Is it possible, in a transformer, to trigger a query and pass variables into the query?
My end goal is to use the transformer or query to trigger the Jira query and pass variables because I don't see a built in way to take into account pagination for the Jira queries. I then want to store this information in a chart.
Something like-
let return_data = [];
let totalPages = 10;
let resultsPerPage = 100;
Thanks. Looks like that helped quite a bit! Now I just need to figure out how to store the data in a temporary variable or list and then return that.
Appreciate the help!!!
Awesome that helps alot. Not sure I'm doing this the correct way, but here's my code below. The only issue I'm running into now is displaying all of it in the table. Any thoughts? I appreciate the help on this!!
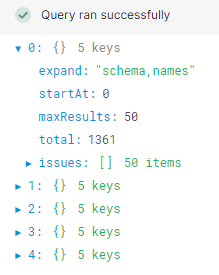
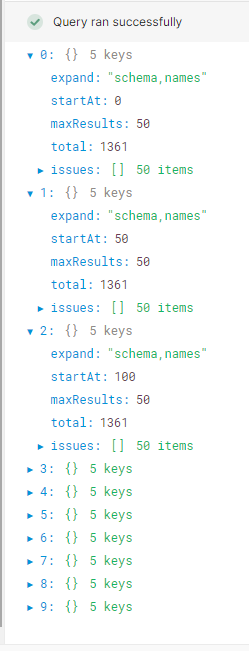
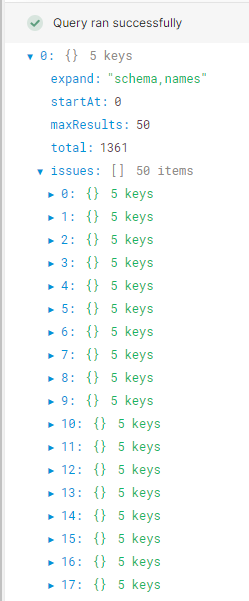
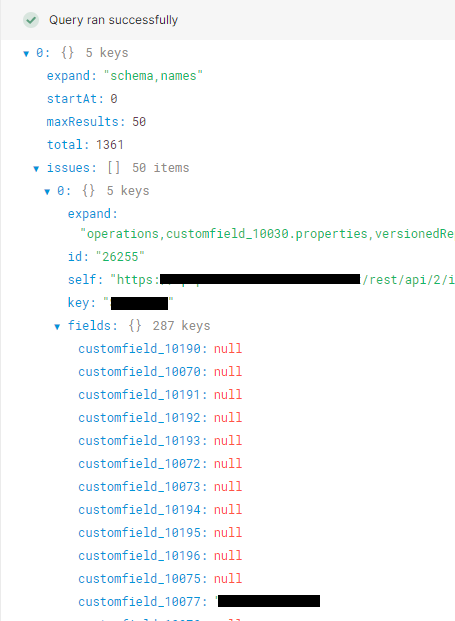
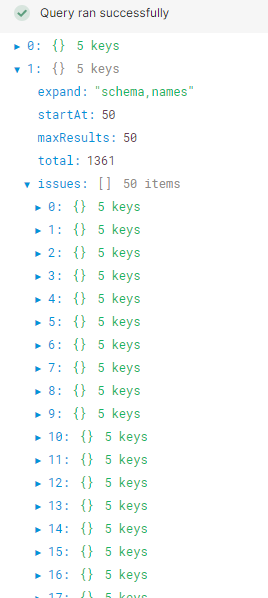
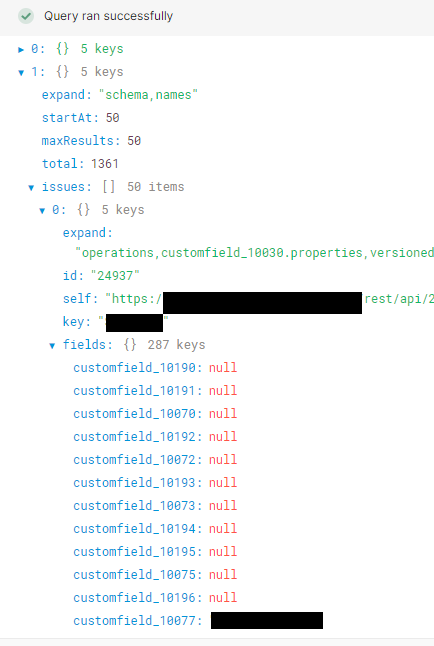
EDIT:Adding a pic of what it's returning. I want to pull the issues out of each of the objects(?).
let start_at=[0,50,100,150,200,250,300,350,400,450]
let maxresultsPerPage=50
const arr = start_at
console.log(arr.value)
const query = SPMAll_Pagination // your query to trigger for each
I appreciate the help. I actually just ended up setting up server side pagination. The initial hope was to pull all data and then use it in the charts and the tables.
Hi @victoria, I'm looking at the same issues currently and have followed this thread.
the code you've provided flattens the result in the query side to one level which is already awesome.
could you advise to the earlier request as to how you would flatten recursively
I use the select query
select id
, key
, fields
from {{_.flatten(jsAllProjects2.data.map(obj=> obj.issues))}} as i
which works great, however ideally i would be able to just pull out fields.summary ...ect as i do in postgresql
If it's of any help, I actually ended up stumbling into the solution I was hoping for with the following code. It will go through each "page" of Jira results, iterate over the results and put them into a list that contains all of the results of the request.
You can then reference the list in another JS query or transformer.
----transformer----
let total_results = {{Jira_Query.data.total}}
//Added 1 to ensure all pages are captured
let total_pages = (total_results / 50)+1
return total_pages
----JS Query----
//Get the total pages from the above transformer
let totalPages = jiratransformer.value;
let start_at = 0;
let max_results=50;
let page = 0;
let final_list=[];
//Start the main loop to go through each page of results
while (page <= totalPages){
const results = jira_query.trigger({ additionalScope:{start_at: `${totalPages}`, max_results:`${max_results}`}})
//Loop through all results in the current page
while (i <=49){
let jira_customfield= jira_query.data.issues[i]['fields']['customfield_']
let policy_status = jira_query.data.issues[i]['fields']['status']['name']
//push results to a list
final_list.push({custom_field: `${jira_customfield}`, policy_status: `${policy_status}`})
i=i+1
}
//increment
start_at=start_at + 50
page=page + 1
//reset the i variable for the next 50 results
i=0
}
//return data
return final_list
Oh thanks, I will look into this tomorrow. do you have any thoughts on the speed of this? I'm only looking at around 5k results but I would have guessed going key by key in JS would be slower than doing it in SQL at the end?
I've only been using this on a project that has about 1k tickets currently and it's ran just fine. With that said, I do have a few more projects that I'll be using this on, one with 2k results and the other with about 5k, but it won't be for a little bit so I would definitely say it's worth testing and comparing on your end. When I do test it, I can let you know if it's slower and by how much, but I would agree that performing a SQL query potentially could be faster depending on environmental variables.
Hello everybody.
This is an old thread, however, I'm trying to consume all jira cloud issues mapping the columns, but I came across "null" in the assignee.displayName field.
Can you help how can I get around the nulls?
//Get the total pages from the above transformer
let totalPages = jiratransformer.value;
let start_at = 0;
let max_results=50;
let page = 0;
let final_list=[];
//Start the main loop to go through each page of results
while (page <= totalPages){
const results = jira_query.trigger({ additionalScope:{start_at: `${totalPages}`, max_results:`${max_results}`}})
while (i <=49){
let assignee= jira_query.data.issues[i]['fields']['assignee']['displayName']
let jira_customfield= jira_query.data.issues[i]['fields']['customfield_']
let policy_status = jira_query.data.issues[i]['fields']['status']['name']
//push results to a list
final_list.push({
custom_field: `${jira_customfield}`
, policy_status: `${policy_status}`
,assignee: `${assignee}`
})
i=i+1
}
//increment
start_at=start_at + 50
page=page + 1
//reset the i variable for the next 50 results
i=0
}
//return data
return final_list
message:"Cannot read properties of null (reading 'displayName')"
You can try using optional chaining here to avoid attempting to access the property of a nullish value. However, it looks like you may also need to wait for your Jira query to finish running before accessing its data.
Can you try using const results = await jira_query.trigger(/* config options */) and then, later in your script, reference results instead of jira_query.data? e.g. let assignee = results.issues[i]?.['fields']?.['assignee']?.['displayName']