Hi all,
I am new to Retool, but have a reasonable programming and debugging background; very excited with the platform!
I'm at a loss here; I have read several related posts on the forum and elsewhere for DOMParser usage, like:
here
or
here
This seems to work for other Retoolers and looks relatively simple, but I cannot make it work for me.
-
Goal: I am trying to access information from a web site which does not provide an API, so I am retrieving web pages as HMTL that I want to parse into DOM documents that I can manipulate as an object (document.getElementById(), etc.)
-
Steps:
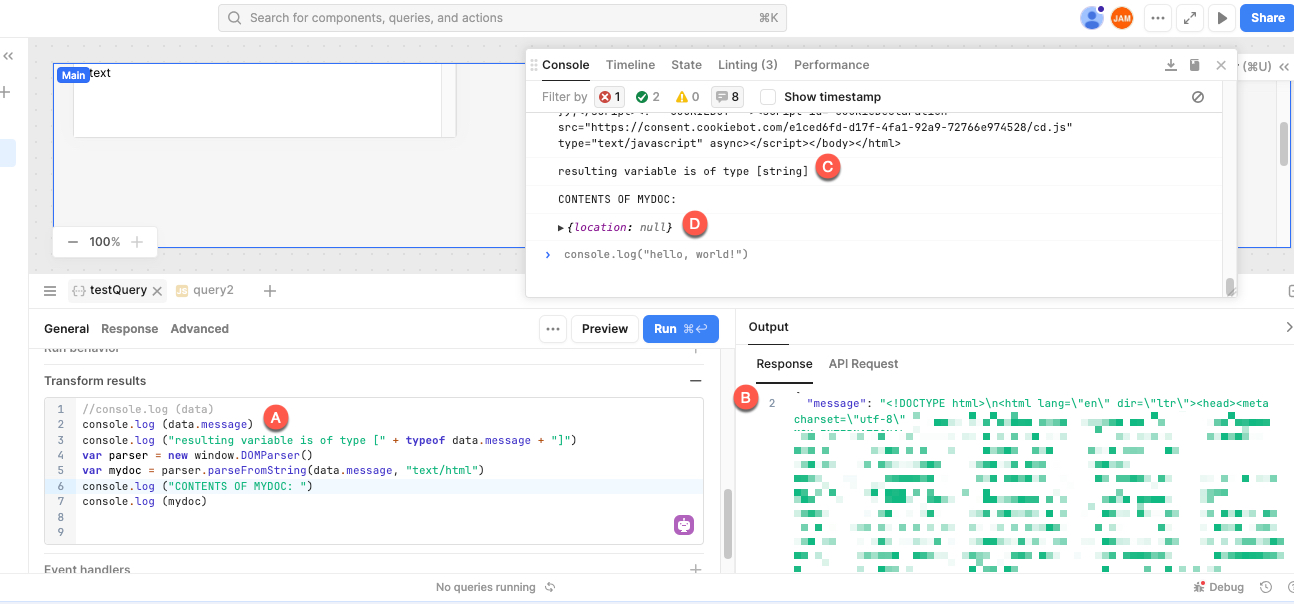
- I have defined a simple query resource in the form of a GET http request; I have then defined a query (let's call it testQuery) based on that resource; the query does work as expected, getting the full HTML of the target page. the actual content is returned in testQuery.data.message, and I can see it in the response window. (A and B in screenshot, sensitive contents sanitized)
- I have then coded a transformer in order to parse the HTML content. I can console.log the HTML content (in data.message) in the transformer. I also confirm data.message is of type string. (C in screenshot)
- I then initialize var myDocument = new DOMParser() object and use the parseFromString method with parameters data.message and type "text/html".
- the resulting document always returns {location: null} (D in screenshot)
- (I have also tried types "text/xml" and
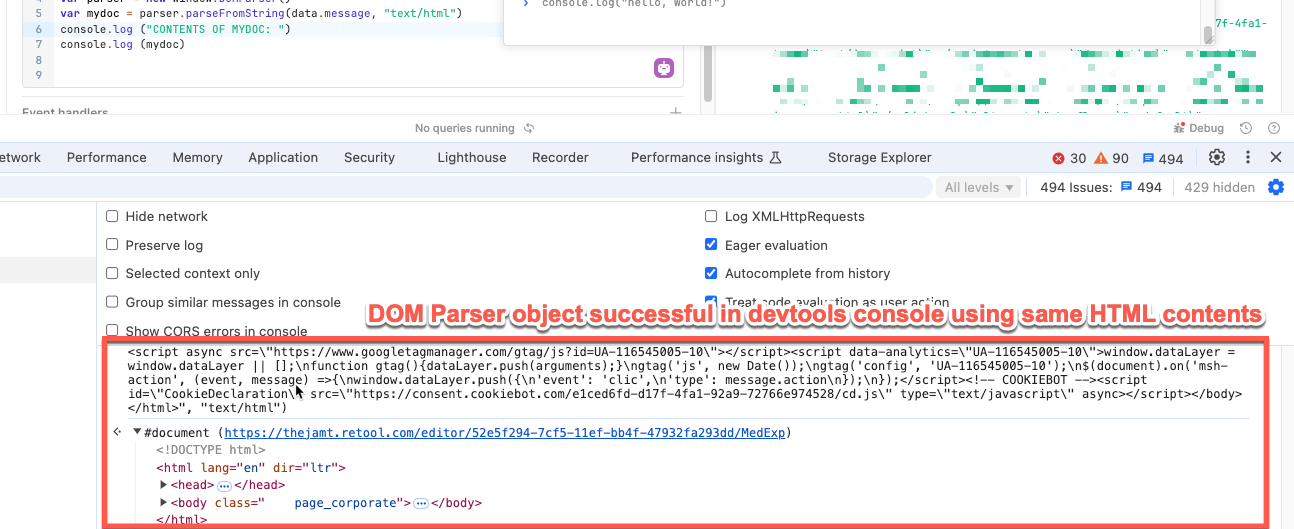
"application/xml" with same unsuccessful results) - Although the HTML content is rather long, I am sure it is not corrupt or non compliant, because i can successfully generate a DOM document from this content using DOMParser. parseFromString in the devtools console (second screenshot).
My feeling is the var mydoc = new DOMParser() statement does not initialize the expected object; I have also tried var mydoc = new window.DOMParser() with same unsuccessful results.
Thank you in advance for your time and advice!
- Screenshots: