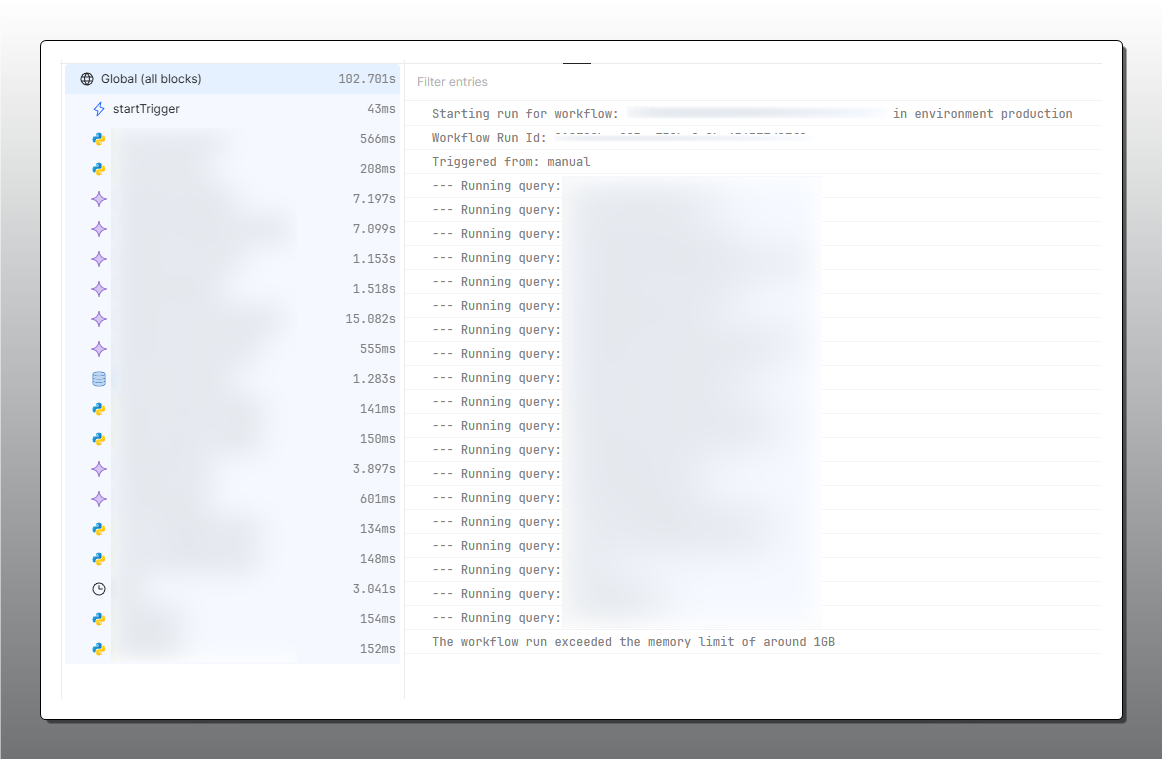
Hm maybe some of the steps could be broken out into subsequent workflows? It's a little hard to speak to restructuring the workflow without seeing the specific steps
The workflow is being triggered through a Retool App most of the time. Sometimes by hand. I was thinking maybe I am using the wrong ai models as I do not know the differene between the list of available models..
I see you have 5 AI blocks in a row, would you be able to share what they do and which model you're using? some of them might be able to be combined into 1 block. which model you use though shouldn't affect the how much memory is used since the model is actually ran somewhere else, so your context might be too large.
I see a database one, is that returning a whole row or just the necessary columns?
I have a block w 5k lines of Python, I'm using Pydantic AI + 18 other libraries, so I think the memory problem is in the return values of your blocks more than anything
I guess I should offer some tips to be a bit more helpful.
if you have an AI Block whos result value you only use once in a Python Block afterwards, move the AI Block to a function then call this function in your Python Block. This keeps the response value of the AI Block from being held in memory (the result of every block is held in memory until the workflow finishes).
you can do the same for Database calls if you need to return the whole row to do some post processing but in future blocks you only need a subset of the whole row, turn it into a function (or put it in the Query Library, then put it into a function). You can actually make 2 functions, 1 to make the DB call and a 2nd to use the 1st and process the results then return only what's needed (exactly how a transformer works, but workflows don't have those so we improvise).... then in the workflow block you would call the 2nd function, the 'transformer'.
I see instances where you have 2 Code Blocks running 1 after the other. I'm guessing one is to 'normalize' results and the other is to process the results? These could probably be combined then in the combined block you would reutrn a JSON object with your 'return' values.... this isn't saving a lot of memory, but depending on your Python/JS Configuration and libraries there could be lots of overhead every time you hit a Code Block.
the wait block.... i'm sure it affects like .01KB of memory, but how it's being used (personally, I've never used it so I'm just curious here) since everything runs linearly and synchronously (per block) wouldn't the wait just add uneccessary time to getting a response from the workflow?