I wanted to know if anyone has any experience with accessing the data residing in an IBM i server
Options I see:
1 - I have looked in creating Rest APIs but the web server is not accessible over the internet
2 - I have also looked into using JSON but even though I can do it with an IBM tool called IBMi Access I don't think there is any driver available
Are you running a cloud or self-hosted instance? And is your server accessible via company intranet or a VPN? In the absence of a built-in resource connector, I usually recommend a REST API as a workaround, but it sounds like that might not be possible.
Thank you for reaching out and I'm sorry for taking such a long time to reply.
My server is accessible via VPN only and I have been running a Retool cloud instance. I am thinking that I should perhaps give it a try with the self-hosted instance and access the database using JDBC.
What do you say? Would this work?
It worked.
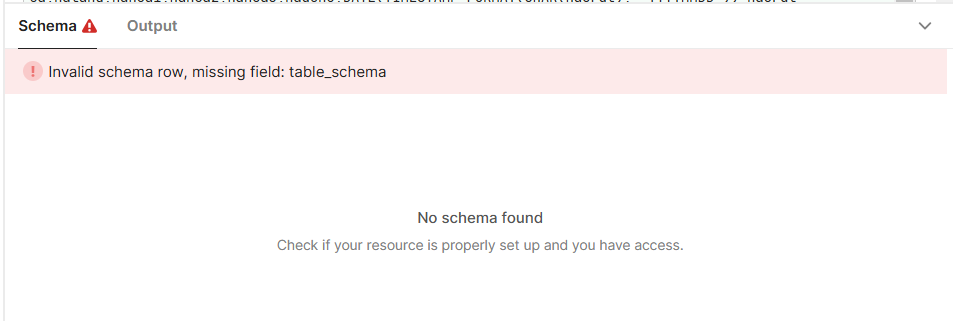
I'm struggling however with the fact that the database schema keeps loading. This is a huge database with thousands of files and fields.
Is there anything it can be done to not load the schema?
Glad to hear it! I assume you ended up using a JDBC driver? I know it's possible to prevent introspection for GraphQL resources, but I can't currently think of a more generic solution for preventing the schema from loading.
As for this schema thing, I tried to just limit it the schema reading to a fewer number of records. I mean, this is the SQL for the schema that was put forward by default:
SELECT
c.column_name as column_name,
c.data_type as data_type,
c.table_name as table_name,
c.table_schema as table_schema
FROM
information_schema.columns c
JOIN (
SELECT
table_name
FROM
information_schema.tables
WHERE
table_schema != 'information_schema'
LIMIT
3000
) AS t ON t.table_name = c.table_name
ORDER BY
c.table_name
Forget what I said when having the schema erroring out was not a problem. It is since when that happens it seems like I cannot get the server jobs to start.
This is not easy to deal because it takes really a long time to run.
What I would like would be that the schema would not be triggered so many times. I don't know how to explain it, I guess.
If I'm understanding correctly, the schema should only load when you're actively creating or editing a query. It shouldn't have any impact upon the overall performance of your production applications. is that right?
Yes you are correct.
It's just that when I'm in the process of development it is very inconvenient having to wait 30 minutes every time I edit the query. Sometimes a small change that would take 1 minute to do and test turns out to be much longer.
It would be excellent if it would be possible to have a setup somewhere preventing this from happening all the time.
I agree! It seems almost necessary if the alternative is having to wait ~30 minutes. Other resource connectors come with the option to disable introspection, so it's a feasible ask on top of being reasonable.
I'll talk to the team so see what kind of fix we might be able to roll out and will provide an update here as soon as possible!