searches for and only posts changes, then I rerun the applicable "get" query from that form (I already have a transformer that checks to see if the form is "dirty" by comparing form.data to form.initialData - I could just as easily filter out the matches and if length > 0 then dirty.
When I re-open the app and jump to the form I was last on, I can trigger the get query for that form, then trigger the other queries once the first one loads so that the data is then ready for use.
Does that strategy make sense? I really appreciate the help and advice here as I'm really new to this. I'm willing to explore other database solutions, but right now I'm in MVP stage and want to just get a well performing tool for UAT.
Interesting that your testing with both options are about the same
Given that neither option is currently more optimal in terms of speed, it seems you can work with either option. Back to Stephan's point, having the sub tables that only load when they are needed should be more optimal for the initial load time of the app.
But your strategy makes sense! The major bottlenecks are how much data comes in on page load and then how much data is being sent in the POST query to update and it sounds like you are aware of these and can address them accordingly.
If both queries are posting the same amount of data, they should take about the same amount of time regardless of how many columns are in the table that we are posting to, right?
When you say that neither option is "optimal in terms of speed," are we talking about load time or are we talking about posting data?
I'm using this on page load to limit my initial queries to only what I need (maybe 10 fields or so each (not the full 100):
const step = Number(url.searchParams.step); // Retrieve the step parameter
if (isNaN(step)) {
console.error("Invalid step value.");
return;
}
switch(step) {
case 0:
qGetInfo.trigger();
qGetPlan.trigger();
return;
case 1:
qGetPermits.trigger();
return;
case 2:
qGetImpacts.trigger();
return;
case 3:
qGetSpecies.trigger();
return;
case 4:
qGetPhotos.trigger();
return;
case 6:
qGetPreOEB.trigger();
return;
case 7:
qGetRipSpeciesRemove.trigger();
return;
case 12:
qGetRestOEB.trigger();
return;
case 13:
qGetRestRip.trigger();
return;
case 8:
qGetPreStream.trigger();
return;
case 14:
qGetRestStream.trigger();
return;
case 15:
qGetRestVP.trigger();
return;
case 10:
qGetPreWetland.trigger();
return;
case 16:
qGetRestWetland.trigger();
return;
case 17:
qGetMon.trigger();
return;
default:
return;
}
I then run this on success to load the other sub queries (if needed)
// Define a reusable function to process impacts
function processImpacts(data) {
const habitats = [];
if (parseFloat(data.lake_temp) + parseFloat(data.lake_perm) > 0) {
habitats.push("Lake");
}
if (parseFloat(data.oeb_temp) + parseFloat(data.oeb_perm) > 0) {
habitats.push("Ocean/Estuary/Bay");
}
if (parseFloat(data.rip_temp) + parseFloat(data.rip_perm) > 0) {
habitats.push("Riparian Zone");
}
if (parseFloat(data.stream_temp) + parseFloat(data.stream_perm) > 0) {
habitats.push("Stream Channel");
}
if (parseFloat(data.vp_temp) + parseFloat(data.vp_perm) > 0) {
habitats.push("Vernal Pool");
}
if (parseFloat(data.wetland_temp) + parseFloat(data.wetland_perm) > 0) {
habitats.push("Wetland");
}
return habitats;
}
const step = Number(url.searchParams.step); // Retrieve the step parameter and convert to integer
console.log("step: ", step);
//Checks to see if it's a number
if (isNaN(step)) {
console.error("Invalid step value.");
return;
}
// Trigger qGetInfo and qGetPlan if step > 0
if (step > 0) {
await qGetInfo.trigger();
await qGetPlan.trigger();
}
// Trigger qGetPermits if step > 1
if (step > 1) {
await qGetPermits.trigger();
}
// Trigger qGetImpacts if step > 2
if (step > 2) {
const qGetImpactsResult = await qGetImpacts.trigger();
// Process results of qGetImpacts
const habs = processImpacts(qGetImpactsResult);
console.log("habs: ", habs);
// If step > 3, trigger qGetSpecies
if (step > 3) {
await qGetSpecies.trigger();
}
// If step > 4, trigger qGetPhotos
if (step > 4) {
await qGetPhotos.trigger();
}
// Additional logic for "Ocean/Estuary/Bay"
if (habs.includes("Ocean/Estuary/Bay")) {
if (step > 6) {
await qGetPreOEB.trigger();
}
if (step > 12) {
await qGetRestOEB.trigger();
}
}
// Additional logic for "Riparian Zone"
if (habs.includes("Riparian Zone")) {
if (step > 7) {
await qGetRipSpeciesRemove.trigger();
}
if (step > 13) {
await qGetRestRip.trigger();
}
}
// Additional logic for "Stream Channel"
if (habs.includes("Stream Channel")) {
if (step > 8) {
await qGetPreStream.trigger();
}
if (step > 14) {
await qGetRestStream.trigger();
}
}
// Additional logic for "Vernal Pool"
if (habs.includes("Vernal Pool")) {
if (step > 15) {
await qGetRestVP.trigger();
}
}
// Additional logic for "Wetland"
if (habs.includes("Wetland")) {
if (step > 10) {
await qGetPreWetland.trigger();
}
if (step > 16) {
await qGetRestWetland.trigger();
}
}
}
// Trigger qGetPermits if step >= 17
if (step > 17) {
await qGetMon.trigger();
}
Yes you are correct, if they are posting the same data size payload it should be about the same.
There are lots of specifics about breaking up large queries into smaller ones, as smaller queries will run faster and be able to finish faster, with single slow queries having a slightly higher risk of 'timing out' if they are taking too long. Which is why we recommend using a 'batching' approach if users are getting 'query timeout' errors. But this does not seem to be the case for you currently, which is good.
What I was saying was the two queries you shared via screen shots of their performance seemed to both run at around mid 400ms. So I am not sure if those two queries from your testing screenshots are GET queries or POST queries.
Getting all the data should take a standard amount of time(unless broken up into smaller gets for the sub-tables), with the post time varying depending on if you are posting 100 fields worth of data vs 10 fields worth of data
You strategy looks like it makes sense to me for accomplishing your current objective
Also the perfect set of eyes to double check over code and queries to optimize is chatGPT. It can receive and hold a lot of info and offer helpful tips, it has been working better recently with Retool specific questions as well.