Hi all,
Desired outcome
Write all API results to PostGreSQL DB - result set will be ~5-600, more than retool table of 100
Currently working
- Get Tempo (Jira) timelogs for a given timespan (e.g. 1-May-2023 to 31-May-2023) via API using pagination and offset
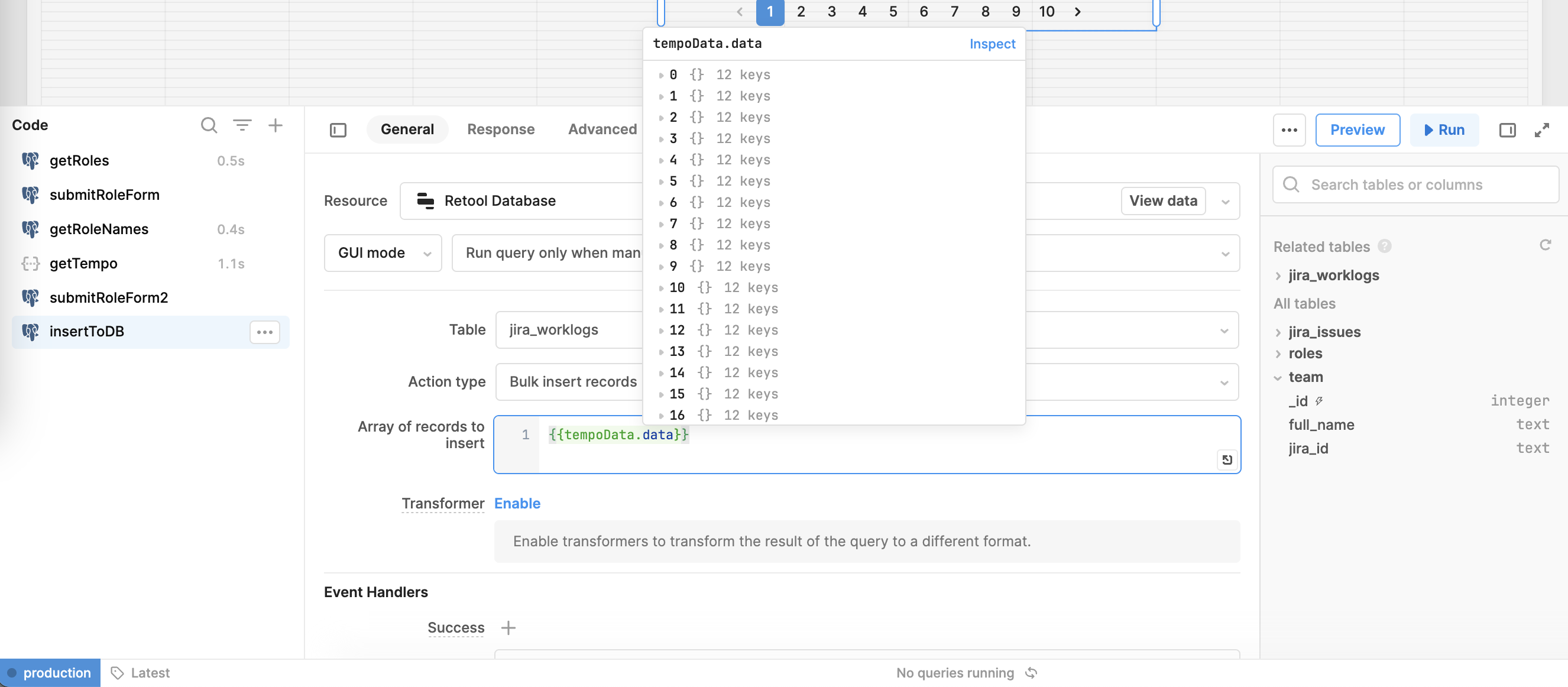
- Results are ~600, so I am using limit=100 and offset pagination to populate a retool table
- Save to DB using a simple Bulk insert records with array to insert = {{tempoData.data}}
(This inserts the 'current' set of 100 results)
Question
What is the correct approach to loop through all pages of results and run the bulk insert for each set?
The data does not necessarily need to be in the table as downstream it will be aggregated (i.e. gathering total hours by Jira issue ID / User ID)
Screenshots show the two main working components - the API query and DB insert
that's quite a beast you're taking on there, duplicating Jira locally!
First off I'd invest some time in looking at Retool Workflows and not using an App to run this
Second I'd consider what would happen if any one of the API calls or Inserts fails for any reason
Third I'd look if there's a way to get an export out of the target system, maybe a CSV dump etc
You may also want to think about doing this incrementally, a daily job that just takes deltas and not the entire month of data each time. Not sure if that's possible though, if older records are edited and you're not able to identify that from the API etc.
HI @dcartlidge
Thanks for your reply. I'll do some research into Workflows - I'm at the POC stage here.
I can certainly get a CSV for upload instead of using Tempo's API - this is roughly what we're doing currently in Sheets. Ideally Tempo would have a summary endpoint for a given period, but from my reading of the docs they do not.
Incrementally is an option, although the timesheets are only 'locked' a day or two after a given week, so the results could likely be >100 anyway.
Editing via the UI would be by exception if hours needed to be adjusted or moved from one Jira ticket to another after the end of a month.
Regarding failures, my approach would be to log to a 'Log' table or similar. I'm currently doing something very similar in Sheets (via Apps Script) for another SaaS system we use and manage in approximately the same way: - recursively call an API endpoint by day, write time logs to a Sheet, and logging any exceptions in a separate sheet.
So my question is a general one, as for this report/process there are multiple data sources, which
I would query via API call and ultimately want to insert results to a database. Most would return a large number of results (>1000) relevant to a given month.
So, is the correct approach to:
- Call the API with pagination and set results to a retool table
- Use bulk insert to DB
- Move to the next 'page' and recurse through pages until complete
If so, do I need to create a JS process to manage the calls/bulk inserts? That is the part I'm not too clear on
thanks!
I still wouldn't do the multiple API calls in your app, there could be timeout issues and the general UX wouldn't be great.
Personally, I'd have all of the data ingestion happen in the background/overnight as part of a Retool Workflow and use that data source for the app if you needed to manually adjust or approve row data to be bulk inserted somewhere else.
So, just based on what you've said, my preferred option would be:
- ingest locked records on a daily basis using a retool workflow (so no UX lockups or timeouts)
- put ingested data into a temp table in retool DB (so no issues with partial data)
- have an app that looks at this retool DB and allow manual adjustment (if needed)
- have a button in the app that loads this data into your main DB and clear down retool DB (but what happens if someone doesn't press the button?)
If the approval part isn't necessary I'd just skip step 3 and do step 4 when all records have been successfully loaded
When I was mentioning the failures what I was referring to is less about the logging but what do you do about it - ie if you ask for this months data and you get all of it back apart from 1 day then that data set is effectively useless and the entire "transaction" needs to be rerun. If you've bulk inserted some of them and not others them it can get messy to unpick.
There's probably a dozen other ways to solve this one but what you describe sounds like one of the main use cases that Retool Workflows are there to help with.
Hi @dcartlidge
Thanks again for your guidance. I spent some time looking at Workflows and it's definitely what I need - thanks for the tip!
What I'm doing now is pulling the month's data (400 ish records) and inserting to a temp table. As a separate step I'll query that data and aggregate at the User and Issue level and store that data in a table (cross checking with Jira tempo report).
Definitely very helpful to be able to pull all records for a month without needing to paginate in the App.
Thanks again
Nick
1 Like