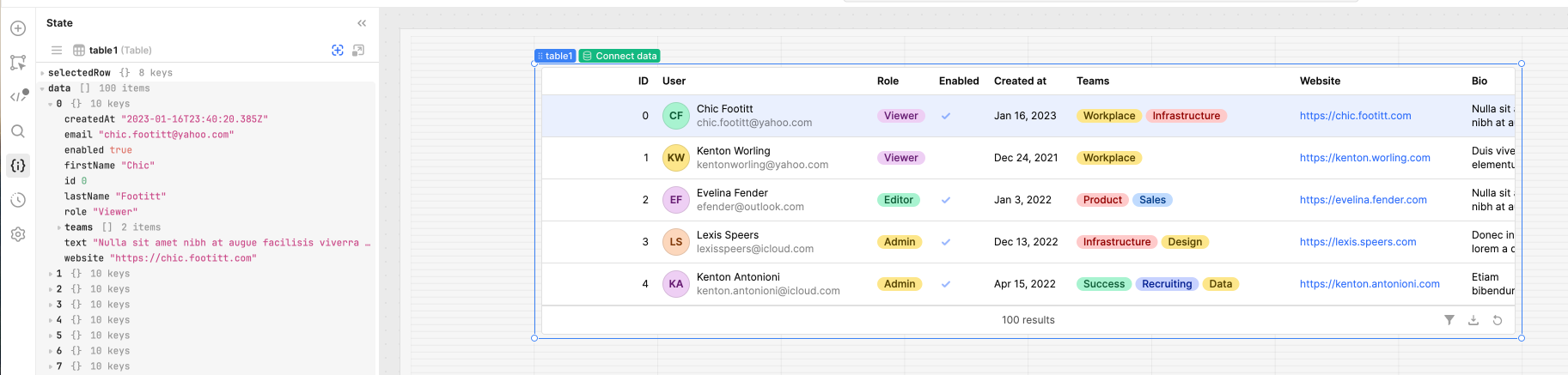
I think it should be possible to do such. Looking at your example (thank you for sharing that btw) are you looking to add a header row to be on the very top of all your existing data?
Would it be all the same value, such as the string "Required" like you have in your example? Or would it be dynamically set, such as to also include values such as "Not Required" as well?
If you are looking to add in a row like 2 in your image, we might be able create a "synthetic" row to add to the table data
In a Retool table, all the data is displayed in the component state as an array or objects. Where the header row is created by the table's code grabbing the keys from one of the objects. With the rest of the rows below it being the values from each row's object.
As Kabirdas explains in that post which you linked. He first grabs the array of data from the table/query source, then uses a Javascript code block to manipulate the data to remove from the front of the array using .shift() and in your case you would be doing the opposite.
Due to some quirks of computer science, it is tricky to add data to the beginning of a data structure but easy to add to the end. We might need to take the array and reverse it, so we can "add the synthetic row to the end" and then un-reverse it. For this we might need to create a row object that has keys that are the same as the column header, but the values will be what is displayed in the row.
But I believe that will lead to the column headers being the top most as it is built by the table automatically, and the data from the object you are adding as the second to the top row. (top most header will always be built by the table component in Retool based on row-obj keys)
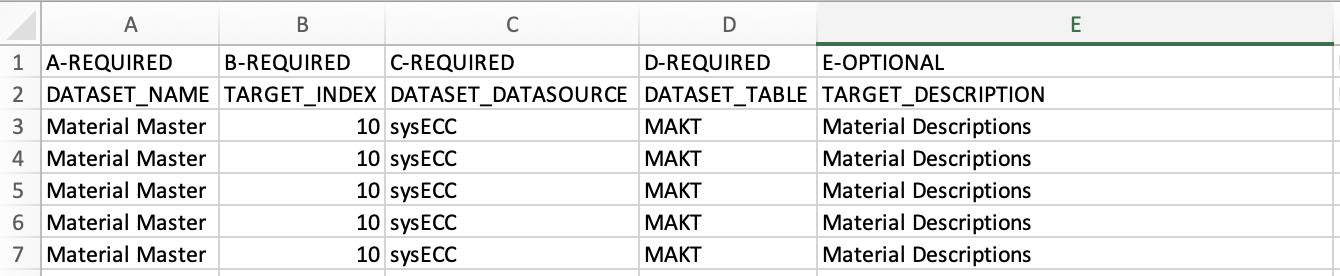
Thank you for your analysis and response! The extra row needs to be above the actual data column headers (DATASET_NAME, TARGET_INDEX, etc) with column names like REQUIRED and OPTIONAL.
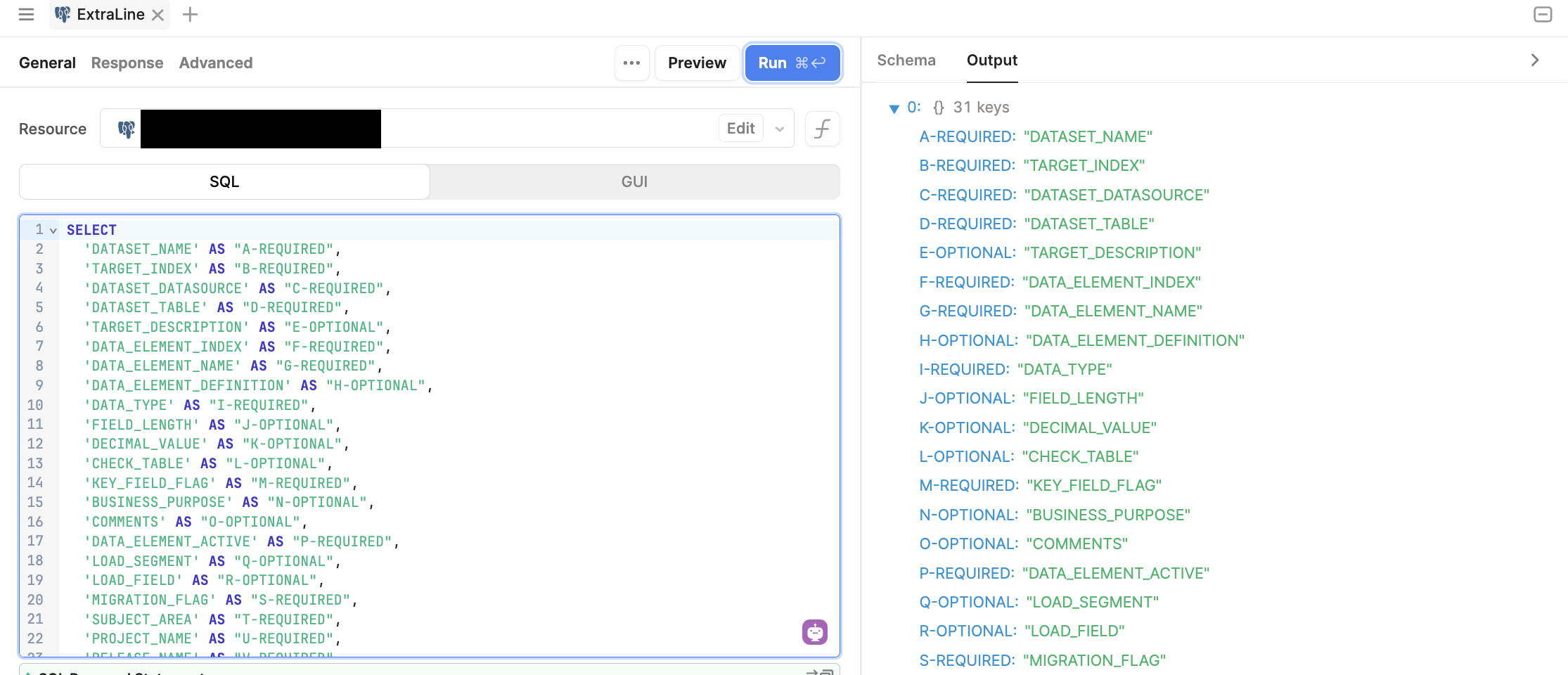
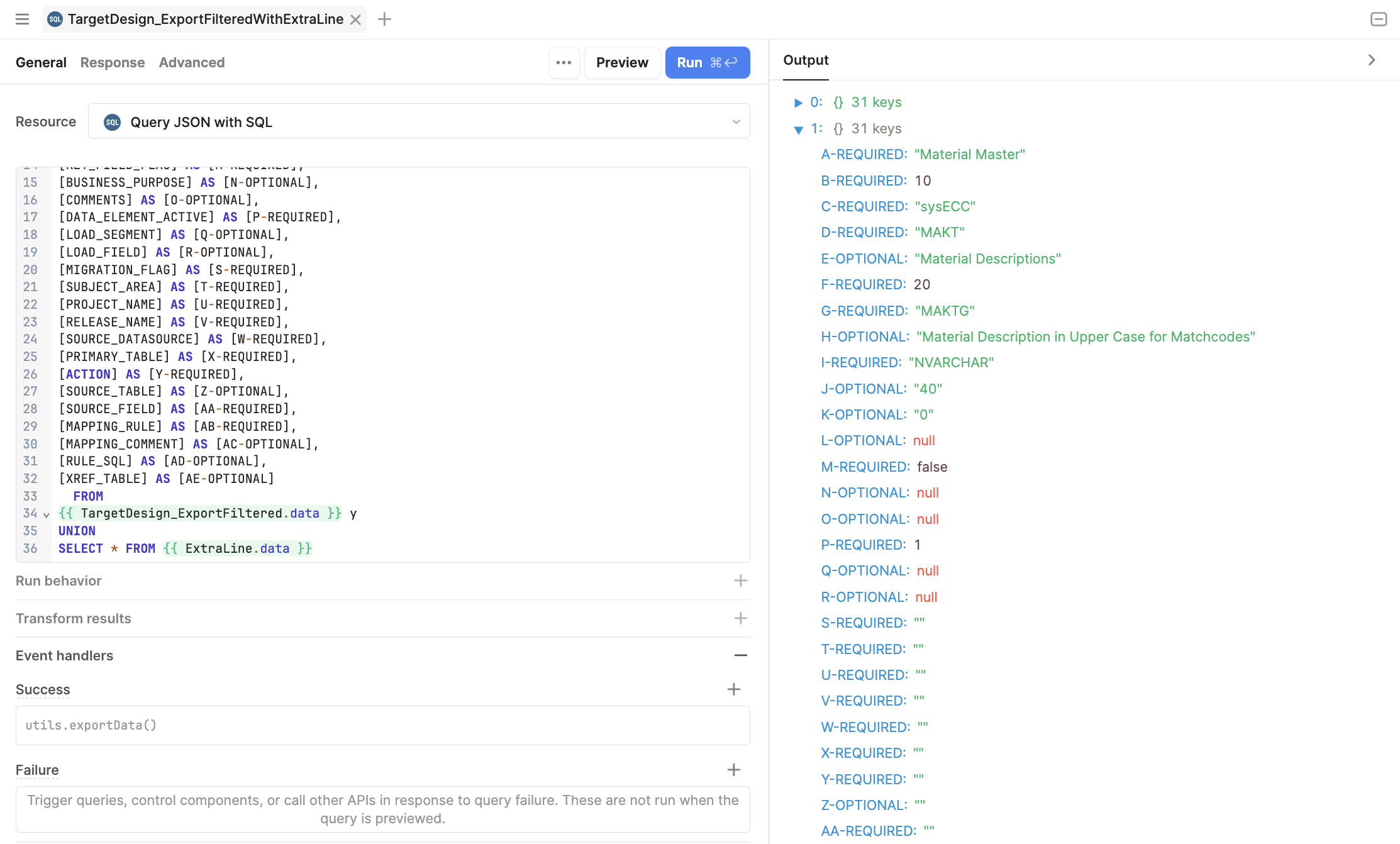
Your response gave me an idea for another approach... where I UNION the actual data with a dummy row containing strings of the data column names aliased as A-REQUIRED, B-REQUIRED, C-OPTIONAL, etc and those aliases become the first row in the export. Then the actual data query has to have matching aliases to satisfy the union.