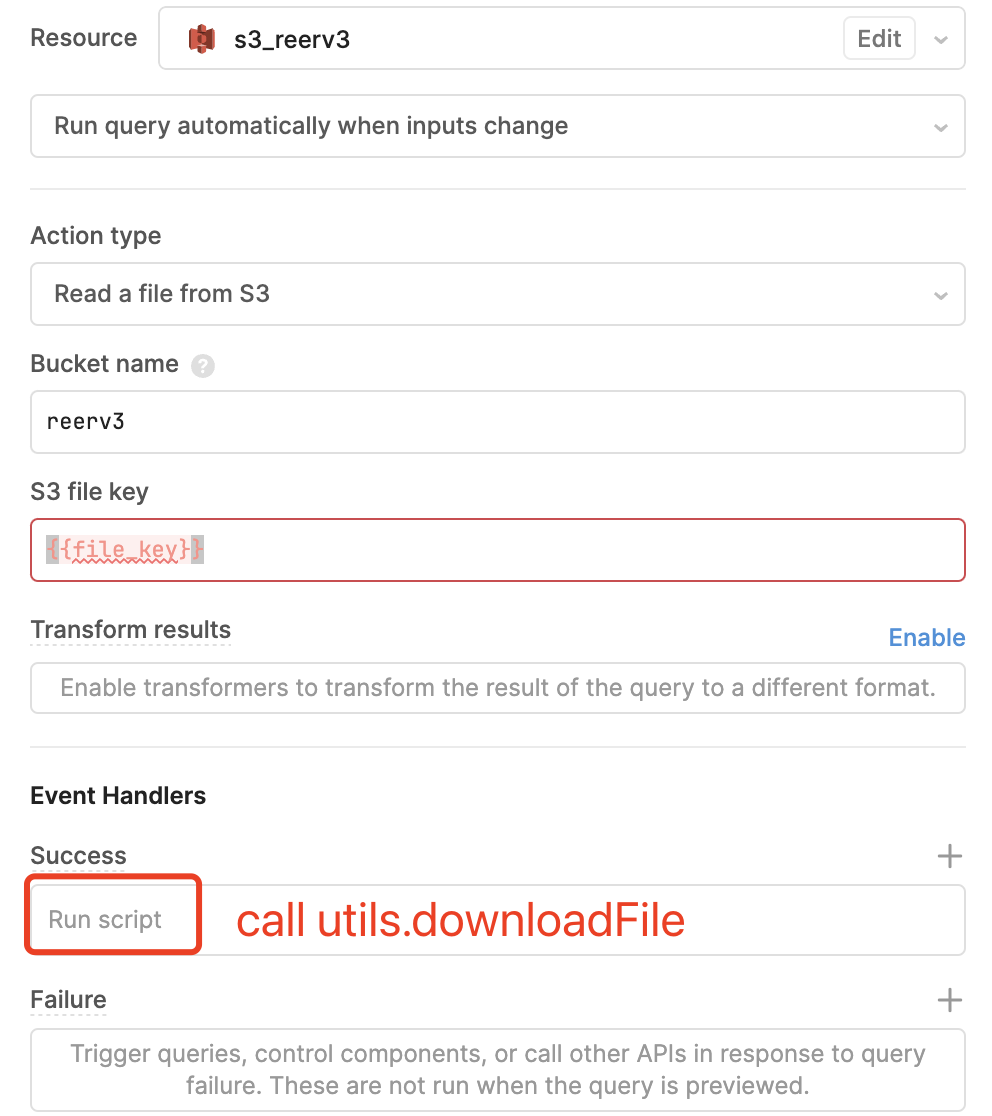
The reason of using combination of S3 readFile and utils.downloadFile is that we can change the download filename to whatever we want.
Instead, by means of S3 download file, the filename will be the S3 Key which is long and possibly leaks some directory information and also less comforting.
I switched to S3 download file for now until better solutions come out.
As potential solutions, one might be enhancing the file processing for these specific file types by wrapping the API query in a plain JS query. A more efficient workaround might be to obtain the URL of the file from S3, rather than directly downloading it:
Use readFile.data.Location rather than readFile.data.Body to fetch the URL of the stored file in S3.
Download the file using the obtained URL.
Ensure your S3 bucket policies permit public read access for the file if you're attempting to access it through a URL. If you still encounter issues, it would be useful to review how your Excel files are being saved to S3, specifically checking on the encoding or content-type setting.
Please provide more details about the error message encountered during the Excel files download if the issue persists.