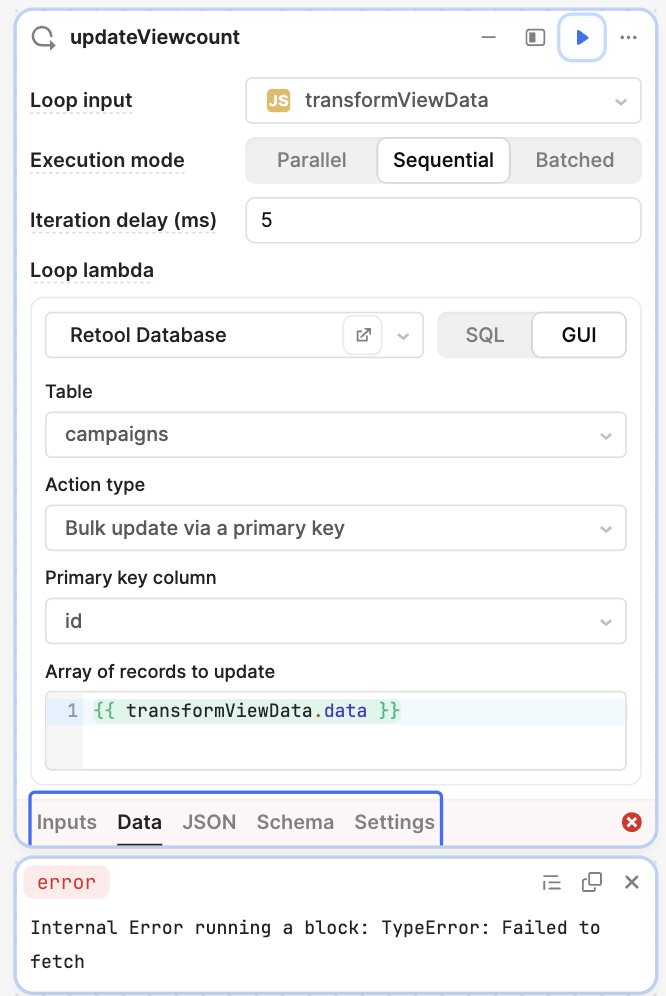
I've been starting to get timeouts on a workflow for some reason and need help troubleshooting the issue.
The workflow is set up to:
(1) select a number of rows from a Retool-hosted database,
(2) use an ID from those rows to query an API and retrieve data, then
(3) update those same rows from (1) with the API data using a "Bulk update via a primary key" database query.
Everything has been running smoothly until last week, when the workflow started timing out on the (3) step. I've been getting vague "timeout" errors, like this one:
{"data":null,"metadata":{},"error":"Internal Error running a block: TypeError: Failed to fetch"}
After playing around with different (3) queries, I finally got something more detailed with a batched Loop block, which is giving me the following error:
Error evaluating updateViewcount (iteration 16): Knex: Timeout acquiring a connection. The pool is probably full. Are you missing a .transacting(trx) call?
Based on other research I was doing to try to fix the issue (this and this), the error seems to suggest that the size of the update is the issue, but I'm unsure how to proceed from here if the Loop block isn't chunking the update properly.
I haven't been able to find any other information about the Knex error as it pertains to Retool. It seems like a general node.js issue that's documented elsewhere (here, for example), but I'm unsure how to apply this to Retool.
See below for my Loop settings:
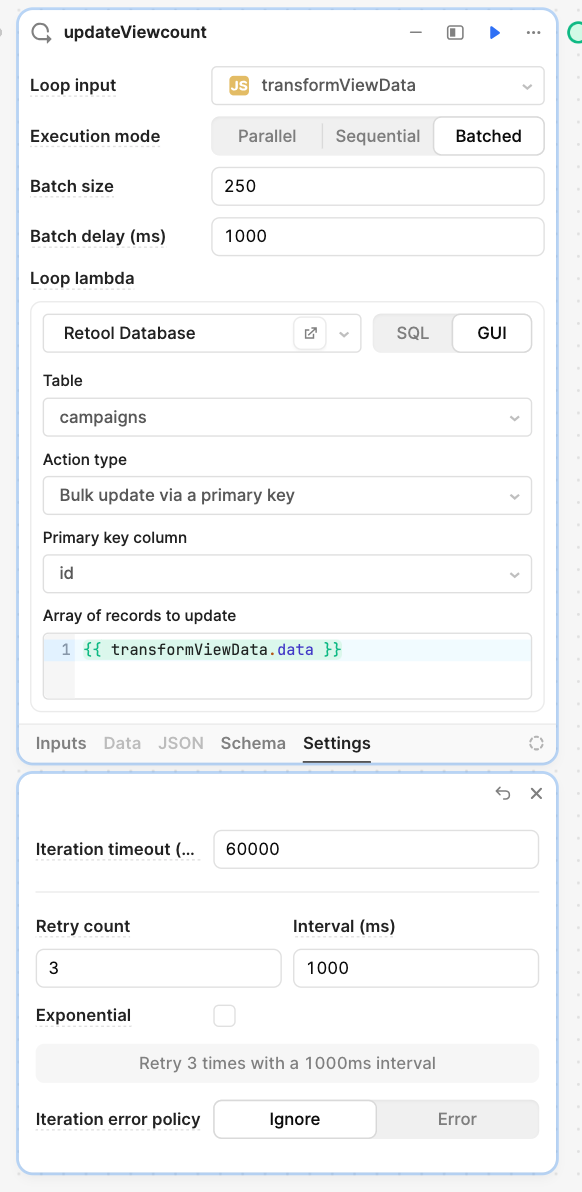
Some other context that might be relevant: the amount of rows did not change from the day the workflow was working to the next day when it didn't, so I initially ruled out the issue as "too many rows being updated." I was able to align the timing to when I logged into my Retool instance on a slower computer than usual, so I thought maybe that was causing the timeout issue somehow.
That seemed far-fetched, although when I check the rows in the database, the data is being updated despite the workflow saying it failed, so I'm not sure what to make of that.
I haven't been able to log into a faster machine yet to test this theory definitively. It seems strange that a backend workflow would fail because of a slower local machine that is logged into the Retool instance... right?
Appreciate the help!