Good to know! Will bring this back up with engineering to take another look and continue to pass along updates here.
Thanks for the update @mfroca_vita!
Good to know! Will bring this back up with engineering to take another look and continue to pass along updates here.
Thanks for the update @mfroca_vita!
Hey @mfroca_vita!
After doing some digging it looks like this may be a separate issue, could you try finding the request in the network tab of your browser console and post a screenshot of what you're seeing in the "Preview" of the request with all the fields expanded?
I'm also curious to know if you're seeing the file get uploaded to S3, or if it's not going through at all.
Hi there,
I'm experiencing the same error message. In my situation I'm trying to receive a file from Google Cloud Storage (the file is ~50MB). This request used to work ~10 days ago and I only noticed today that it's not working anymore. I haven't changed or accessed retool in that time.
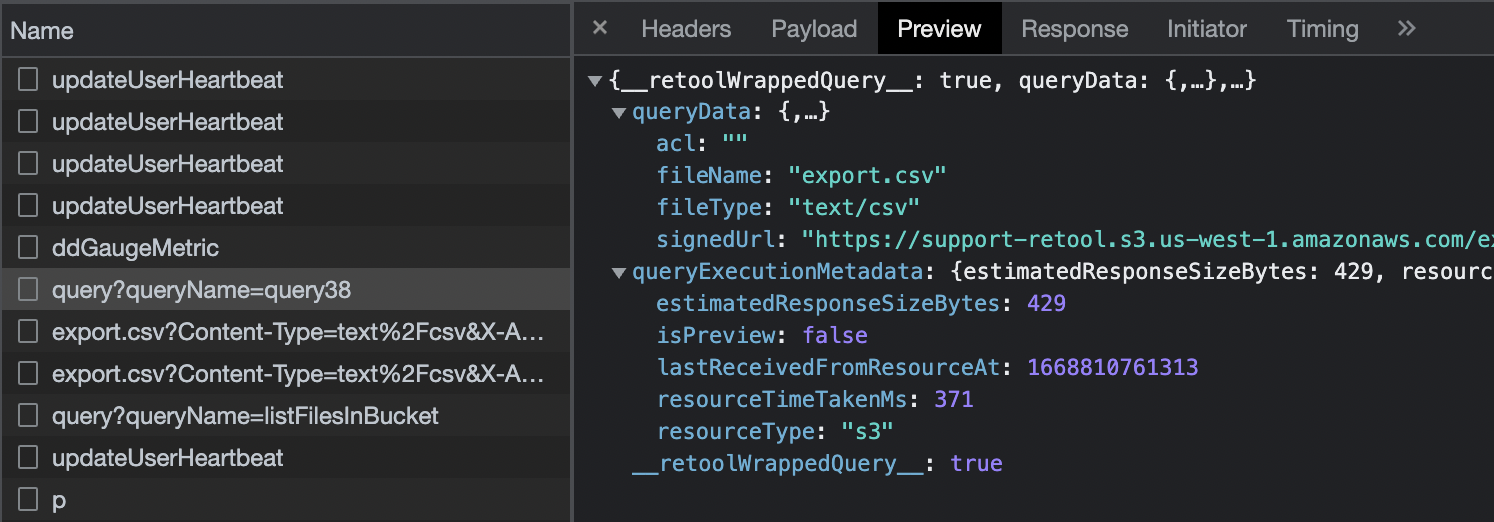
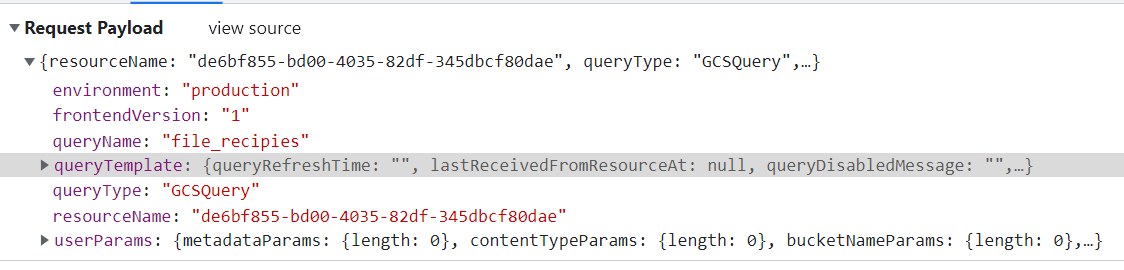
Request:
Response
{
"error": true,
"message": "Result exceeded maximum size of 100 MB",
"queryExecutionMetadata": {
"estimatedResponseSizeBytes": 65,
"resourceTimeTakenMs": 1710,
"isPreview": true,
"resourceType": "gcs",
"lastReceivedFromResourceAt": 1671263328232
},
"source": "resource"
}
Here some more context for PM/devs
I used to load the same amount of data from bigquery which worked. Overall it was slower than the file retrieval. In my app I'm doing filtering and would have to run the query again. To save roundtrip time and data charges I'm doing the filtering on the client side by using javascript to iterate over the file. This is fast and works well for easy filtering. In an ideal world I can compress the data on the cloud storage side, download it in the browser and uncompress it there. That should further reduce 50MB to 3MB which speeds up the download even further. Only issue was that I didn't find an uncompress library for gzip or zip in javascript that I could use.
Hey @alien, sorry about the late reply but thanks for flagging this!
Did some digging with the team and as for 2.106.0 (which released late Tuesday of last week) we started more strictly enforcing the 100MB response limit for queries in order to help improve the stability of our backend resource connectors.
The encoding of the file can in some case increase the response size, but the fact that the file is only 50MB and you're seeing an estimatedResponseSizeBytes of only 65 does seem a bit odd though.
Are you using the "Read a file from GCS" action or the "Generate a signed url" action to get your file?
Facing the same issue, I'm trying to pull user data from MongoDB resources.
error:true
message:"Result exceeded maximum size of 100 MB"
estimatedResponseSizeBytes:65
resourceTimeTakenMs:8621
isPreview:false
resourceType:"mongodb"
lastReceivedFromResourceAt:1671615654055
source:"resource"
Thanks for the added context @naveenrajv!
We were able to reproduce the behavior with GCS and the team is looking into a fix to be published after the holiday which we can update you all on here. Do you know the approximate size of the return value on your MongoDB query? Was it similarly large (e.g. ~50MB)?
Yes, I'm using the "Read a file from GCS" option.
Hi @naveenrajv!
This should be fixed as of version 2.107.1, can you let me know if you're still seeing it on your end?
I trying to fetch 15k+ user profile information from MongoDB. I'm not sure about the exact weightage of the data.
Hey @naveenrajv!
Sorry about the late reply here. Does the query work if you select fewer rows?
This might give a good way to estimate the response size for all 15k+ by checking the estimatedResponseSizeBytes of the smaller query.
If the response size itself happens to actually be over 100MB you might also try using server-side pagination or a JS query that batches your requests and then returns them all together (with a pattern like this).
Let me know what you find and we can go from there!
Did this get a resolution, I have just built an app where an internal team can download file from S3 (one at a time). Some work some come back with the 100MB limit error, this has just gone live for a campaign and I need this functionality urgently, is there a way to increase size to over 100mb?
Hey @Guy_N!
Right now the 100MB limit is intentional, it seemed like there was an issue specific to GCS where files were being estimated as being larger than they actually were but that should be fixed now.
What are the size of the files you're retrieving from S3? If they are exceeding 100MB you might try downloading it directly from your browser with a fetch request in a JavaScript query.
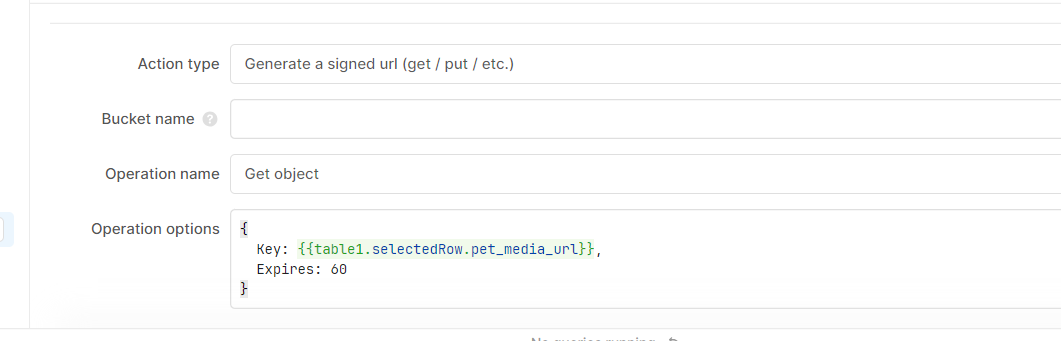
To do that, you can generate a signed URL with the S3 resource. You'll want the "Operation name" set to Get object:

From there, you can then use that to make the request and download the data with the downloadFile util (docs here).
return fetch(get_signed_url.data.signedUrl)
.then(response => response.arrayBuffer())
.then(arrayBuffer => utils.downloadFile(arrayBuffer, 'your file name', 'your file type'))
Let me know if that works!
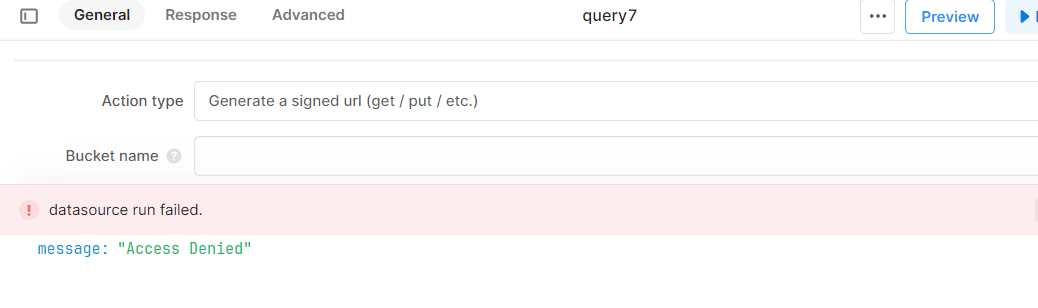
Hey thanks for your reply. I have tried something similar I believe, but unable to get it working..
See screen shots. Any ideas?
error I get is this.
It is NOT a public bucket, I have a IAMS and role attached it has get put access...not sure what else to do here...
any help greatly received.
Hmm... if you use a "Read a file from S3" Action type with that same key do you also get an Access Denied error?
It may be good context to see more about how you've configured authentication on your S3 context as well if the correct permissions aren't getting passed.