Hi,
We want to enable someone to enter a URL and then hit a button to have the file copied into our own S3 bucket. We already have a database full of such URLs that need migrated, as well as new adhoc URLs.
How should I go about that?
Hi,
We want to enable someone to enter a URL and then hit a button to have the file copied into our own S3 bucket. We already have a database full of such URLs that need migrated, as well as new adhoc URLs.
How should I go about that?
Hey @richard!
Happy to help here! Do these URLs directly return a file in a specific format? Would you mind sharing an example here?
Hi Chris,
The URLS just point to files sitting on a webserver. e.g.
www.somedomain.com/files/source.pdf
We want to be able to upload that source file into S3 and save the new URL into our database, via a retool command or process.
We'd also like to be able to arbitrarily enter URLs to files and click a button and have the file uploaded to S3 in a similar way.
Does this clarify?
Thanks
Hey @richard!
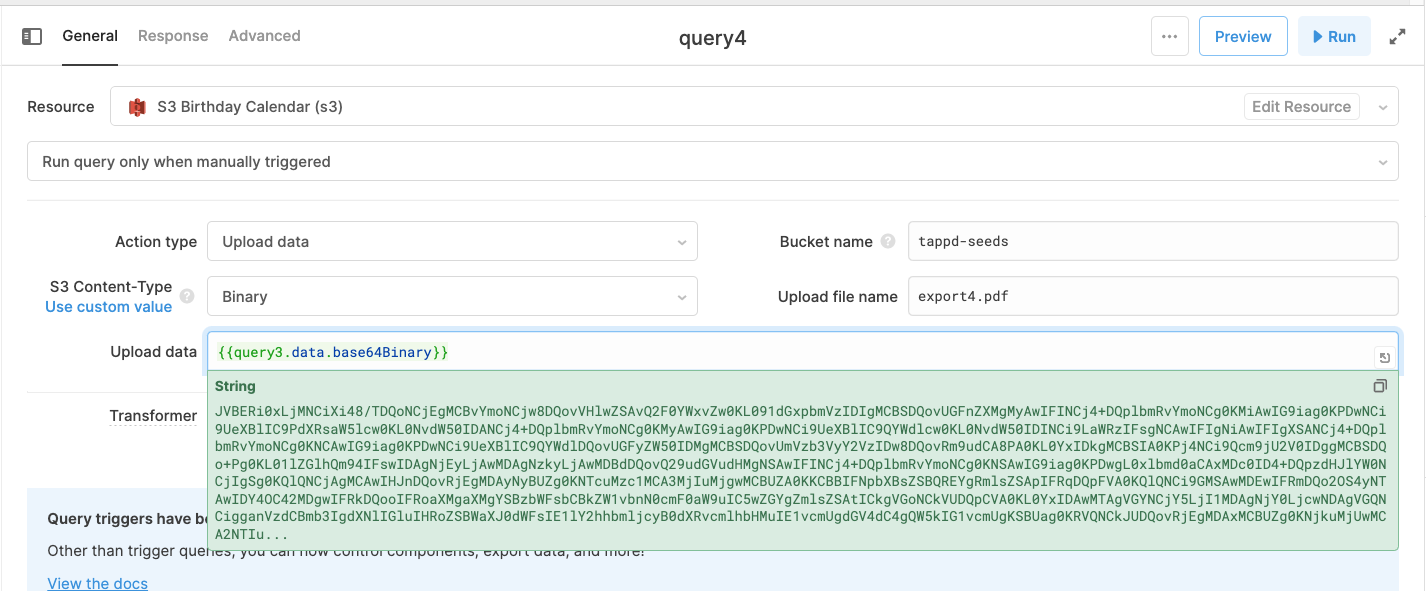
Sorry for the slow reply here. Are these files going to be consistently the same type (always a pdf)? If so, you could set up a GET query to the original URL, this should return a JSON object with 3 keys:
base64Binary, fileName, and fileType. From here, you can use this binary to pass to an upload query:
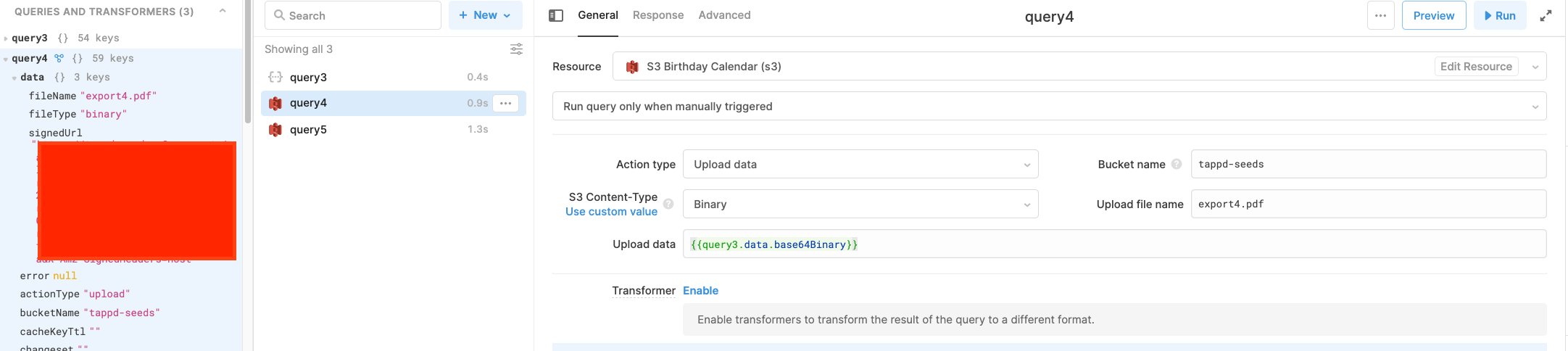
In this case, I'm passing the binary directly with the S3 Content-Type set to binary and the upload file name including the matching extension. Once this query is run, it should return a signed url that you can include in your url upload query
Do you think this could work for your use case here?\
\
Works perfect here. Both from url and plain base64Binary generated at pdfotter api, to direct upload S3.
As a straightforward solution, you can use Resilio Sync or Gs Richcopy 360 to copy directly to AWS S3, try the free version of both