How I got here:
I am processing reports that arrive in excel via a Retool Workflow. That workflow data is then loaded into a table in my app for further updates / processing. Related Topic
Goal:
Save all data from the app table and any edits / updates made by the user into a retool database table using the IDs for tag (mapped) columns instead of the labels that the user sees.
Steps:
User selects an Excel file to import / process
The file is uploaded to Retool storage
My workflow parses the data in the spreadsheet, returns it, and it is loaded into a table in my app
User updates fields in the table
User clicks a Save button and ALL rows in the table with their changes are saved to a retool database table using the IDs for the various tag formatted and mapped columns
Details:
There are a couple things about this that are a little unique (or maybe not? ). First, I need every row in the table to get added to the retool database table, regardless of whether or not anything has changed. If any column HAS changed, I need the updated value inserted.
I am very familiar with writing data to tables from Retool but where I'm a bit stumped is how to get the IDs for the tag columns and not the labels (my retool database table has the ID columns). I am pretty sure this is going to take a transformer / custom mapping via JS type of solution to manage both the original data and the changesetarray but I'm just not having any luck getting that working on my own. I am open to whatever suggestions you might have; including breaking this up into a couple steps if necessary.
Screenshots:
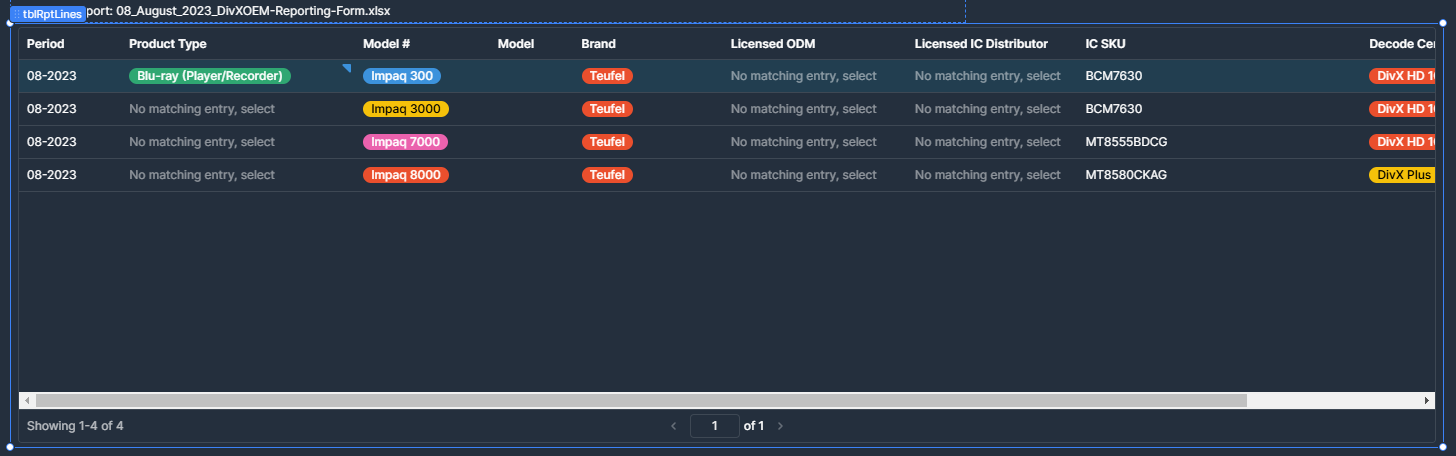
The table in question with a single row updated
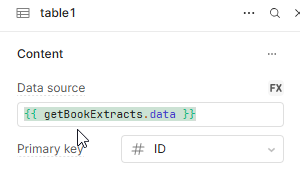
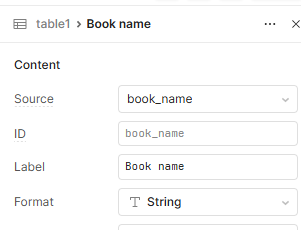
The tag mapping for the updated column (Product Type). I have the id I need in the caption field because that is the only way the column will reliably match against the data from the workflow. I have several columns in this table setup the same way. This is a data issue, not a Retool issue; this has worked for me before:
I would create a transformer to format the data. Add a similar JavaScript transformer in Retool to generate the final dataset before inserting into the database.
const originalData = table.data; // Original table data
const changes = table.changesetArray || []; // Only contains edited rows
// Convert changeset into an object for quick lookup
const changesMap = changes.reduce((acc, row) => {
acc[row.id] = row; // Using the row ID as the key
return acc;
}, {});
// Process all rows, replacing tag-mapped columns with their ID values
const finalData = originalData.map(row => {
const updatedRow = changesMap[row.id] || row; // Use edited row if available
return {
id: updatedRow.id, // Keep the existing row ID
period: updatedRow.period,
product_type_id: updatedRow.productType?.caption || null, // Use ID from caption
model: updatedRow.model,
brand: updatedRow.brand,
licensed_odm: updatedRow.licensedODM,
licensed_ic_distributor: updatedRow.licensedICDistributor,
ic_sku: updatedRow.icSKU,
decode_cert: updatedRow.decodeCert
};
});
// Return the final transformed array
return finalData;
Then you just need to have an upsert query linked to your table and the transformer data.
One thing I can never keep straight is when I need handlbars and when I don't. In your example, you don't have them around the initial const statements but until I add them I don't get anything back in the preview. I'm working my way through the mapped columns to be sure I've got all the right values lined up. Dealing with spaces in column names is also fun... Thanks again for the help; I'll report back here once I've had a chance run this in full.
Yes! The famous curly braces {{}}. You are correct, I should have used them
eg const originalData = {{ table1.data}} as it is a Transformer. I believe in general we use them outside of JS Queries and Event Handlers when we choose Runs script.
In a Transformer: const originalData = {{ table1.data}}
In JS areas such as JS Queries and Event Handlers const originalData = table.data
Also in any component fields such as a table you can use JS when you wrap it in {{}}.
Hmm, for column names and table names (when you can control this) it is a best practice to use snake_case for Retool which is PostgreSQL under the hood. Unless you just mean the labels though I think Retool by default does a good job converting your table snake-case columns to Capitalize Each Word.
So of course removing the spaces from column names has turned into a whole other rat's nest of data cleanup. le sigh. I am still working on this; will report back once I have the data formatted correctly.
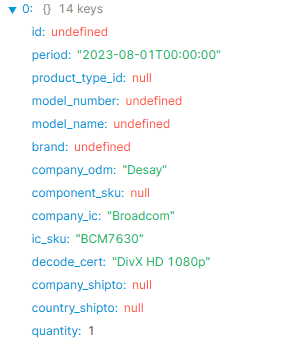
I'm getting some different behavior now but it's inconsistent and I'm sure something I'm missing in the JS function. Sometimes, the data comes back from the function as undefined:
Sometimes it will come back from the function with the right text values, but not the mapped IDs (captions) for the columns:
I did go through and fix all my columns to remove spaces, etc. It is matching values for the mapped columns in the table appropriately. Here is the current javascript function
const originalData = {{tblRptLines.data}}; // Original table data
const changes = {{tblRptLines.changesetArray}}|| []; // Only contains edited rows
// Convert changeset into an object for quick lookup
const changesMap = changes.reduce((acc, row) => {
acc[row.id] = row; // Using the row ID as the key
return acc;
}, {});
// Process all rows, replacing tag-mapped columns with their ID values
const finalData = originalData.map(row => {
const updatedRow = changesMap[row.id] || row; // Use edited row if available
return {
id: updatedRow.id, // Keep the existing row ID
period: updatedRow.period,
product_type_id: updatedRow.product_type?.caption || null, // Use ID from caption
model_number: updatedRow.model_number?.caption,
model_name: updatedRow.model_name,
brand: updatedRow.brand?.caption,
company_odm: updatedRow.company_odm,
component_sku: updatedRow.component_sku,
company_ic: updatedRow.company_ic,
ic_sku: updatedRow.ic_sku,
decode_cert: updatedRow.decode_cert,
company_shipto: updatedRow.company_shipto,
country_shipto: updatedRow.country_shipto,
quantity: updatedRow.qty
};
});
// Return the final transformed array
return finalData;
First, thanks for your patience; I've been working on some other time-sensitive projects and had to put this aside for a couple days. I'm back to working on this, and I'm still getting undefined data for columns that should be showing an ID or text value. BUT I think the issue is mine here. I believe i've probably got your function in the wrong spot or being evaluated at the wrong time during the workflow . I'm sure this is mea culpa, but if you'd be willing I'd love some guidance on the best place to put the transformer code. Here's what the general process looks like:
User enters some report details that are saved to a Retool database table report_temp - I need the ID of the report from this table for the next few steps.
Once that report has been created, it activates the import button where they select the file from the customer.
Once they select the file, it's uploaded to storage and parsed by a workflow I've built using python pandas to do some basic data extraction and transformation.
The cleaned data is set as the data source for the tblRptLines component.
The data from the workflow loads just fine in the table, and several of the columns are editable (hence using the tags to look up the relevant data from other tables ).
The user clicks a Save button and the data from the tblRptLines component is bulk inserted into a Retool database table reportline_temp referencing the reportID from step 1 (it's stored in a variable that gets updated when they save the report details).
I'm realizing I may have a couple other hurdles to cross in getting the report lines table to act properly without a Primary Key (these are net new records, so there's no PK column and if I add a placeholder, I can't edit the other values anymore). Plus getting the variable for the reportID to insert correctly means I can't bulk update with the tblRptLines data - at least not easily. I may have worked myself into a corner here. lol. Thanks again.
Hi @Adam_Cogswell,
Sounds a little complex but fun! Maybe the best is to share a loom or more screenshots. I would like to see the steps and in each one if you are getting the data needed at the right time. Sometimes working between an app UI and a workflow can get tricky.
Depending on how you are entering the new records you can get an insert query for example to return the PK id.
Hey @Adam_Cogswell - just jumping in here. Maybe I'm misunderstanding, but shouldn't it be sufficient to use item.producttypeid as the mapped option Value?
The data coming in from the workflow is in columns that are mapped (tags) to other database tables in my app. If I use the appropriate id column for the value, none of the mapped values ever match, even if they're precisely the same as the label value.