- Goal: I built an app to track all of my job applications. I created a workflow to do the following:
1.Call a SQL query to list all the data I need to do a supervised regression analysis with python
- Use a python code block to do the analysis showing the probability of each application to turn into an offer
- Insert the output of the python code into the retool database
- Use that data to rate each application's probability of success in a retool table
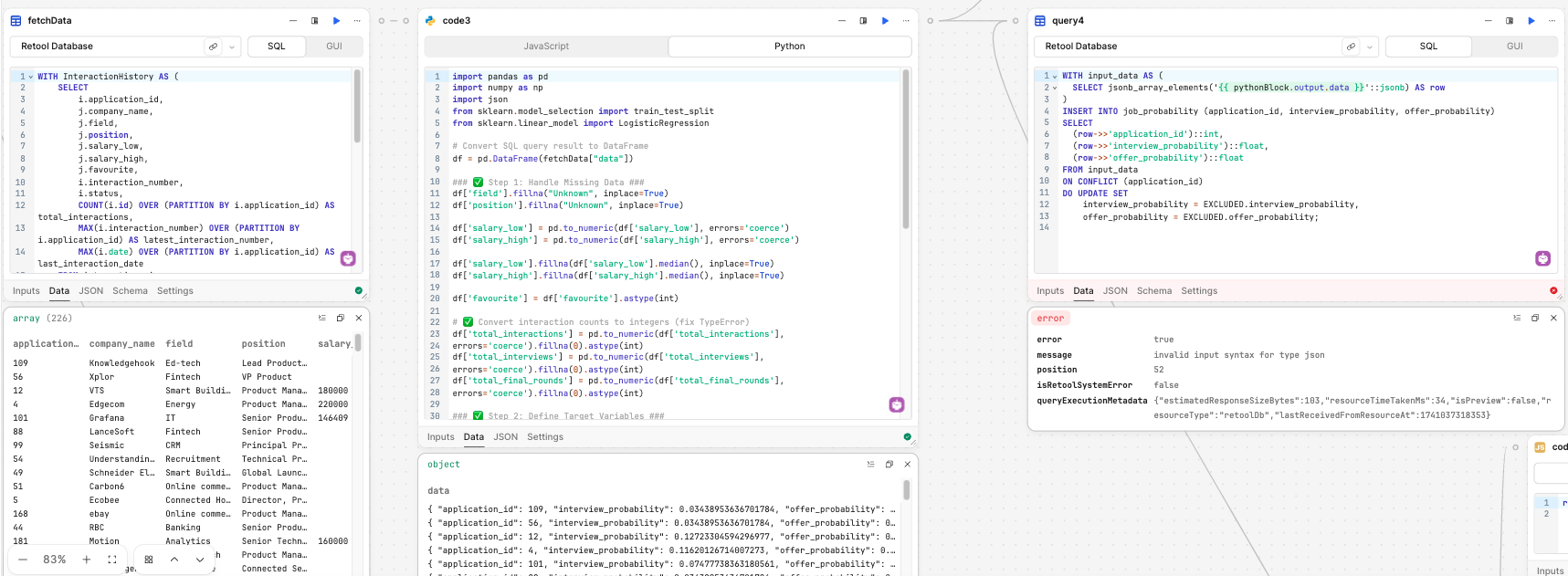
Here is the SQL query that pulls the data I need:
WITH InteractionHistory AS (
SELECT
i.application_id,
j.company_name,
j.field,
j.position,
j.salary_low,
j.salary_high,
j.favourite,
i.interaction_number,
i.status,
COUNT(i.id) OVER (PARTITION BY i.application_id) AS total_interactions,
MAX(i.interaction_number) OVER (PARTITION BY i.application_id) AS latest_interaction_number,
MAX(i.date) OVER (PARTITION BY i.application_id) AS last_interaction_date
FROM interactions i
JOIN job_search_02 j ON i.application_id = j.id
)
SELECT
application_id,
company_name,
field,
position,
salary_low,
salary_high,
favourite,
total_interactions,
latest_interaction_number,
last_interaction_date,
-- Count how many times an application moved past "Applied"
COUNT(CASE WHEN status IN ('Moving to the next step', 'Waiting for an update') THEN 1 END) AS total_interviews,
-- Count how many times an application reached final stages but didn't get an offer
COUNT(CASE WHEN status = 'No offer' THEN 1 END) AS total_final_rounds,
-- Track rejections (may help in ML analysis)
COUNT(CASE WHEN status = 'Rejected' THEN 1 END) AS total_rejections
FROM InteractionHistory
GROUP BY application_id, company_name, field, position, salary_low, salary_high, favourite, total_interactions, latest_interaction_number, last_interaction_date;
Here is the sample output:
{"data":[{"application_id":109,"company_name":"Knowledgehook","field":"Ed-tech","position":"Lead Product Manager, Educators","salary_low":null,"salary_high":null,"favourite":false,"total_interactions":"2","latest_interaction_number":1,"last_interaction_date":"2025-01-31","total_interviews":"0","total_final_rounds":"0","total_rejections":"0"},{"application_id":56,"company_name":"Xplor","field":"Fintech","position":"VP Product","salary_low":null,"salary_high":null,"favourite":false,"total_interactions":"2","latest_interaction_number":1,"last_interaction_date":"2024-12-02","total_interviews":"0","total_final_rounds":"0","total_rejections":"1"},
this is the python code block that does the analysis:
import pandas as pd
import numpy as np
import json
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# Convert SQL query result to DataFrame
df = pd.DataFrame(fetchData["data"])
### ✅ Step 1: Handle Missing Data ###
df['field'].fillna("Unknown", inplace=True)
df['position'].fillna("Unknown", inplace=True)
df['salary_low'] = pd.to_numeric(df['salary_low'], errors='coerce')
df['salary_high'] = pd.to_numeric(df['salary_high'], errors='coerce')
df['salary_low'].fillna(df['salary_low'].median(), inplace=True)
df['salary_high'].fillna(df['salary_high'].median(), inplace=True)
df['favourite'] = df['favourite'].astype(int)
# ✅ Convert interaction counts to integers (fix TypeError)
df['total_interactions'] = pd.to_numeric(df['total_interactions'], errors='coerce').fillna(0).astype(int)
df['total_interviews'] = pd.to_numeric(df['total_interviews'], errors='coerce').fillna(0).astype(int)
df['total_final_rounds'] = pd.to_numeric(df['total_final_rounds'], errors='coerce').fillna(0).astype(int)
### ✅ Step 2: Define Target Variables ###
df['interview_likelihood'] = (df['total_interviews'] > 0).astype(int) # Likelihood of getting an interview
df['offer_likelihood'] = (df['total_final_rounds'] > 0).astype(int) # Likelihood of getting an offer
### ✅ Step 3: Convert Categorical Fields ###
df = pd.get_dummies(df, columns=['company_name', 'field', 'position'], drop_first=True)
### ✅ Step 4: Define Features ###
X = df[['latest_interaction_number', 'salary_low', 'salary_high', 'favourite', 'total_interactions', 'total_interviews', 'total_final_rounds']]
### ✅ Step 5: Train Separate Models for Each Prediction ###
# Train Interview Prediction Model
X_train, X_test, y_train, y_test = train_test_split(X, df['interview_likelihood'], test_size=0.2, random_state=42)
interview_model = LogisticRegression()
interview_model.fit(X_train, y_train)
df['interview_probability'] = interview_model.predict_proba(X)[:, 1]
# Train Offer Prediction Model
X_train, X_test, y_train, y_test = train_test_split(X, df['offer_likelihood'], test_size=0.2, random_state=42)
offer_model = LogisticRegression()
offer_model.fit(X_train, y_train)
df['offer_probability'] = offer_model.predict_proba(X)[:, 1]
### ✅ Step 6: Return Proper JSON Object ###
output_json = df[['application_id', 'interview_probability', 'offer_probability']].to_dict(orient="records")
# 🔥 FIX: Explicitly return a JSON object, NOT a string
return {"data": output_json}
here is the sample output:
{"data":{"data":[{"application_id":109,"interview_probability":0.03438953636701784,"offer_probability":0.01923380571479206},{"application_id":56,"interview_probability":0.03438953636701784,"offer_probability":0.01923380571479206},{"application_id":12,"interview_probability":0.12723304594296977,"offer_probability":0.0521071338641757},
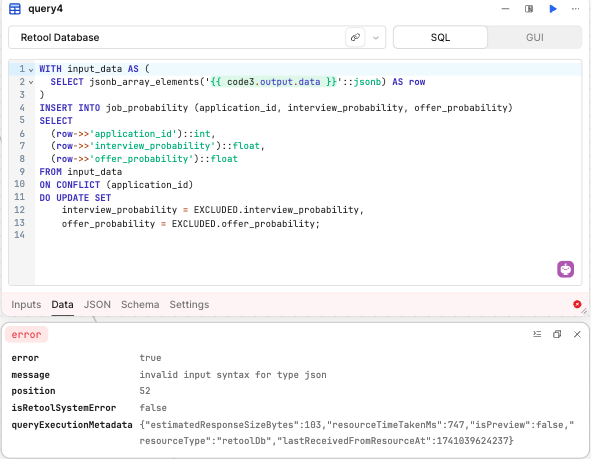
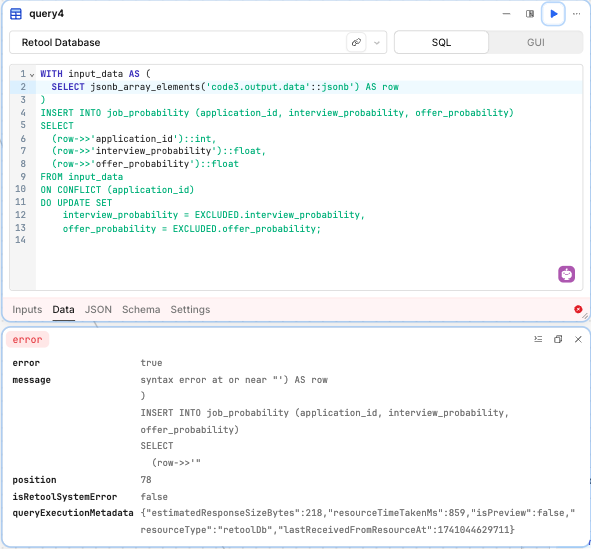
Here is my SQL query to insert the output into the retool DB but it doesn't work.
WITH input_data AS (
SELECT jsonb_array_elements('{{ pythonBlock.output.data }}'::jsonb) AS row
)
INSERT INTO job_probability (application_id, interview_probability, offer_probability)
SELECT
(row->>'application_id')::int,
(row->>'interview_probability')::float,
(row->>'offer_probability')::float
FROM input_data
ON CONFLICT (application_id)
DO UPDATE SET
interview_probability = EXCLUDED.interview_probability,
offer_probability = EXCLUDED.offer_probability;
What am I doing wrong? Can anyone guide me?