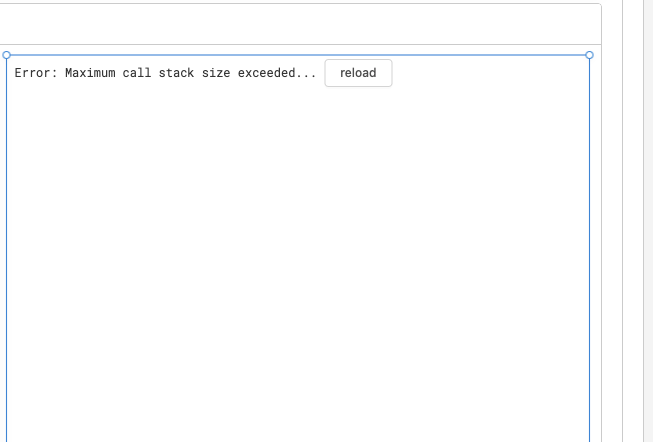
I've linked my S3 server to get files and use the PDF previewer component but occasionally, I get this weird error of "Error: Maximum call stack size exceeded..." but the file size is ~10MB only.
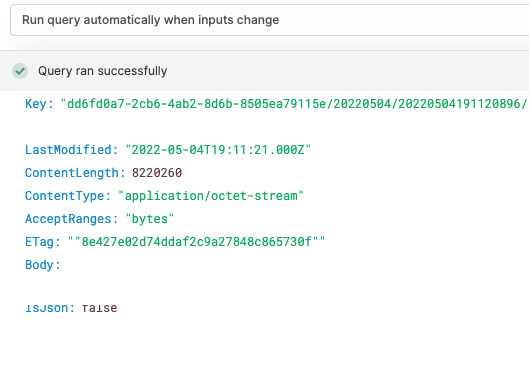
Sharing the screenshot that the underlying query is successful but the PDF previewer shows an error. The previewer is mapped to the data source {{ReadFileFromS3.data.Body}} .
Happy to help! Hmm you know that's really strange it's doing that. Is that happening only for larger files? Are you able to successfully load any PDFs?
Ah I see is the differentiating factor of theses files only the size? Do you have a work-around in place for those? I'm unsure how else to get those going apart from attempting to put together a custom component to view the PDF file. I'll check-in with my teammates and get back to you. Hang tight
Unfortunately it seems like this is intentional but we're unsure as to what capacity in terms of file size. We're attempting to stabalize the browser and not crash with enormous files however I understand that this isn't exactly what you'd like from this component. It would be most helpful if the error would be a bit more descriptive however
Hey @Pawan,
Been a while since I worked on this but I did see your update and got to know it is as intended. Still a bit surprised that a 20 MB file would cause this and that too intermittently not consistently. Anyway, I've asked my users to simply download the file and view it in the browser whenever such an error is seen on the PDF previewer.
If the component updates to make the error better or to process bigger files, would be kind enough to let me know, please?
Hey @Kabirdas,
Tried that but somehow the pre-signed URL didn't allow previewing the file.
I could open the file in a browser with the same URL though. Didn't explore further, but since the file is browseable, it must be something that the PDF component expects which I'm not providing.
I see, it might be worth checking your browser console to see if there are any errors there, if you're interested and haven't already.
One that can come up is a CORS error (see our documentation here on setting CORS for S3) but if you're seeing something else that could be useful information as well.