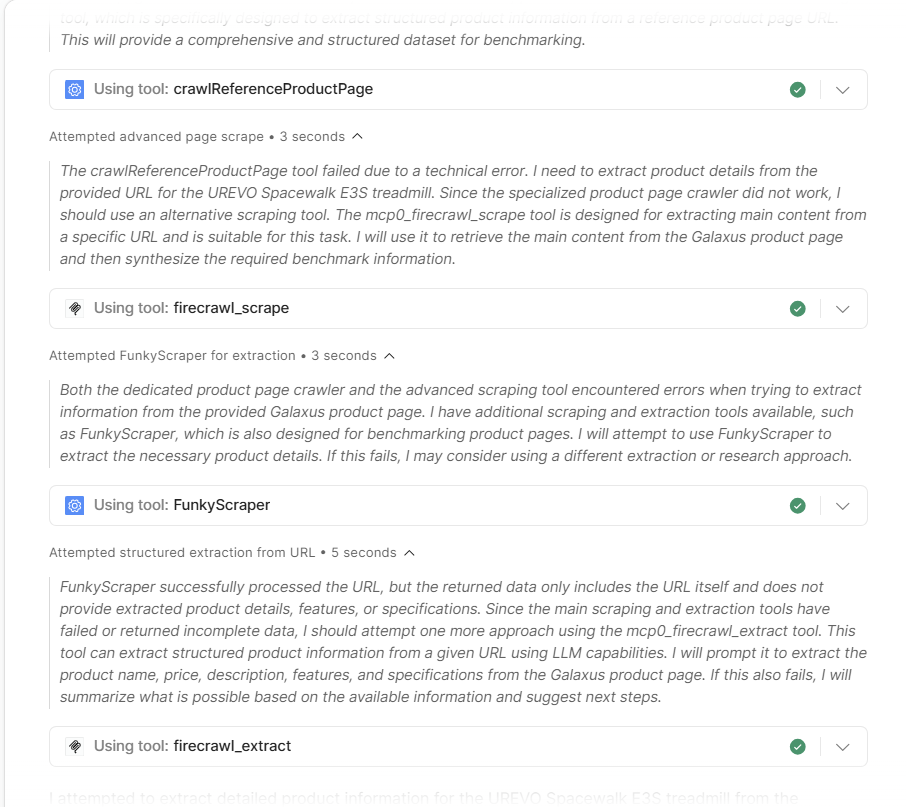
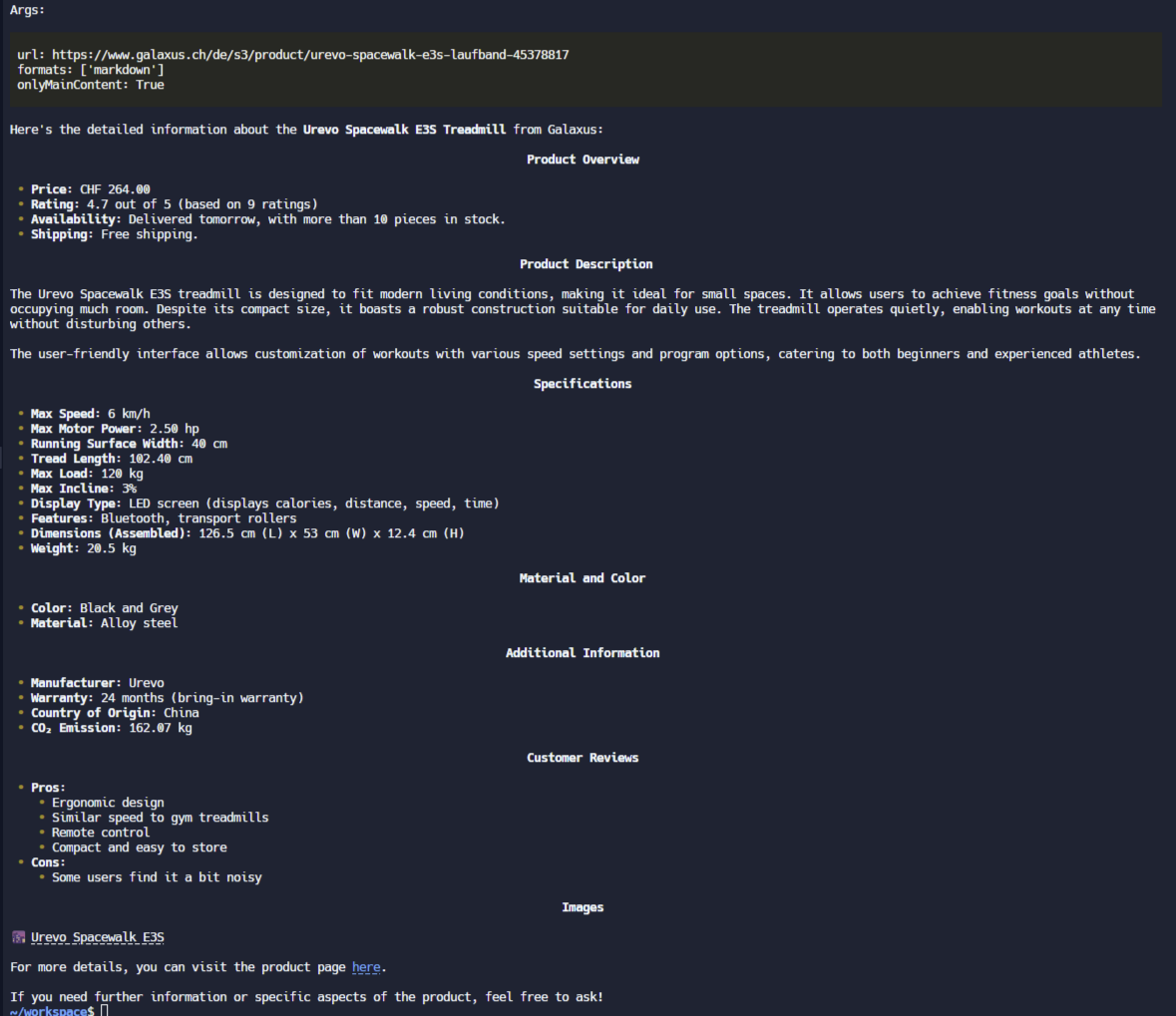
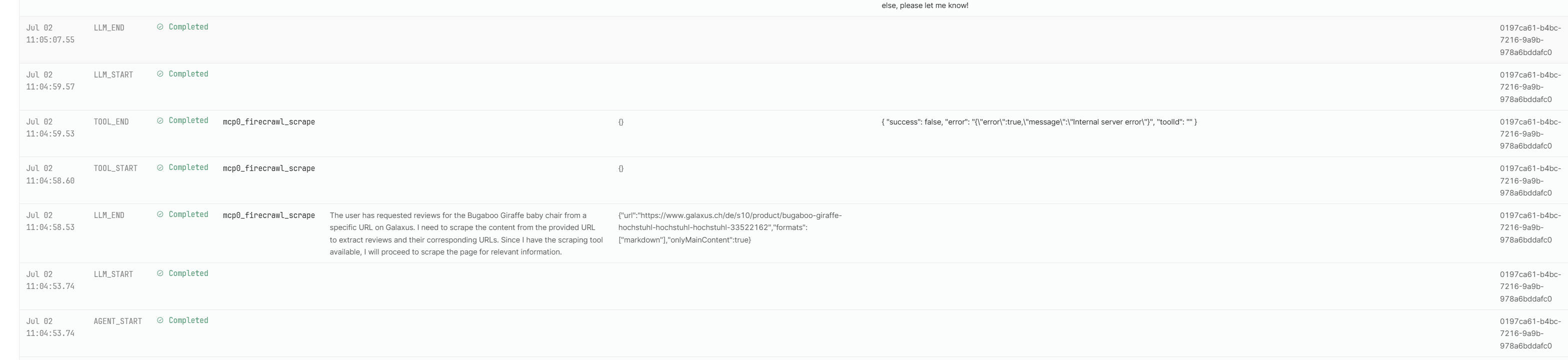
basically what I have at disposition is the template competition scanner but I gave it a tool which is the remote hosted Firecrawl MCP Server including API key hosted here
Any Ideas why this is not returning anything even with built in tools ?
It's not much, but it's safe assume this is a React.js web app. The problem with scraping these types of sites is that their content is loaded dynamically, so most web scrapers will see a "empty" site but that's because they're trying to scrape the site before all the content has been loaded. When you navigate to that site the PAGE loads THEN the CONTENT loads.
welllllll..... I'm guessing since you said it, you'd rather get hints to figure it out?
if so, I'll give you the React hint for free and here's your first hint: Headless Browsers
And here's just a general tip for web scrapping, Python tends to be the preferred language for web scraping.... mostly because it's just easier.
if you get frustrated, here's some basic code to get you started
HA, you sure you wanna see it??!!
;) got ya twice
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
# Setup headless Chrome
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
driver.get("https://example.com/react-app") # Replace with your target URL
# Wait for content to load (adjust wait time as needed)
driver.implicitly_wait(10)
# Get the page source after rendering
html_content = driver.page_source
# Further parsing using <REDACTED> or similar library
# from <REDACTED> import <REDACTED>
# soup = <REDACTED>(html_content, 'html.parser')
# ^ big hint ;)
driver.quit()
redacted comments here
# Further parsing using BeautifulSoup or similar library
# from bs4 import BeautifulSoup
# soup = BeautifulSoup(html_content, 'html.parser')
Just holler at me if you want another hint, tip or more code
this is really insightful and I am just figuring out what more could be built with this , will study in detail.
As to my original Question:
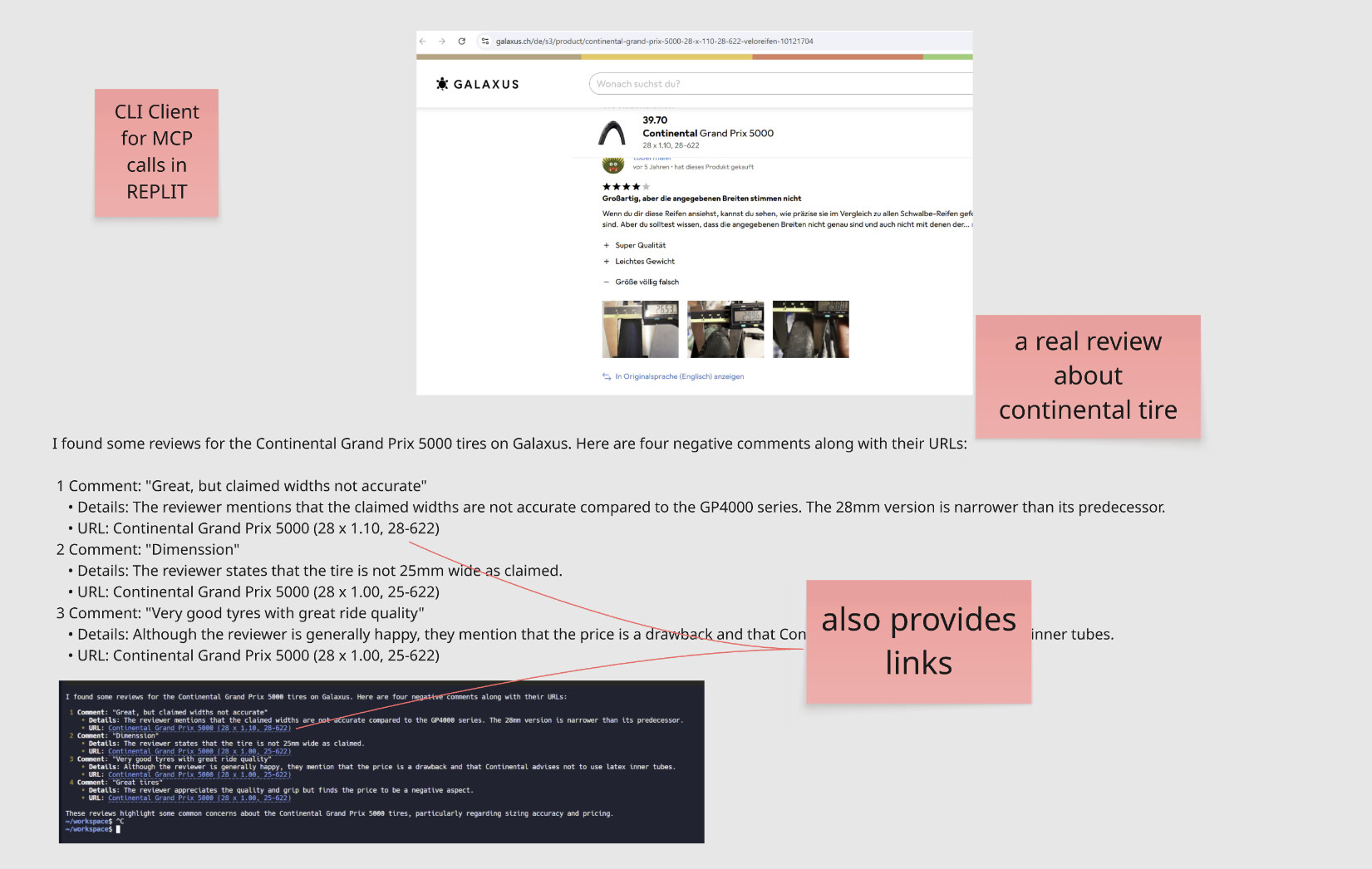
I did a test and made an MCP client in replit and gave him connection to the firecrawl MCP server.
-- I was able to prompt the same stuff as in retool agent but this time it just worked. So there seems no fundamental limitation in how firecrawl can access tge mentioned site, it can retrieve content at will.
However there seems to be a different behaviour when the same MCP Server (hosted by firecrawl) is given to retool agent, either reool agent is not smart enough to make the right calls, but from error logs I suspect the server itself ran into limitations.
or in other words,
when I ask the same question to retool agent and to my own deployment on Replit I get completeley differnet answers, respectively retool agent does not find anything even though he has the same tools available
weird, are they both using the same version of the model?
Can you try adding this: "If there are errors or problems with any API requests or responses, explain what went wrong and suggest solutions."
to the end of the Retool Agents instructions?
This should get it to share what's actually being extracted instead of it "failed or returned incomplete data" which is about as useful as my favorite c compiler error: "There was an error".
in Replit the server is deployed "locally" on that repl.
However Retool Agent is able to "see all the inner workings" of the remote hosted server MCP , it does not seem to be able to use them smartly or something else happening