there's a few things to keep in mind when choosing what solution to pick:
- fundamentally, they're going to give the same results.
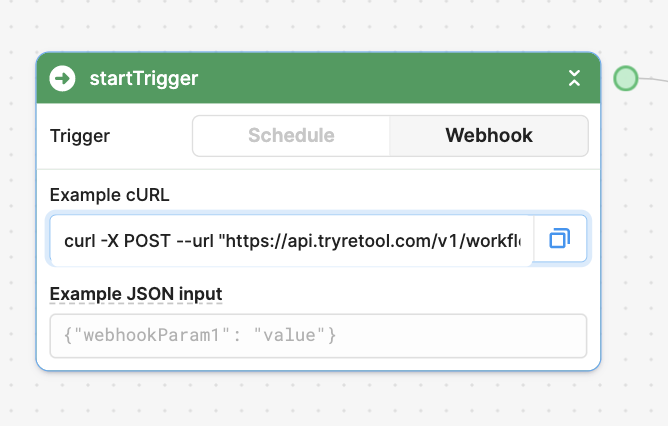
- in practice however calling the webhook with:
await fetch('http://api.retool.com/v1/workflows/<workflow_id>/startTrigger?workflowApiKey=<api_key>', { 'method': 'POST', 'body': JSON.stringify({workflowParam1: 'test'}), 'Content-Type': 'application/json'});
vs using the workflow resource type in a query can be more efficient depending on versions of libs, node and whatnot
it can be slightly more efficient to use fetch, this will mostly depend on how the retool framework generates code (in general these tend to be tier generators, but retool makes use of js and python so its probly some nifty mixed solution of an inline expander and mixed code/partial class generator), but using the workflow resource type in a query is going to incur overhead cost in the processing time spent by retools generated code in validating the url, parameters and again in validating the response and in processing the success/failure of the request which they may need to do to make the process and its data as secure as they can. auto generated headers and possibly their evaluated values can also add overhead time when unneeded extra headers are used especially when they cause certain delays sending the request either on the browser or server side with things like caching results, resending on slow route times before confirming packet loss, or setting restrictions w iframes and cors (basically any header whos value requires the processing of request/response data can add overhead... it's not guaranteed as things like short-circuiting can makeup for things in certain situations.
this is also going to be the easiest and the more secure way by default as retool handles the connection(if needed, worst case scenario its a long handshake process to confirm what was sent is the same as what was received), encryption/decryption, sending of data, the response as well as the conversion of the request body and opening a stream to read the response.
so why use fetch from code and complicate everybody's life? for specicially private webhook endpoints, the object structure for the data being sent and received on both sides (JSON on both sides with known parameters and value types for the server and frontend) is known by you. retools amazing framework has to be designed in a 'great-at-everything master of none' or templatized manor so it can handle the processing of different data types. since you know the data types and their structure you can code the validation, REST request sending and response processing for your specific use case you can write specialized code for speed and efficiency as well as leverage newer versions of pre-loaded libraries and libs previously unreleased using new algos or processes (like if retool used axios but we decided to use fetch since its built-in and customizable usually making it more effecient or maybe you need to support old browsers so you use XMLHttpRequest instead)
EDIT:
just noticed in the docs it says
Workflows can read data from a webhook event's JSON payload (e.g., error message or confirmation number) and make it available to your workflow. The following example of a Stripe event that occurs when a Setup Intent is created. This event payload includes details about the event, including the Setup Intent's properties.
...
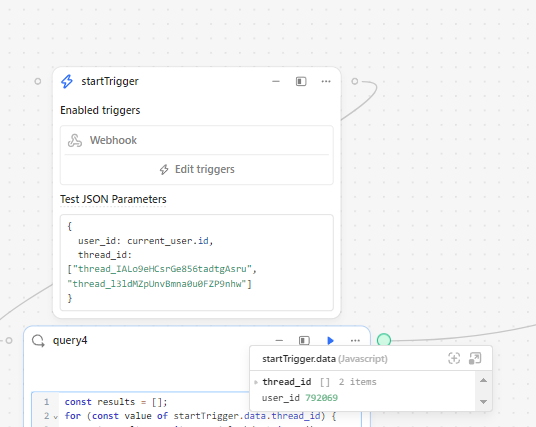
You can then reference event properties anywhere in your workflows with the startTrigger.data object. For the example above, you can reference the Setup Intent ID within the payload using {{ startTrigger.data.data.object.id }}, which is seti_1NG8Du2eZvKYlo2C9XMqbR0x.
You can optionally provide example JSON values, such as an existing payload, to build and test your workflow in the Workflow IDE.
the wording is a bit tricky to me and until I took a min to think about it there is 1 HUGE difference I missed:
if you do not use the Example JSON Values in the startTrigger block you are able to access event data from anywhere in the workflow. so if you use a service where you set the webhook for the service to automatically send data to when certain events occur... tldr; no test data in the startTrigger means the workflows webhook can be sent differnt data and structures depending on the event that happens (so if a user triggers a 'logout' event somewhere that sends your workflow
{
event: 'logout',
data: {
user_id: 0,
timestamp: 12346
}
}
later on it can send the same workflow the following object:
{
event: 'login',
metadata: {
status: 'completed'
parent_id: 12
},
data: {
statistics: [1, 2, 4, 8, 16]
}
}
and the workflow won't error out (or do weird things). when you do provide the test data and something tries to send the workflow 2 data structures like above that are not the same structure as what is defined in the test data the workflow seems to default to using this test data as the parameter values overwriting what was sent in the body (it can make logs look like CURL or Postman sent the 'correct' data in the REST request body, but the input and/or prepared sql statements for all preceding blocks read different values than what was sent)