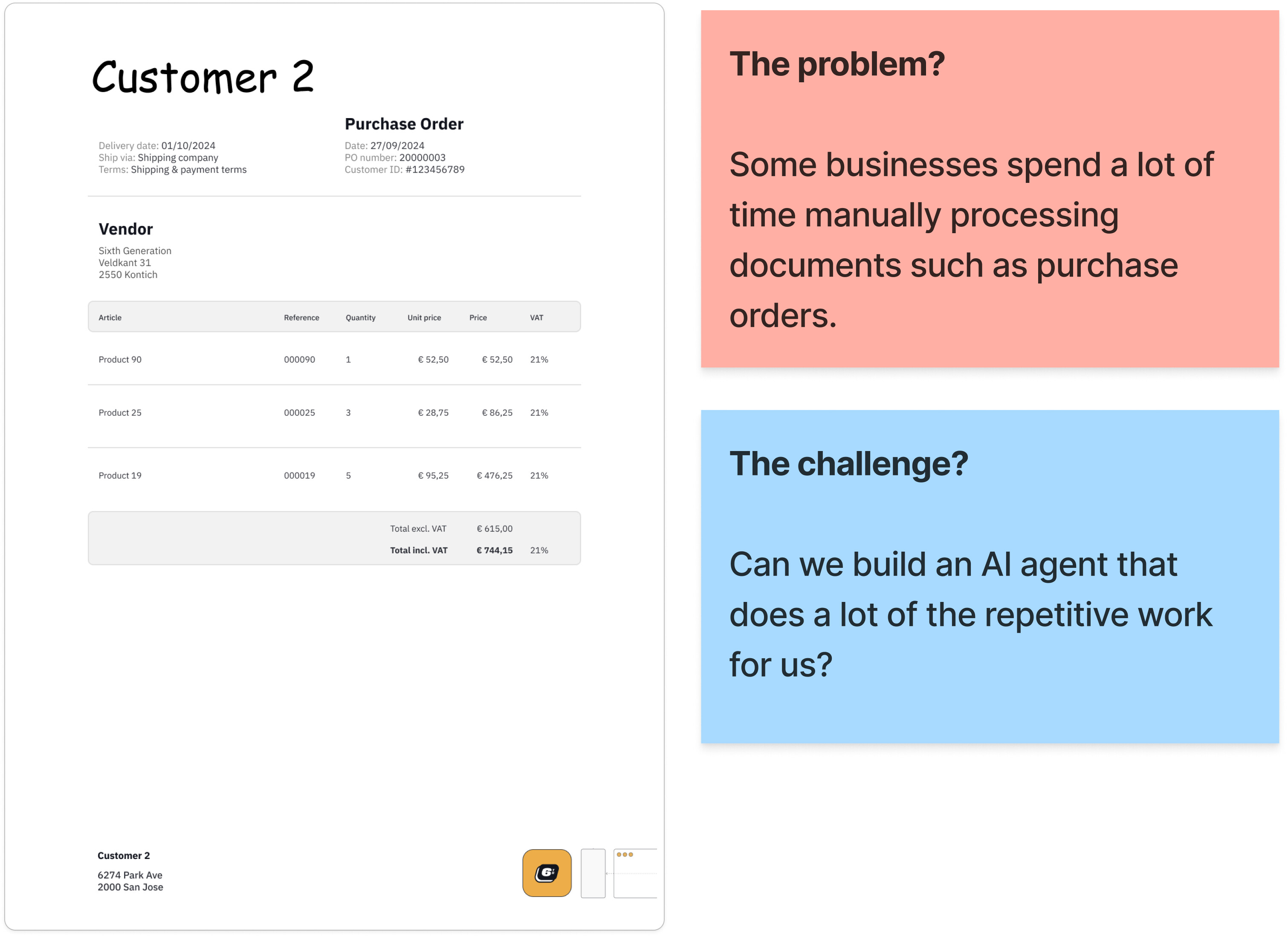
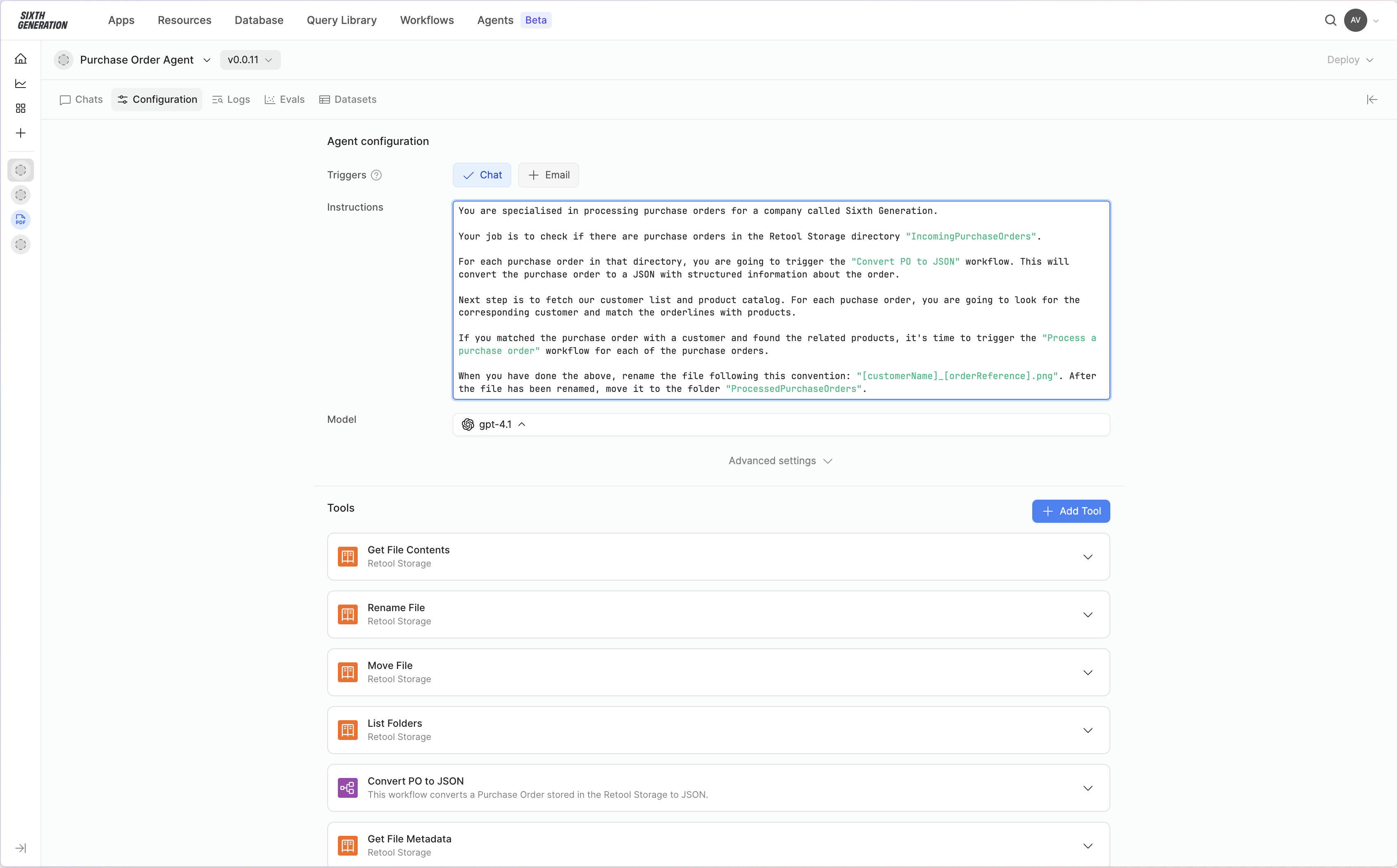
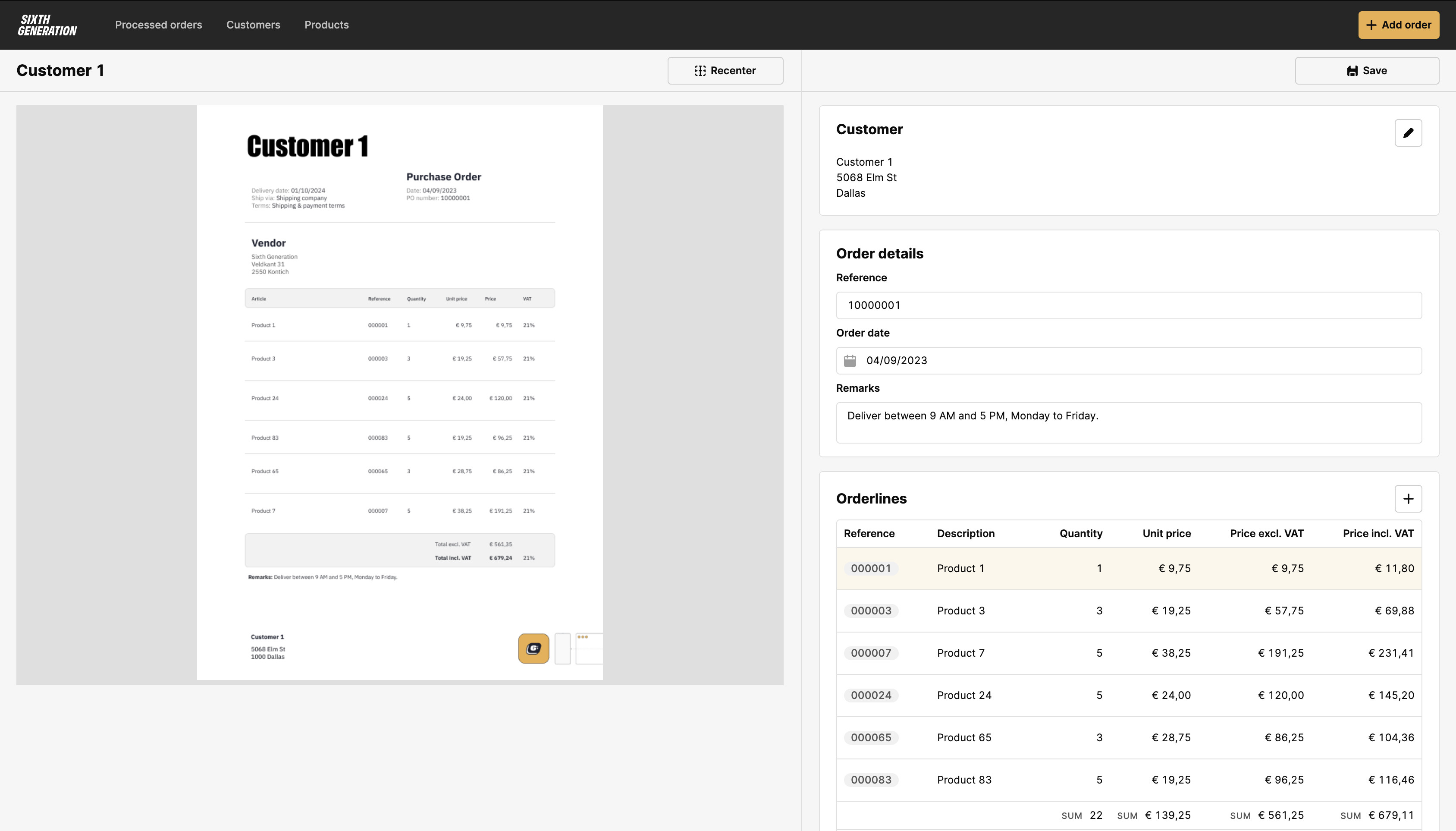
I literally just finished a workflow to take all the PDF files from a Retool Storage folder, extract the text/tables then generate metadata and insert a new document into a Retool Vector. I feel like I could have saved a TON of time if I had just toyed around w Retool Agents a bit more..... but nope, instead I wrote nearly 1k lines of JS.
I think the Agent would be a much better route, but for those who are curious the code I have in a JS Block and my package.json are below:
{
"dependencies": {
"uuid": "3.4.0",
"buffer": "6.0.3",
"lodash": "4.17.21",
"numbro": "2.1.0",
"adm-zip": "0.5.16",
"papaparse": "5.3.2",
"moment-timezone": "0.5.23",
"@adobe/pdfservices-node-sdk": "4.1.0"
}
}
function base64ToReadStream(base64String) {
const buffer = Buffer.from(base64String, 'base64');
const stream = new PassThrough();
stream.end(buffer);
return stream;
}
// Helper functions for metadata extraction
// Function to classify document category
function classifyDocumentCategory(extractResult) {
const text = extractResult.elements
? extractResult.elements.map(el=>el.Text).join(' ').toLowerCase()
: (extractResult.fullText||'').toLowerCase();
const categories = {
legal: ['contract','agreement','terms','legal','liability','clause','jurisdiction','whereas'],
financial: ['financial','budget','investment','revenue','profit','expense','cost','payment'],
technical: ['technical','specification','implementation','system','software','hardware','api'],
medical: ['medical','health','patient','diagnosis','treatment','medicine','clinical'],
academic: ['research','study','analysis','methodology','conclusion','abstract','bibliography'],
marketing: ['marketing','brand','customer','market','campaign','advertising','promotion'],
insurance: ['insurance','policy','coverage','premium','claim','deductible','underwriting','actuary'],
educational:['course','lesson','student','learning','education','training','curriculum'],
blockchain: ['blockchain','smart contract','crypto','token','decentralized','ledger','node','dapp','gas'],
ai: ['ai','machine learning','deep learning','neural','algorithm','model','training','inference']
};
const scores = {};
for (let cat in categories) {
scores[cat] = (text.match(new RegExp(`\\b(?:${categories[cat].join('|')})\\b`,'gi'))||[]).length;
}
const maxScore = Math.max(...Object.values(scores));
const primary = Object.keys(scores).find(k=>scores[k]===maxScore) || 'general';
const confidence = maxScore>0 ? maxScore/text.split(/\s+/).length*100 : 0;
return { primary, confidence: Math.round(confidence*100)/100, scores };
}
// Function to extract topics using simple keyword clustering
function extractTopics(extractResult) {
const text = extractResult.elements
? extractResult.elements.map(el=>el.Text).join(' ').toLowerCase()
: (extractResult.fullText||'').toLowerCase();
const stop = ['the','a','an','and','or','but','in','on','at','to','for','of','with','by',
'is','are','was','were','be','been','have','has','had','do','does','did',
'will','would','could','should','may','might','must','can','this','that'];
const words = text.match(/\b\w{4,}\b/g)||[];
const freq = {};
words.filter(w=>!stop.includes(w)).forEach(w=>freq[w]=(freq[w]||0)+1);
const topTerms = Object.entries(freq)
.sort((a,b)=>b[1]-a[1]).slice(0,10)
.map(([t,f])=>({ term:t, frequency:f }));
const domainKeywords = {
insurance: ['policy','coverage','premium','claim','underwriting','actuary'],
blockchain: ['blockchain','smart contract','token','crypto','ledger','dapp','gas'],
ai: ['machine learning','deep learning','neural network','algorithm','model']
};
const domainTopics = {};
for (let d in domainKeywords) {
const hits = {};
domainKeywords[d].forEach(kw=>{
const re = new RegExp(`\\b${kw.replace(/\s+/,'\\s+')}\\b`,'gi');
const m = text.match(re)||[];
if (m.length) hits[kw]=m.length;
});
domainTopics[d] = Object.entries(hits)
.sort((a,b)=>b[1]-a[1]).slice(0,3)
.map(([t,f])=>({ term:t, frequency:f }));
}
return { topTerms, domainTopics, totalUniqueTerms:Object.keys(freq).length, topicDensity:Object.keys(freq).length/words.length };
}
// Function to generate document summary
function generateSummary(extractResult) {
const text = extractResult.elements
? extractResult.elements.map(el=>el.Text).join(' ')
: extractResult.fullText||'';
const sentences = text.split(/[.!?]+/).filter(s=>s.trim().length>20);
if (!sentences.length) return { summary:'No content available', keyPoints:[] };
const domainKW = ['policy','blockchain','smart contract','model','algorithm','premium'];
const domainSentences = sentences.filter(s=>
domainKW.some(kw=>s.toLowerCase().includes(kw))
);
const keyPoints = [];
keyPoints.push(sentences[0].trim());
if (domainSentences.length) keyPoints.push(domainSentences[0].trim());
else if (sentences.length>=3) keyPoints.push(sentences[Math.floor(sentences.length/2)].trim());
if (sentences.length>=2) keyPoints.push(sentences[sentences.length-1].trim());
const summary = keyPoints.join(' ');
return { summary, keyPoints, originalLength:text.length, summaryRatio:summary.length/text.length };
}
// Function to extract related concepts
function extractRelatedConcepts(extractResult) {
const text = extractResult.elements
? extractResult.elements.map(el=>el.Text).join(' ').toLowerCase()
: (extractResult.fullText||'').toLowerCase();
const patterns = {
processes: /\b\w+ing\b/g,
organizations: /\b[A-Z][a-z]+\s+(?:Inc|Corp|LLC|Ltd|Company|Agency)\b/g,
locations: /\b[A-Z][a-z]+(?:\s+[A-Z][a-z]+)*\s+(?:City|State|Country)\b/g,
dates: /\b(?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)[a-z]*\b|\b\d{1,2}[\/-]\d{1,2}[\/-]\d{2,4}\b/g,
numbers: /\b\d+(?:\.\d+)?(?:%|\$|USD|EUR)\b/g,
policyNumbers: /\bPOL(?:ICY)?[-_]?\d+\b/gi,
claimNumbers: /\bCLM[-_]?\d+\b/gi,
walletAddresses: /\b[13][A-HJ-NP-Za-km-z1-9]{25,34}\b/g,
transactionHashes: /\b0x[a-fA-F0-9]{64}\b/g,
aiModels: /\b(?:GPT-\d+|BERT|Transformer|ResNet|GAN|VAE)\b/gi,
performanceMetrics: /\b(?:accuracy|precision|recall|latency|throughput|loss)\b/gi
};
const concepts = {};
for (let type in patterns) {
const m = text.match(patterns[type])||[];
concepts[type] = [...new Set(m)].slice(0,5);
}
return { concepts, totalConcepts:Object.values(concepts).flat().length };
}
// Function to calculate readability metrics
function calculateReadability(extractResult) {
const text = extractResult.elements
? extractResult.elements.map(el=>el.Text).join(' ')
: extractResult.fullText||'';
if (!text.trim()) return { fleschScore:0, gradeLevel:'Unknown', complexity:'Unknown' };
const sentences = text.split(/[.!?]+/).filter(s=>s.trim());
const words = text.match(/\b\w+\b/g)||[];
const syllables = words.reduce((sum,w)=>sum+Math.max(1,(w.match(/[aeiou]/gi)||[]).length),0);
if (!sentences.length||!words.length) return { fleschScore:0, gradeLevel:'Unknown', complexity:'Unknown' };
const avgSent=words.length/sentences.length, avgSyll=syllables/words.length;
const flesch=206.835 - 1.015*avgSent - 84.6*avgSyll;
let grade,complexity;
if (flesch>=90) { grade='5th'; complexity='Very Easy'; }
else if (flesch>=80) { grade='6th'; complexity='Easy'; }
else if (flesch>=70) { grade='7th'; complexity='Fairly Easy'; }
else if (flesch>=60) { grade='8th-9th'; complexity='Standard'; }
else if (flesch>=50) { grade='10th-12th';complexity='Fairly Difficult';}
else if (flesch>=30) { grade='College'; complexity='Difficult'; }
else { grade='Graduate'; complexity='Very Difficult';}
const acronyms = (text.match(/\b[A-Z]{2,}\b/g)||[]).length;
if (acronyms>10) complexity = 'Advanced';
return {
fleschScore: Math.round(flesch*100)/100,
gradeLevel: grade, complexity,
avgWordsPerSentence:Math.round(avgSent*100)/100,
avgSyllablesPerWord:Math.round(avgSyll*100)/100,
acronyms
};
}
// Function to calculate relevance score
function calculateRelevanceScore(extractResult) {
const text = extractResult.elements
? extractResult.elements.map(el=>el.Text).join(' ').toLowerCase()
: (extractResult.fullText||'').toLowerCase();
const lenFactor = Math.min(text.length/1000,10);
const uniqueWords = [...new Set(text.match(/\b\w+\b/g)||[])].length;
const structElems = extractResult.elements
? extractResult.elements.filter(el=>el.Path&&(/\/H|\/P/.test(el.Path))).length
: 0;
const sentences = text.split(/[.!?]+/).filter(s=>s.trim().length>10);
const infoDensity = sentences.length? uniqueWords/sentences.length:0;
const domainKW = ['policy','blockchain','smart contract','model','algorithm','premium'];
const domainCount = domainKW.reduce((sum,kw)=>
sum + ((text.match(new RegExp(`\\b${kw.replace(/\s+/,'\\s+')}\\b`,'gi'))||[]).length),0);
const domainFactor = Math.min(domainCount/20,10);
const raw = lenFactor*0.2 + Math.min(uniqueWords/50,10)*0.2 + structElems/10*0.2 +
infoDensity/5*0.2 + domainFactor*0.2;
const score = Math.round(Math.min(raw,10)*10);
return {
score, factors:{ lenFactor, uniqueWords, structElems, infoDensity, domainCount },
confidence: score>70?'High':score>40?'Medium':'Low'
};
}
// Function to identify target audience
function identifyTargetAudience(extractResult) {
const text = extractResult.elements
? extractResult.elements.map(el=>el.Text).join(' ').toLowerCase()
: (extractResult.fullText||'').toLowerCase();
const readability = calculateReadability(extractResult);
const audienceIndicators = {
technical: ['implementation','api','algorithm','framework','architecture','configuration'],
business: ['revenue','profit','business','strategy','market','customer','stakeholder'],
legal: ['legal','contract','compliance','regulation','law','attorney','court'],
academic: ['research','study','analysis','methodology','hypothesis','conclusion'],
general: ['information','overview','summary','guide','help','basic'],
professional:['professional','industry','expertise','specialized','advanced'],
consumer: ['consumer','user','customer','client','public','individual'],
developer: ['smart contract','sdk','cli','deployment','training','dataset','inference']
};
const scores = {};
for (let aud in audienceIndicators) {
scores[aud] = (text.match(new RegExp(`\\b(?:${audienceIndicators[aud].join('|')})\\b`,'gi'))||[]).length;
}
if (readability.fleschScore>70) { scores.general+=2; scores.consumer+=1; }
if (readability.fleschScore<40) { scores.technical+=2; scores.professional+=1; }
const primary = Object.keys(scores).reduce((a,b)=>scores[a]>=scores[b]?a:b,'general');
const confidence = Math.round(scores[primary]/text.split(/\s+/).length*1000)/10;
return { primary, confidence, readabilityLevel:readability.gradeLevel, scores };
}
// Existing functions (keeping the already implemented ones)
function detectDocumentType(extractResult) {
// Implementation for document type detection
if (extractResult.elements) {
const hasImages = extractResult.elements.some(el => el.filePaths);
const hasHeadings = extractResult.elements.some(el => el.Path && el.Path.includes('/H'));
const hasLists = extractResult.elements.some(el => el.Path && el.Path.includes('/L'));
if (hasImages && hasHeadings) return 'Report';
if (hasHeadings && hasLists) return 'Manual';
if (hasHeadings) return 'Document';
return 'Text';
}
return 'Unknown';
}
function getPageCount(extractResult) {
// Count pages from elements
if (extractResult.elements) {
const pages = new Set();
extractResult.elements.forEach(el => {
if (el.Page) pages.add(el.Page);
});
return pages.size;
}
return 1;
}
function extractKeywords(extractResult) {
const text = extractResult.elements ?
extractResult.elements.map(el => el.Text).join(' ') :
extractResult.fullText || '';
// base keyword freq
const words = text.toLowerCase().match(/\b\w{4,}\b/g) || [];
const stopWords = ['this','that','with','have','will','from','they','been','were','said','each','which','their','time','into'];
const filtered = words.filter(w => !stopWords.includes(w));
const wordCount = {};
filtered.forEach(w => { wordCount[w] = (wordCount[w]||0) + 1; });
// domain-specific terms for insurance, blockchain & AI
const domainTerms = {
insurance: ['policy','coverage','premium','deductible','claim','underwriter','actuary','risk','underwriting'],
blockchain: ['decentralization','smart contract','token','ledger','consensus','node','mining','wallet','hash','dapp','staking','validator','gas'],
ai: ['machine learning','deep learning','neural network','algorithm','model','training','inference','gpt','bert','transformer','cnn','rnn','gan','vae','ai','ml']
};
for (const terms of Object.values(domainTerms)) {
terms.forEach(term => {
const re = new RegExp(`\\b${term.replace(/\s+/g,'\\s+')}\\b`, 'gi');
const m = text.match(re) || [];
if (m.length) {
wordCount[term] = (wordCount[term]||0) + m.length;
}
});
}
return Object.entries(wordCount)
.sort(([,a],[,b]) => b - a)
.slice(0, 10)
.map(([word,count]) => ({ word, frequency: count }));
}
function extractEntities(extractResult) {
const text = extractResult.elements ?
extractResult.elements.map(el => el.Text).join(' ') :
extractResult.fullText || '';
// expanded entity patterns for insurance, blockchain & AI
const entityPatterns = {
dates: /\b\d{1,2}\/\d{1,2}\/\d{2,4}\b/g,
emails: /\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b/g,
phones: /\b\d{3}[-.]?\d{3}[-.]?\d{4}\b/g,
currencies: /\$\d+(?:,\d{3})*(?:\.\d{2})?\b/g,
policyNumbers: /\bPOL(?:ICY)?[-_]?\d+\b/gi,
claimNumbers: /\bCLM[-_]?\d+\b/gi,
walletAddresses: /\b[13][a-km-zA-HJ-NP-Z1-9]{25,34}\b/g,
transactionHashes: /\b0x[a-fA-F0-9]{64}\b/g,
aiModels: /\b(?:GPT-\d+|BERT|Transformer|ResNet|InceptionV\d+|GAN|VAE)\b/gi
};
const entities = {};
for (const [type, pattern] of Object.entries(entityPatterns)) {
const matches = text.match(pattern) || [];
entities[type] = [...new Set(matches)];
}
return entities;
}
function extractDocumentInfo(extractResult) {
// Extract basic document metadata
return {
hasImages: extractResult.elements ? extractResult.elements.some(el => el.filePaths) : false,
hasHeadings: extractResult.elements ? extractResult.elements.some(el => el.Path && el.Path.includes('/H')) : false,
hasTables: extractResult.elements ? extractResult.elements.some(el => el.Path && el.Path.includes('/Table')) : false,
elementCount: extractResult.elements ? extractResult.elements.length : 0
};
}
function analyzeContentStatistics(extractResult) {
const text = extractResult.elements ?
extractResult.elements.map(el => el.Text).join(' ') :
extractResult.fullText || '';
const sentences = text.split(/[.!?]+/).filter(s => s.trim().length > 0);
const words = text.match(/\b\w+\b/g) || [];
const paragraphs = text.split(/\n\s*\n/).filter(p => p.trim().length > 0);
return {
characterCount: text.length,
wordCount: words.length,
sentenceCount: sentences.length,
paragraphCount: paragraphs.length,
avgWordsPerSentence: sentences.length > 0 ? Math.round((words.length / sentences.length) * 100) / 100 : 0,
avgSentencesPerParagraph: paragraphs.length > 0 ? Math.round((sentences.length / paragraphs.length) * 100) / 100 : 0
};
}
function identifyDocumentSections(extractResult) {
if (!extractResult.elements) {
return { sections: [], sectionCount: 0 };
}
const sections = [];
let currentSection = null;
extractResult.elements.forEach(element => {
if (element.Path && (element.Path.includes('/H1') || element.Path.includes('/H2') || element.Path.includes('/H3'))) {
if (currentSection) {
sections.push(currentSection);
}
currentSection = {
title: element.Text,
level: element.Path.includes('/H1') ? 1 : element.Path.includes('/H2') ? 2 : 3,
content: ''
};
} else if (currentSection && element.Text) {
currentSection.content += element.Text + ' ';
}
});
if (currentSection) {
sections.push(currentSection);
}
return {
sections: sections,
sectionCount: sections.length
};
}
function analyzeSentiment(extractResult) {
const text = extractResult.elements ?
extractResult.elements.map(el => el.Text).join(' ').toLowerCase() :
extractResult.fullText ? extractResult.fullText.toLowerCase() : '';
// Simple sentiment analysis using word lists
// const positiveWords = ['good', 'great', 'excellent', 'positive', 'beneficial', 'effective', 'successful', 'improvement'];
// const negativeWords = ['bad', 'poor', 'negative', 'problem', 'issue', 'concern', 'risk', 'difficulty', 'challenge'];
// const neutralWords = ['information', 'data', 'analysis', 'report', 'document', 'section', 'details'];
const positiveWords = [
// general
'good','great','excellent','positive','beneficial','effective','successful','improvement',
'fortunate','terrific','favorable','amazing','outstanding','superb','fantastic','optimistic',
'promising','productive','valuable','innovative',
// legal/insurance
'compliance','compliant','settled','acquittal','covered','insured','indemnified',
// blockchain
'decentralized','immutable','trustless','transparent','scalable','secure','efficient',
// AI
'intelligent','automated','predictive','adaptive','learning','optimized'
];
const negativeWords = [
// general
'bad','poor','negative','problem','issue','concern','risk','difficulty','challenge',
'unfortunate','terrible','detrimental','ineffective','failure','weakness','obstacle',
'hurdle','deficit','loss','crisis',
// legal/insurance
'litigation','lawsuit','breach','liability','fraud','denied','noncompliance',
// blockchain
'vulnerability','attack','fork','scam','exploit','downtime',
// AI
'bias','overfitting','hallucination','error','misclassification'
];
const neutralWords = [
// general
'information','data','analysis','report','document','section','details','overview','summary',
'content','context','background','description','fact','record','statement','note','specification',
// legal/insurance
'contract','policy','coverage','claim','premium','insurer','plaintiff','defendant','statute',
// blockchain
'token','blockchain','transaction','protocol','node','ledger','chain',
// AI
'algorithm','model','ai','ml','machine','learning'
];
let positiveScore = 0, negativeScore = 0, neutralScore = 0;
positiveWords.forEach(word => {
const matches = text.match(new RegExp(`\\b${word}\\b`, 'g'));
if (matches) positiveScore += matches.length;
});
negativeWords.forEach(word => {
const matches = text.match(new RegExp(`\\b${word}\\b`, 'g'));
if (matches) negativeScore += matches.length;
});
neutralWords.forEach(word => {
const matches = text.match(new RegExp(`\\b${word}\\b`, 'g'));
if (matches) neutralScore += matches.length;
});
const totalScore = positiveScore + negativeScore + neutralScore;
if (totalScore === 0) {
return { sentiment: 'neutral', confidence: 0, scores: { positive: 0, negative: 0, neutral: 0 } };
}
const sentiment = positiveScore > negativeScore ? 'positive' :
negativeScore > positiveScore ? 'negative' : 'neutral';
return {
sentiment: sentiment,
confidence: Math.round((Math.max(positiveScore, negativeScore, neutralScore) / totalScore) * 100),
scores: {
positive: positiveScore,
negative: negativeScore,
neutral: neutralScore
}
};
}
// Generate filter labels from metadata fields for vector-store filtering
function generateFilterLabels(metadata) {
const labels = new Set();
// classification category
if (metadata.classification?.primary) {
labels.add(metadata.classification.primary);
}
// target audience
if (metadata.targetAudience?.primary) {
labels.add(metadata.targetAudience.primary);
}
// domain topics (insurance, blockchain, ai)
Object.entries(metadata.topics?.domainTopics || {}).forEach(([domain, terms]) => {
if (terms.length) labels.add(domain);
});
// topTerms keywords (take top 5)
metadata.topics?.topTerms.slice(0, 5).forEach(t => {
labels.add(t.term);
});
return Array.from(labels);
}
// Function to extract PDF content using Adobe PDF Services
async function extractPDFContent(retool_file) {
try {
// Get file data from Retool
const retoolFile = (await get_retool_file_content(retool_file.id)).data
console.log("FOUND FILE: ", retoolFile)
//const ret = await get_retool_file_content(fileId);
const file_name = retool_file.name;
const base64data = retoolFile.base64Data;
// Convert base64 to stream
const readStream = base64ToReadStream(base64data);
const credentials = new ServicePrincipalCredentials({
clientId: retoolContext.configVars.PDF_SERVICES_CLIENT_ID,
clientSecret: retoolContext.configVars.PDF_SERVICES_CLIENT_SECRET
});
// Creates a PDF Services instance
const pdfServices = new PDFServices({credentials});
const inputAsset = await pdfServices.upload({
readStream,
mimeType: 'application/pdf'
});
// Create parameters for the job
const params = new ExtractPDFParams({
elementsToExtract: [ExtractElementType.TEXT]
});
// Create and submit job
const job = new ExtractPDFJob({inputAsset, params});
const pollingURL = await pdfServices.submit({job});
const pdfServicesResponse = await pdfServices.getJobResult({
pollingURL,
resultType: ExtractPDFResult
});
// Get content from the resulting asset
const resultAsset = pdfServicesResponse.result.resource;
const streamAsset = await pdfServices.getContent({asset: resultAsset});
// Process the stream directly in memory
const chunks = [];
// Capture all the data chunks
streamAsset.readStream.on('data', (chunk) => {
chunks.push(chunk);
});
// Process the data once the stream ends
const documentContent = await new Promise((resolve, reject) => {
streamAsset.readStream.on('end', () => {
try {
// Combine all chunks into a single buffer
const buffer = Buffer.concat(chunks);
// Process the zip data directly from the buffer
const zip = new AdmZip(buffer);
const jsondata = zip.readAsText('structuredData.json');
const data = JSON.parse(jsondata);
// Create a structured representation of the document
const extractResult = {
filename: file_name,
elements: data.elements,
fullText: '',
sections: {}
};
// Process all text elements to extract the content
let currentHeading = 'main';
let currentSection = '';
data.elements.forEach(element => {
// Check if this is a heading element
if(element.Path && (element.Path.endsWith('/H1') || element.Path.endsWith('/H2') || element.Path.endsWith('/H3'))) {
// Save the previous section if it exists
if(currentSection.trim()) {
extractResult.sections[currentHeading] = currentSection.trim();
}
// Start a new section with this heading
currentHeading = element.Text.trim();
currentSection = '';
} else if(element.Text) {
// Add text to the current section
currentSection += element.Text + ' ';
// Also add to the full document text
extractResult.fullText += element.Text + ' ';
}
});
// Save the last section
if(currentSection.trim()) {
extractResult.sections[currentHeading] = currentSection.trim();
}
// Clean up the full text
extractResult.fullText = extractResult.fullText.trim();
console.log(`Extracted document: "${extractResult.filename}"`);
console.log(`Total text length: ${extractResult.fullText.length} characters`);
console.log(`Number of sections: ${Object.keys(extractResult.sections).length}`);
resolve(extractResult);
} catch (error) {
reject(error);
}
});
streamAsset.readStream.on('error', (error) => {
reject(error);
});
});
return documentContent;
} catch (error) {
console.log("Error extracting PDF content:", error);
throw error;
}
}
// Main function to process PDF and extract enhanced metadata
async function processPDFWithMetadata(retool_file) {
try {
const extractResult = await extractPDFContent(retool_file);
// Extract comprehensive metadata
const metadata = {
// Basic document information
title: extractResult.filename || "Unknown Title",
// Document metadata generation
documentType: detectDocumentType(extractResult),
pageCount: getPageCount(extractResult),
keywords: extractKeywords(extractResult),
entities: extractEntities(extractResult),
documentInfo: extractDocumentInfo(extractResult),
contentStats: analyzeContentStatistics(extractResult),
sections: identifyDocumentSections(extractResult),
sentiment: analyzeSentiment(extractResult),
classification: classifyDocumentCategory(extractResult),
topics: extractTopics(extractResult),
summary: generateSummary(extractResult),
relatedConcepts: extractRelatedConcepts(extractResult),
relevance: calculateRelevanceScore(extractResult),
targetAudience: identifyTargetAudience(extractResult)
};
// add filterLabels
metadata.filterLabels = generateFilterLabels(metadata);
// Combine extracted text with metadata
return {
text: extractResult.elements.map(el => el.Text).join(' '),
metadata: metadata
};
} catch (error) {
console.log("Error processing PDF with metadata:", error);
throw error;
}
}
const pdf_obj = await processPDFWithMetadata(params.retool_file);
return pdf_obj;
}
}